Introducing InfluxDB 3.0: Available Today in InfluxDB Cloud Dedicated
By
Rick Spencer
updated October 13, 2023
Product
Company
Navigate to:
It’s been literally years now that I have been first tangentially, and then intimately involved with the project that has become InfluxDB 3.0. I started using it so early that one of the DataFusion upstream developers literally calls me “User0” … a moniker of which I am not-so-secretly proud. Now, after those years of development, I am really happy to have a small role in sharing the work of the InfluxData team, and the wider Apache Arrow community with the world, as we roll out InfluxDB 3.0, and I sincerely expect that both existing and new users will find this release very useful.
Introducing InfluxDB 3.0: the evolution of InfluxDB IOx
As of today, InfluxDB 3.0 now serves as the foundation for all InfluxDB products, both current and future, bringing high performance, unlimited cardinality, SQL support, and low-cost object store to the InfluxDB platform for the first time. Developed in Rust as a columnar database, InfluxDB 3.0 introduces support for the full range of time series data (metrics, events, and traces) in a single datastore to power use cases in observability, real-time analytics, and IoT/IIoT that rely on high-cardinality time series data.
InfluxDB 3.0 is now available in InfluxData’s cloud products: InfluxDB Cloud Serverless (our fully managed, elastic, multi-tenant database) and InfluxDB Cloud Dedicated (a fully managed, single tenant version of InfluxDB) announced today. Stay tuned for our self-managed product coming later this year:
- InfluxDB 3.0 Clustered: The evolution of InfluxDB Enterprise.
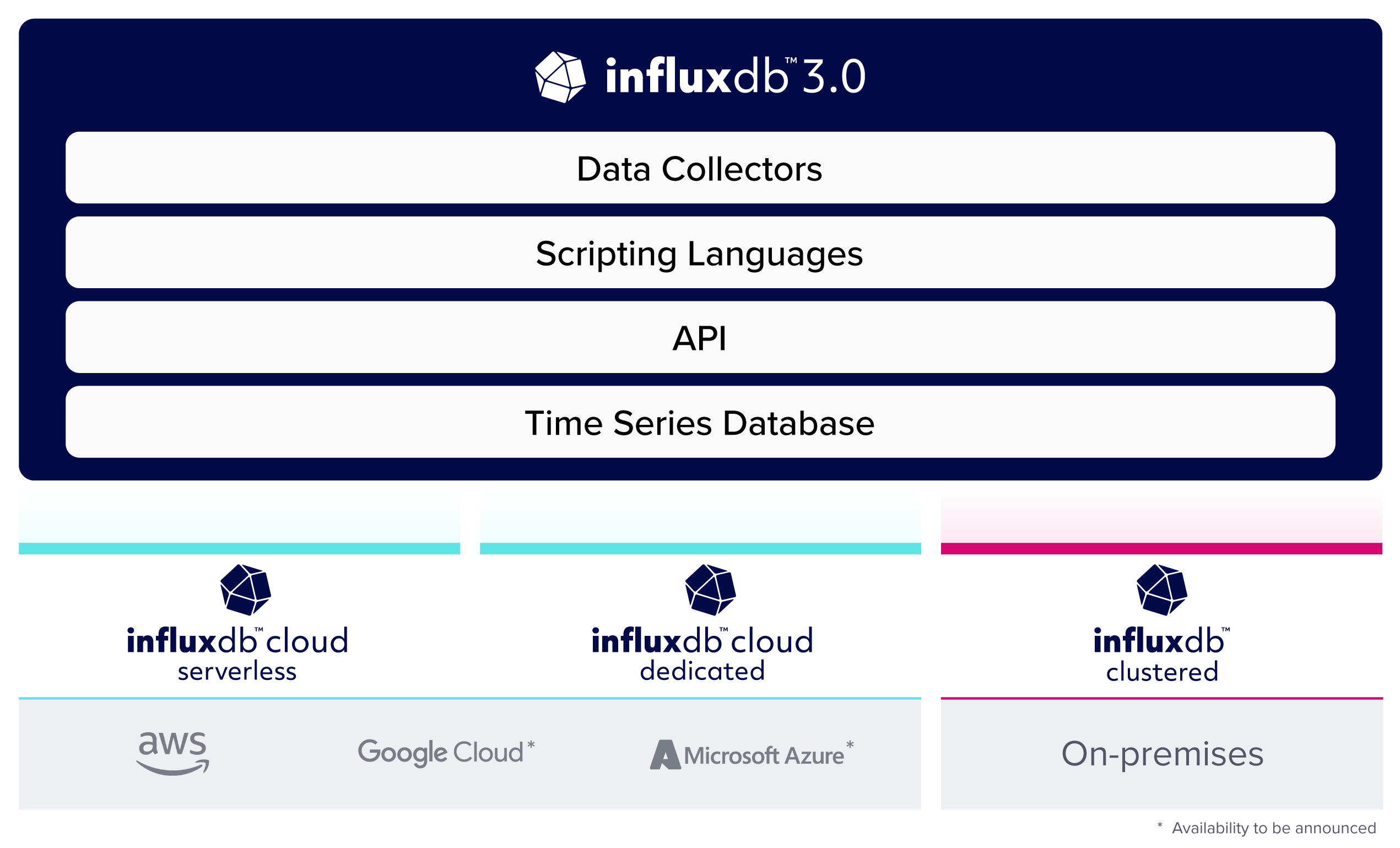
InfluxDB Cloud Dedicated now Generally Available
InfluxDB Cloud Dedicated is an ideal solution for customers working with large data sets, who require the reassurance and security of data isolated in a dedicated, single tenant cluster. It offers custom configuration and enhanced security options (including Enterprise SSO, private connectivity, and Role-Based Access Controls) and a capacity-based pricing model.
Optimizing InfluxDB 3.0 for…
If you fall into one of the following categories, we think you’ll want to check out InfluxDB 3.0:
-
You’re an existing InfluxDB OSS user — InfluxDB 3.0 is likely to run your existing workload faster and cheaper with minimal changes. Plus, it gives you access to new functionality and the ability to use InfluxDB with more, different kinds of data.
-
You’re not an existing InfluxDB user, but you need an analytics database with real-time capabilities for a large volume of data, or you’re struggling to get the most out of your existing analytics database, then InfluxDB 3.0 will fulfill your needs.
Performance with unlimited scale
InfluxDB 3.0 goes beyond InfluxDB 1.x and 2.x in some important ways. Enhancements to InfluxDB 3.0 bring InfluxDB to the forefront of analytics databases, allowing developers to ingest and query full fidelity time series data of all types, in real-time at scale, and with no compromises.
InfluxDB 3.0 now supports unlimited cardinality, which expands the use cases for InfluxDB to any time-stamped data. Unlike other analytics databases, InfluxDB 3.0 features massive gains in ingest performance, scalability, resilience, and efficiency, even as data complexity and cardinality increase.
For example, compared to previous versions of InfluxDB, the new InfluxDB 3.0 delivers performance gains in the following areas:
-
100x faster queries across high cardinality data, delivering real-time query response
-
10x ingest performance to ingest, store, and analyze billions of time series data points per second without limitations or caps
-
10x greater data compression from using the Apache Parquet file format, which is designed for efficient data storage and retrieval
InfluxDB in the Arrow ecosystem
We developed InfluxDB IOx – and by extension, InfluxDB 3.0 – around the Apache Arrow Project, an open source, in-memory specification for columnar data, which is the gold standard for high performance computing for analytics use cases. We built the InfluxDB IOx engine on Arrow to take advantage of its performance and ecosystem.
InfluxDB 3.0 now uses the Apache Parquet file format for storing data. Parquet’s compression achieves orders of magnitude gains in efficient use of disk space. Having the ability to store more data in less space is important for controlling costs, as well as overall efficiency for large analytic workloads.
Leveraging Apache DataFusion, InfluxDB 3.0 has a modern and blazing-fast SQL implementation. Because it is based on open standards, you can bring your existing SQL knowledge and tools to your InfluxDB experience. We even enhanced DataFusion’s SQL dialect to include key time series functions.
We also brought InfluxQL, InfluxData’s time series query language, forward into DataFusion. Now, InfluxQL runs faster than ever.
At InfluxData, we believe in the Apache Arrow ecosystem. True to our open source ethos, our engineers made significant contributions to upstream Arrow projects to ensure that performance and capabilities meet the standards of InfluxDB and its dedicated user-base. The introduction of InfluxDB 3.0 brings time series data to the Arrow ecosystem for the first time, allowing analytics workloads to more easily incorporate times series data. This ensures OSS contributions are easier to build and integrate.
Get started with InfluxDB 3.0 today
To get started with InfluxDB 3.0, try InfluxDB Cloud Serverless, or request a proof of concept for InfluxDB Cloud Dedicated today.
