InfluxDB is Now InfluxData, the Platform for Time Series Data
By
Paul Dix /
Product, Company
Dec 08, 2015
Navigate to:
Today we’re announcing that InfluxDB, the company, is now InfluxData. This is the beginning of delivering on our long-term vision: to create the platform for developing apps, services and IoT architectures that rely on time series data. To us, time series data is important not just because it tracks things changing in time, but because tracking that change is exactly what informs historical trends, intelligence, insight, and prediction. We believe that developers need a platform that enables them to quickly build new and innovative applications on top of all these data. In this blog we’ll outline why we think time series data is important; the TICK stack (the stack we are building our platform on); and our continued development on the InfluxDB database.
Why time series data and why now?
The first wave of “Big Data” represented user generated activity and content. But today, there are already more sensors in the world than there are humans. Sensors can be software-based like those that track what happens in applications, servers, routers or other IT equipment, or they can be physical sensors taking measurements in phones, drones, factory equipment, cars, home appliances and countless other devices.
All of these sensors are outputting data continuously; often many times per second and it’s all time series. In addition to physical sensors, the order of magnitude increase in ephemeral data being driven by Docker, OpenStack and other container/IaaS technologies is just beginning.
Event-driven or sensor data can all be understood as many separate time series. By tracking changes over time we can look at historical trends, gain insight into what’s happening right now, detect anomalies in real-time, provide real operational visibility, and make predictions about the future. Many of these series are ephemeral, creating special challenges for existing technology stacks.
The sensor revolution is only at its infancy and the tidal wave of data it creates will make “Big Data” look like a ripple in a pond in comparison. We’re building for that future.
The four problems of time series data
Our motivation for building a platform was born out of our recognition of four key problems for those working with time series: collection, storage, visualization, and processing. Many developers have asked us for solutions to these problems. Up to now, we’ve mostly focused on the storage part of the problem. We still have much to do on that end, which I’ll address later, but first I’ll talk about each part of the four time series-related problems and the TICK stack.
Collection is where it all starts. How do you get data from your applications, servers, sensors, routers, factory equipment, appliances, or cars to a place where you can store, monitor, or make it available for analysis?
To many, storage is the obvious piecewhere do you store the time series data you’ve collected? There are some unique problems that have to be solved in the storage tier when working with time series. You might have billions or trillions of individual data points indexed by arbitrary metadata. Often, the time-based data and the metadata related to it are ephemeral, which means you’re deleting as much data as you’re writinga particularly hard problem for databases.
Visualization is all about summarizing data to help people gain insight into whatever factors they’re measuring. Meanwhile, processing is all about transforming, monitoring, and algorithmically gaining insight from your data, which can include things like ETL, alerting, and anomaly detection.
We’ve found that these four problems surface in nearly every use case in which developers are working with time series data, including DevOps, real-time analytics, sensor data, IoT, automation, finance, business intelligence and many others. Our goal is to build a platform that helps developers build intelligent applications in all of these areas. That’s why we’re introducing the TICK stack.
Introducing the TICK stack
Before we get into the origin of the TICK stack and the specific components, I should address a question that many of you probably have: why build new tools for collection, visualization, and processing when those tools already exist and are open source? Wouldn’t our effort be better focused solely on building InfluxDB?
The most important reason for building the other tools is that our data model in InfluxDB doesn’t match up exactly with any of the existing tools. We rethought the time series problem from the database up, which means we needed new tools to seamlessly integrate with InfluxDB and take advantage of its schema.
The TICK stack is just that set of tools. It’s an acronym that stands for Telegraf, InfluxDB, Chronograf, and Kapacitor. I’ll introduce each of these tools and link to more detailed blog posts later on, but first I’d like to talk about the origin of the name TICK.

TICK is a reference to a term used in finance: “a price increment in which the prices are quoted.”
While InfluxData’s corporate headquarters are in San Francisco, InfluxDB was born in New York City, a place that is steeped in finance. In fact, the first time I built a “time series database” was for a financial technology startup based in Midtown NYC. Other than the obvious link to NYC and finance, we liked the idea of a tick for another, more subtle reason: a tick only has context within the frame of something changing in time.
To us, that’s time series. Not just things changing in time, but the idea that being able to track change over time is what informs intelligence and insight over the course of the tracked object’s history.
We knew we had to build four different projects to tackle each of our key areas of collection, storage, visualization, and processing. With tick as the starting point, we already had InfluxDB so we decided to pick the names of the other tools to line up with an acronym: TICK.
Telegraf is an open source tool for collecting data from servers, well-known services, third-party APIs, andin the futurerouters, sensors on ARM hardware, and more. Learn more by visiting the Telegraf page.
InfluxDB is our open source distributed Time Series Database and the thing that got all this started. I’ll talk a bit more in depth about our future plans on InfluxDB in the next section of this post.
Chronograf is our free-to-use visualization tool for building dashboards and doing ad-hoc exploration of data in InfluxDB. We’re also working on open-sourcing visualization components from Chronograf to enable developers building custom applications to go from nothing to storing and visualizing time series data in their applications in a few minutes. Learn more by visiting the Chronograf page.
Finally, Kapacitor is our open source tool for processing time series data. It works with both streams or batches and is great for doing ETL, monitoring, alerting, and real-time statistics and leaderboards. Learn more by visiting the Kapacitor page.
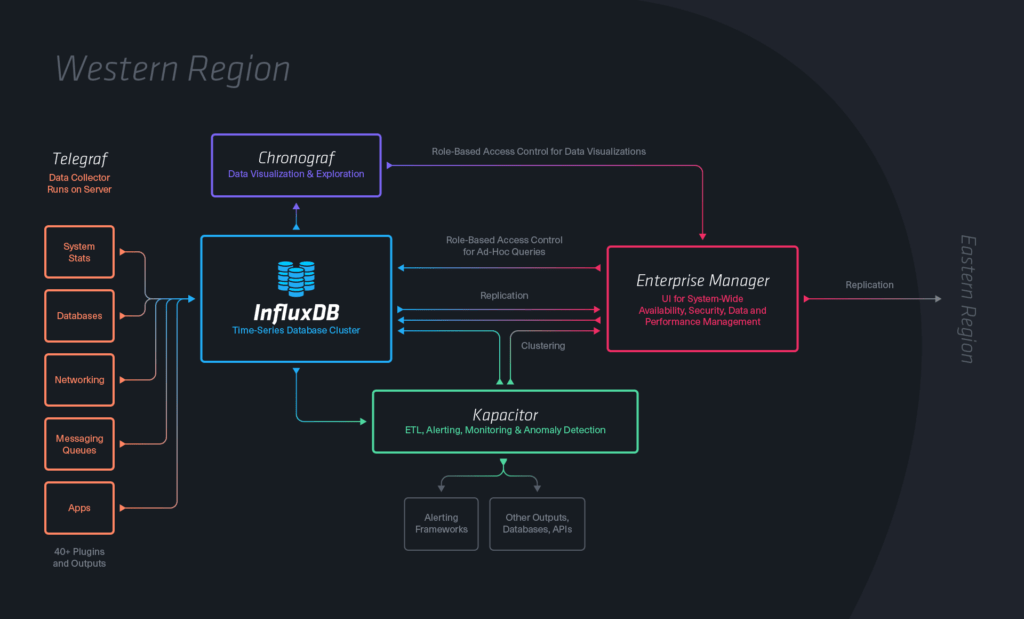 With the TICK stack we want to give developers all the tools they need to quickly build applications in DevOps, analytics, sensors, IoT, and all areas of time series. One of our driving goals is to optimize for developer happiness, and we believe that comes when a developer can quickly build the applications they’re dreaming up.
With the TICK stack we want to give developers all the tools they need to quickly build applications in DevOps, analytics, sensors, IoT, and all areas of time series. One of our driving goals is to optimize for developer happiness, and we believe that comes when a developer can quickly build the applications they’re dreaming up.
InfluxDB development and immediate goals
Although this post is about our renaming to InfluxData, many readers are probably interested in what’s happening with InfluxDB and our immediate goals. InfluxDB development is a top priority within the company.
There are currently thousands of users of InfluxDB (both the older 0.8.8 version and the newer 0.9.x versions). However, there are some waiting on the sidelines for our work on performance and clustering to advance. For the users that are already up and running, we’ve received a resoundingly positive response about what we’re doing.
This is the tradeoff we made with developing in the opensome users would get immediate value, while others would be disappointed by our progress or early breaking changes. The advantage of developing in the open and being willing to make major changes is that we’ve avoided a local optimum. That is, the later versions of InfluxDB will be much stronger and versatile because we were willing to make major changes early on. We’ve had API stability for 4 releases now and are targeting only additive changes for upcoming releases.
It’s our belief that iteration and continuous improvement are the keys to building a fantastic product. We’re going to strive for excellence in our efforts, and we feel accountable to our users.
For the next few months we have major improvements coming to InfluxDB in the storage engine, clustering, and general stability. The InfluxDB 0.9.6 release is only the beginning and you can start testing today with the TSM storage engine, which has been optimized specifically for time series. See the InfluxDB 0.9.6 release announcement from today for more details.
More than InfluxDB
Now that we’re InfluxData, we’re more than just InfluxDB, the Time Series Database company. We’re a comprehensive platform for time series data that enables developers to build cool things. We saw many users struggling to solve collection, visualization, and processing problems in conjunction with storage. InfluxData is our bid to help developers and users in all four areas.
From a much higher level, we’re excited about what we’re doing because we’re helping people build things. As an advisor recently told me, “You’re excited to build cool shit for people who build cool shit.” We are indeed.
What's Next?
Take one or all of the components for a spin by working through our Get Started guide or going straight to the Downloads page.