Eventual Consistency: The Hinted Handoff Queue
By
Katy Farmer
updated December 14, 2025
Use Cases
Developer
Product
Navigate to:
In this blog series, we’re going to explore eventual consistency, a term that can be hard to define without having all the right vocabulary. This is the consistency model used by many distributed systems, including InfluxDB Enterprise edition. There are two concepts we need to know in order to understand eventual consistency: the hinted handoff queue and anti-entropy, both of which require special attention.
Part I
What is the Hinted Handoff Queue?
Despite having a pretty cool name, the hinted handoff (HH) queue doesn’t get a lot of attention. The HH queue has a pretty important job, but unless you’re a system admin, you rarely interact with it directly. Let’s dig into what exactly a hinted handoff queue is and why it matters to you.
In order to talk about the HH queue, we have to talk about distributed computing — just a little. One reason systems like InfluxDB Enterprise exist as distributed systems is to eliminate single points of failure. InfluxDB Enterprise uses replication factor (RF) to determine how many copies of any one set of data should exist. Setting the RF above 1 means the system has a higher chance of servicing a request successfully and not returning an error during a data node outage, meaning we no longer have only one copy of the data that could be lost or unavailable. Distributed systems also offer up unique challenges: how do we know that the data is consistent across the system, especially when storing multiple copies of data?
First, we have to understand some of the promises made by eventual consistency. Spoiler alert: the data in the system must eventually be consistent. When we ask for information from a distributed system, there are points in time where the answer we receive may not be consistently returned. There is some “drift” in terms of the answer we receive as data is stored and replicated throughout the system, but over time, that “drift” should be eliminated. In practice, this means that the most recent time ranges may have the most variation in their results, but that variation is eliminated as the system works through the mechanics of ensuring that the same information is available everywhere.

If we promise that the system will eventually be consistent, how do we account for failed writes? Data nodes can go offline for any number of reasons, from running out of disk space to plain old hardware malfunctions. If a node is missing data points from the time it spent offline, it can never be consistent, and thus, our promise of eventual consistency would become a lie.
Failed writes can also affect the replication factor across the system. Maintaining the specified RF is another promise that we have to keep, and it’s another possible point of failure for writes if data nodes are offline.
Example
Let’s explore the simplest example: InfluxDB Enterprise with 2 data nodes and a database with an RF = 2. Data arrives to your favorite load balancer via some collection agent (e.g. Telegraf), the load balancer distributes the writes (also reads, but we’ll use writes in this example) to the underlying data nodes. Typically, the load balancer distributes the writes in a round-robin fashion. The data node receiving that data stores and replicates it (sends it to the other data node) and voila: the RF of 2 is achieved.
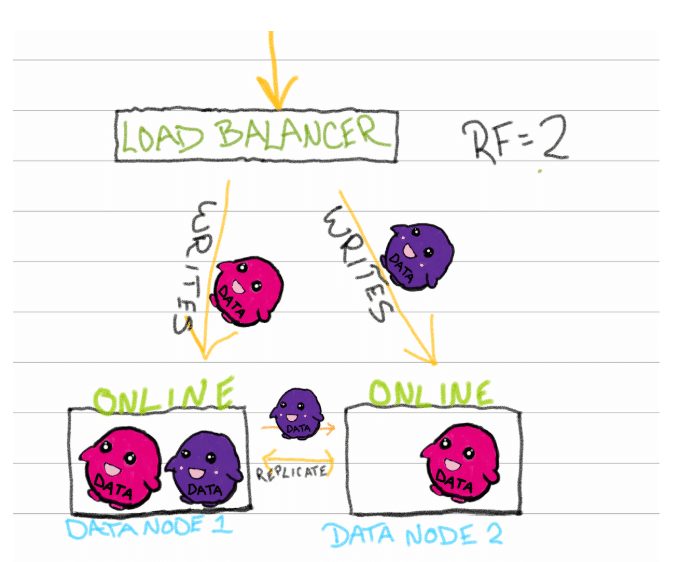
Note: Not pictured in the diagrams are the meta nodes, which you can read about here.
We still need a solution for failed or delayed writes. Let’s say one of the nodes in our system gets physically overheated and goes offline. Without a backup, any unsuccessful writes are dropped completely, never to be seen again.
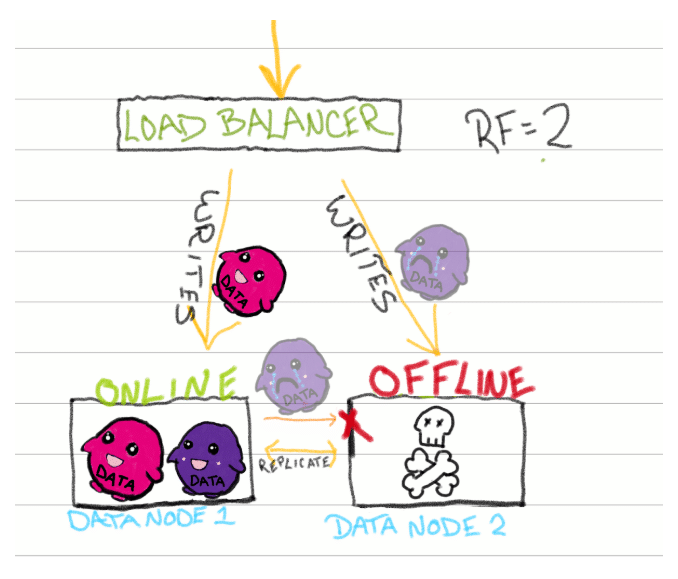
Enter the HH queue.
The HH queue is a durable, disk-based queue. It’s a fundamental part of InfluxDB Enterprise that attempts to ensure eventual consistency, which is a mechanism that ensures that all of the data nodes will eventually have a consistent set of data across them. For InfluxDB Enterprise, the HH queue is one important part of achieving eventual consistency and making sure that data replication factor for each database is ultimately achieved.
Now, let’s revisit the scenario where one of the data nodes in my cluster goes offline. There are tons of reasons a node could go offline: hardware defects, disk space limitations, or even regular maintenance. Without the hinted handoff queue, the unsuccessful writes died before they could ever be stored, but now we have a safe place for them to land.
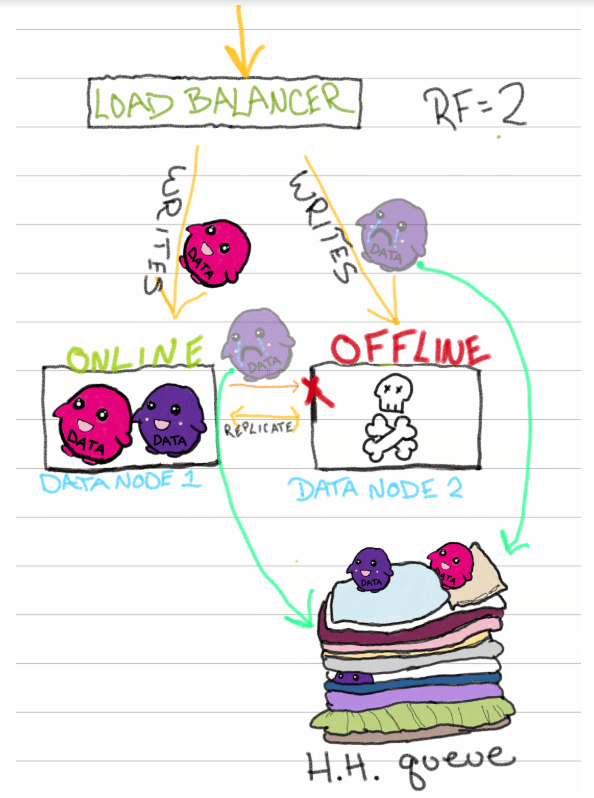
Any unsuccessful writes get directed to the HH queue, and when the node comes back online, it checks the HH queue for pending writes. The node can then complete writes until the queue is drained. Bameventual consistency achieved.
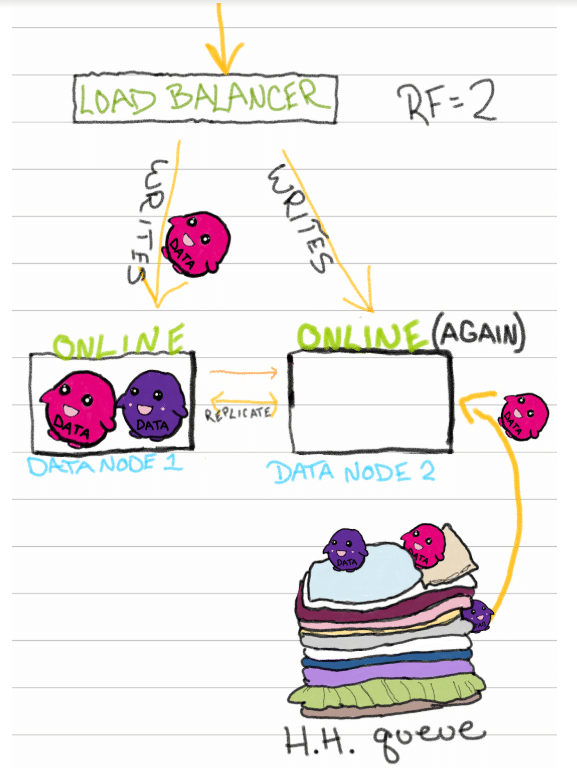
Summary
This is a look at what happens inside an eventually consistent cluster, but there are a few considerations from the outside: when data is successfully written to one node, but fails to replicate correctly, does the user see success or failure? What do healthy patterns in the HH queue look like? What does it mean for overall system health if the HH queue is constantly filling and draining? In the next article, we’ll discuss how to troubleshoot and identify problematic patterns in our InfluxDB Enterprise clusters.
