Querying Arrow tables with DataFusion in Python
By
Anais Dotis-Georgiou
Oct 23, 2023
Developer
Navigate to:
InfluxDB v3 allows users to write data at a rate of 4.3 million points per second. However, an incredibly fast ingest rate like this is meaningless without the ability to query that data. Apache DataFusion is an “extensible query execution framework, written in Rust, that uses Apache Arrow as its in-memory format.” It enables 5–25x faster query responses across a broad range of query types compared to previous versions of InfluxDB that didn’t use the Apache ecosystem. Apache Arrow is a framework for defining in-memory columnar data. For queries, InfluxDB v3 leverages the SQL DataFusion API and DataFusion offers a Python DataFrame API as well. In this tutorial we’ll learn how to:
- Query and get data in pyarrow table format with the InfluxDB v3 Python Client Library.
- Convert the pyarrow table to Pandas and do some transformations.
- Save the table as a Parquet file.
- Load the Parquet file back into an Arrow table.
- Create a DataFusion instance and query the Parquet data with SQL
Pandas 2.0
A Table is equivalent to a Pandas DataFrame in Arrow. If you’ve followed the news around Pandas 2.0, you know that it supports Arrow and NumPy as the backend. However, you have to explicitly chose Pandas 2.0 by specifying dtype_backend argument to any read_* method in order to use it. Here’s a performance comparison between Pandas 1.0 and Pandas 2.0.
You can query and write Pandas DataFrames to InfluxDB v3. However, working with Arrow tables and DataFusion offers performance benefits. For example, PyArrow tables use all cores, while Pandas just uses one. Additionally, querying Arrow tables with SQL is easier than performing transformations with Pandas for users with SQL backgrounds.
Querying, converting, and transforming Arrow tables with DataFusion and SQL
First, we’ll query and get data in pyarrow table format with the InfluxDB v3 Python Client Library. After importing your dependencies, instantiate the client and query your data.
from influxdb_client_3 import InfluxDBClient3
import pandas as pd
import datafusion
import pyarrow
client = InfluxDBClient3(token="[your authentication token]",
host="us-east-1-1.aws.cloud2.influxdata.com",
database="demo")
query = "SELECT * FROM \"cpu\" WHERE time >= now() - INTERVAL '2 days' AND \"cpu\" IN ('cpu-total')"
table = client.query(query=query)
print(table)
# Alternatively use the pandas mode to return a Pandas DataFrame directly.
# pd = client.query(query=query, mode="pandas")
# pd.head()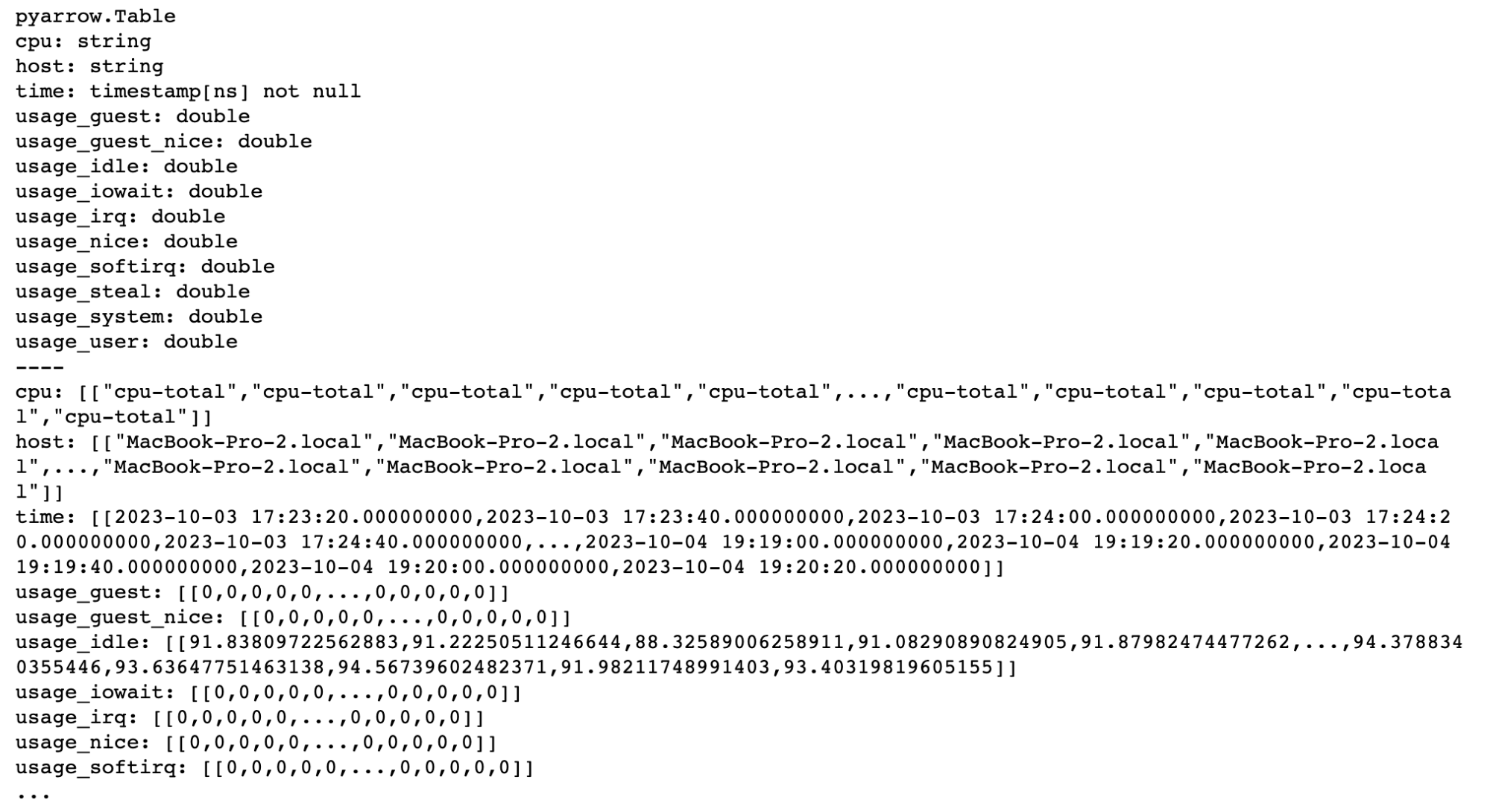
Next, we’ll use DataFusion to convert an Arrow Table to a Pandas DataFrame and perform some transformations. In order to focus on converting between data types in this example, we’ll just drop some extraneous columns with Pandas. However, this is where you will most likely leverage the full force of Pandas to perform all of your data preparation and analytics.
df = table.to_pandas()
pd = df[['cpu', 'usage_system', 'time']]
pd.head()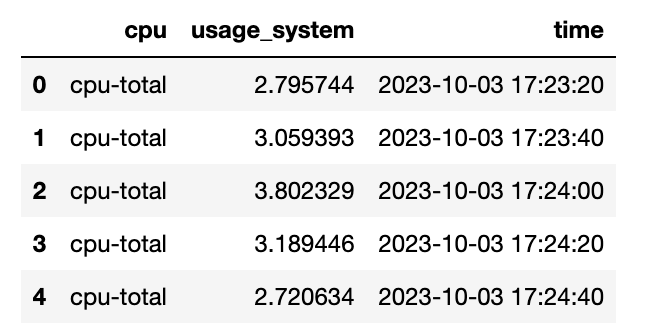
Now, we save the DataFrame to a Parquet file with the following code:
pd.to_parquet(path="./cpu.parquet")Load the Parquet back into an Arrow Table and convert it back into a Pandas DataFrame:
table = pyarrow.parquet.read_pandas("cpu.parquet")
tableLastly, create a DataFusion instance and query the Parquet data with SQL.
# create a context
ctx = datafusion.SessionContext()
# Register table with context
ctx.register_parquet("cpu", "cpu.parquet")
# Query with SQL
df = ctx.sql(
"select 'usage_system' from 'cpu'"
)
df.show()
# To convert back into a Pandas DataFrame
# pandas_df = df.to_pandas()While you currently need to query Parquet files through Arrow, there are loose plans to enable users to query Parquet files directly from InfluxDB. This would allow users to take greater advantage of DataFusion and SQL in InfluxDB v3.
Final thoughts
InfluxDB is a great tool for storing all of your time series data. It’s written on top of the Apache ecosystem and leverages technologies like DataFusion, Arrow, and Parquet to enable efficient writes, storage, and querying. I hope this tutorial helped familiarize you with how to convert between these different data types, and how to query Parquet files with SQL. Get started with InfluxDB Cloud 3.0 here. If you need any help, please reach out using our community site or Slack channel. I’d love to hear about what you’re trying to achieve and what features you’d like InfluxDB to have.
