Less Friction, More Control: Here's What Shipped in Q1
By
Ryan Nelson
Apr 08, 2026
Product
Developer
Navigate to:
Our Q1 momentum has been focused on a simple goal: making InfluxDB easier to operate, easier to scale, and faster to put to work.
Across Telegraf, InfluxDB 3, and our managed offerings, these updates reduce friction in how teams collect, process, and scale time series workloads.
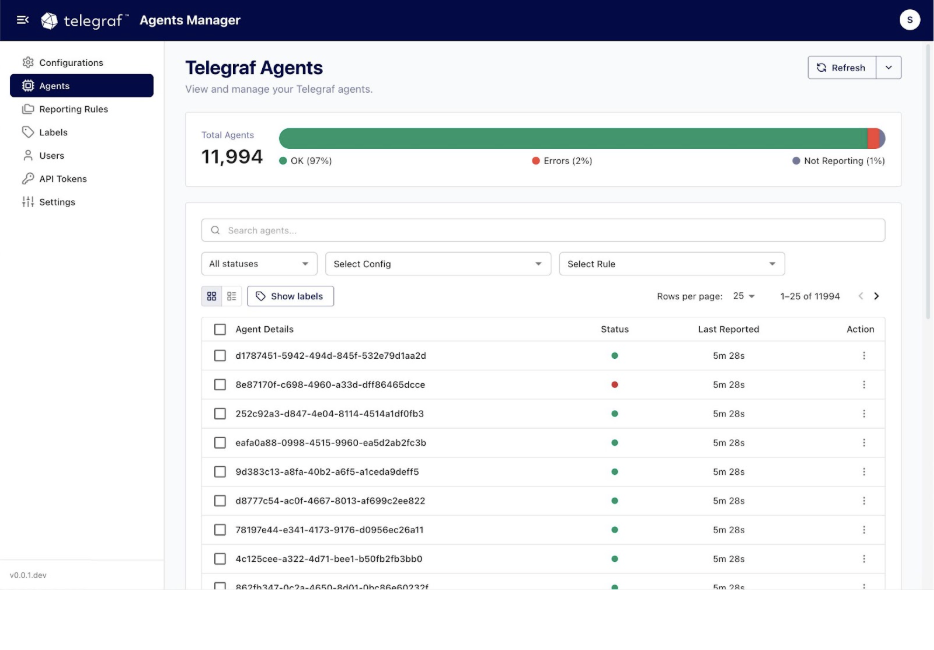
Telegraf Controller enters beta
Telegraf is already a powerful way to collect metrics, logs, and events across environments. At scale, the challenge shifts from collection to control. Telegraf Enterprise is designed to solve that problem.
At the center is Telegraf Controller, a control plane that gives teams centralized configuration management and fleet-wide health visibility. The beta includes major capabilities such as API authentication, API token management, user account management, multi-user support, role-based access control, global settings management, and expanded plugin support in the visual config builder.
Feedback from early users is shaping the road to general availability, with enterprise licensing, enforcement, audit logging, and federated identity management next on the roadmap. Sign up to join the beta.
InfluxDB 3.9 adds more operational control
Last week’s release of InfluxDB 3.9 is focused on making the platform easier to run at scale, with improvements aimed at predictability, visibility, and day-to-day management. The release expands CLI and automation support for headless environments, improves resource and lifecycle management, and adds clearer visibility into access control and product identity across Core and Enterprise deployments. These are the changes that matter in production: fewer rough edges, stronger operational clarity, and better control as workloads grow.
InfluxDB 3.9 Enterprise also includes a new beta performance preview for non-production environments. This optional preview includes optimized single-series queries, reduced CPU and memory spikes under load, support for wider and sparser schemas, and early automatic distinct value caches to reduce metadata query latency. These features are not yet recommended for production, but they give customers an early look at capabilities planned for future releases and a chance to help shape what comes next.
Processing Engine updates make InfluxDB 3 easier to operationalize
The Processing Engine remains one of the most powerful parts of InfluxDB 3 because it allows teams to run logic directly at the database. Users can transform data on ingest, run scheduled jobs, or serve HTTP requests without adding external services or layering on more pipeline complexity.
This quarter, we continued to expand both the engine itself and the plugin ecosystem around it. The latest plugins make it easier to get data into InfluxDB 3 from more sources:
- The Import Plugin provides a simpler path for bringing data from InfluxDB v1, v2, or v3 into InfluxDB 3 Core and Enterprise, with support for dry runs, progress tracking, pause and resume, conflict handling, and flexible filtering.
- New MQTT, Kafka, and AMQP subscription plugins help users ingest streaming data directly from external message brokers.
- The new OPC UA Plugin gives industrial teams a more direct path to data from PLCs, SCADA systems, and other OPC UA-enabled equipment.
We also made important improvements to the Processing Engine itself:
- New synchronous write controls give plugin authors more flexibility over durability and throughput.
- Batch write support improves efficiency for high-volume workloads.
- Asynchronous request handling keeps status checks and control operations responsive during long-running jobs.
Together, these updates make the Processing Engine a more practical way to build and operate real-time data pipelines directly inside InfluxDB 3. Check out our docs to learn more.
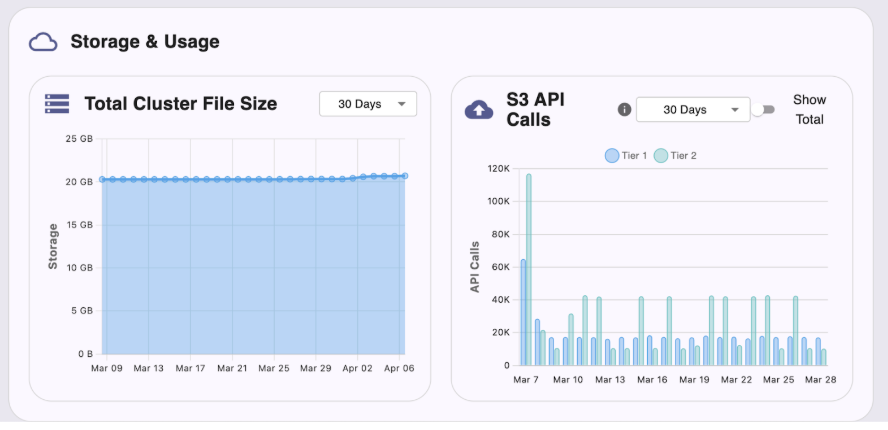
Better visibility for Cloud Dedicated customers
As teams run production workloads on Cloud Dedicated, understanding how the system is being used becomes just as important as performance itself.
This quarter, we introduced:
- Query History (GA) for troubleshooting, performance analysis, and deeper insight into query activity.
- S3 API dashboards (Tier 1 and Tier 2), including monthly usage visibility.
These updates give teams better visibility into system behavior, usage patterns, and a faster path to understanding activity across the environment. Detailed docs here.
InfluxDB Enterprise 1.12.3 delivers efficiency gains for v1 environments
For teams needing more performance and running large-scale v1 Enterprise environments, InfluxDB Enterprise 1.12.3 is now available with substantial improvements in efficiency and reliability:
- 100x faster retention enforcement for high-cardinality datasets
- 30% lower CPU usage during compaction
- 5x faster backups with configurable compression
- 3x less disk I/O during cold shard compactions
These improvements make Enterprise v1 clusters more efficient, more predictable under load, and more cost-effective to operate. Read the release notes.
Amazon Timestream for InfluxDB adds a new scale tier and simple upgrade path
InfluxDB 3 on Amazon Timestream for InfluxDB now supports clusters of up to 15 nodes, giving customers a new scale tier for more demanding real-time workloads.
This expanded tier improves query concurrency, increases ingestion throughput, and provides stronger workload isolation across ingestion, queries, and compaction. For teams running high-velocity, high-resolution data in production, that means more headroom to scale without compromising real-time performance.
Customers can also seamlessly migrate from InfluxDB 3 Core to InfluxDB 3 Enterprise, making it easier to move into this higher-performance tier without a manual architectural overhaul or data loss. The new 15-node option is available for InfluxDB 3 Enterprise in all AWS regions where Amazon Timestream for InfluxDB is offered. Read more here.
Looking ahead
Taken together, these updates are about helping teams do more with less friction: move data faster, operate with more confidence, and scale time series workloads without losing control. As operational data becomes more central to modern systems, we are continuing to invest in the infrastructure that turns that data into action across edge, cloud, and distributed environments.
