Metrics to Monitor in Your PostgreSQL Database
By
Margo Schaedel
updated December 14, 2025
Product
Use Cases
Developer
Navigate to:

Overview
Last month I wrote a guide on how to monitor your PostgreSQL database using Telegraf and InfluxDB, and though I was able to cover a walkthrough of how to monitor PostgreSQL, I didn’t have a chance to cover what exactly you should be looking at when tracking the health of your database. There are several key metrics you’ll definitely want to keep track of when it comes to database performance, and they’re not all database-specific. For example, this blog post on MySQL database metrics gives a great introduction and overview to get you started in the monitoring scene.
PostgreSQL’s statistics collector automatically gathers a substantial number of statistics about its own activity. In the previous post we saw that the Telegraf plugin for PostgreSQL pulls data from two of these built-in views: pg_stat_database and pg_stat_bgwriter. If you want to pull in data from additional views, you should definitely check out this extended Telegraf plugin. In this post, we’ll take a more thorough look at the significance of these stats as an indicator of your PostgreSQL database health.
The pg_stat_database View
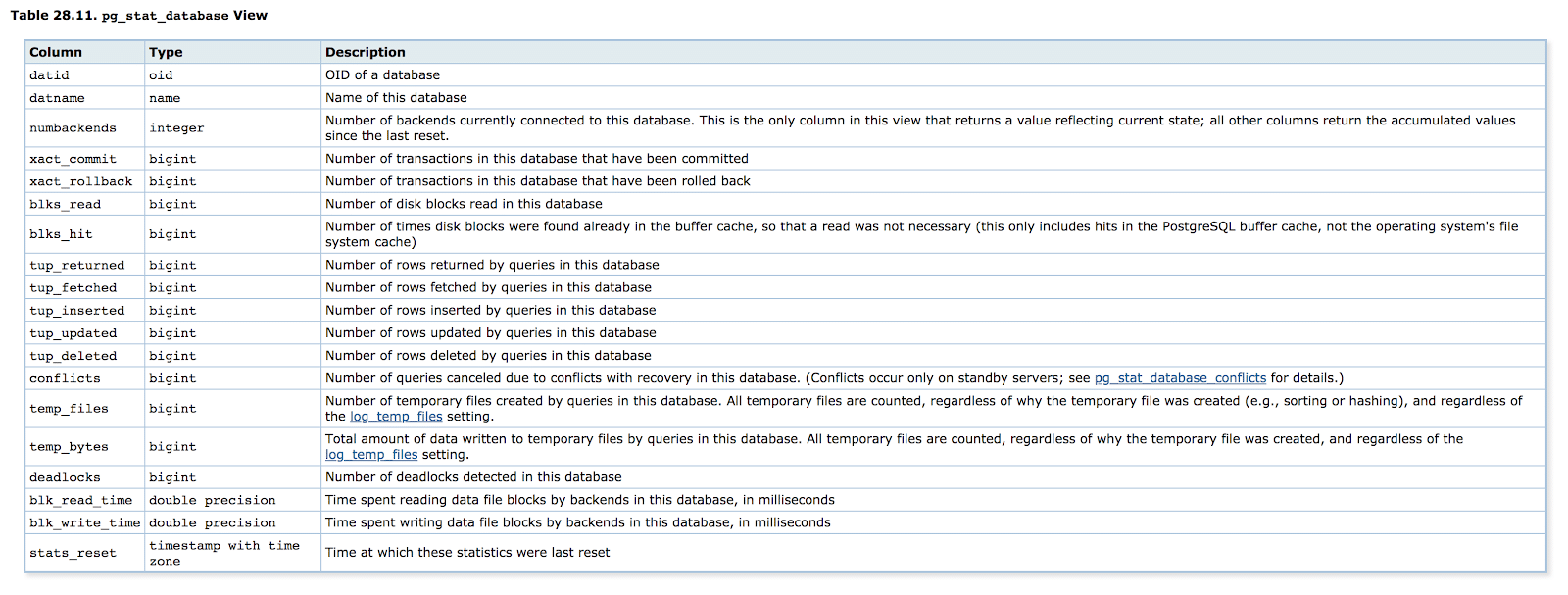
The pg_stat_database view records information concerning each database within a given cluster, including the database id (datid); number of backends actively connected to the database (numbackends); commits and rollbacks; disk blocks read and shared buffer cache hits; rows fetched, inserted, updated, and deleted; conflicts and deadlocks; temporary files created; and duration times spent reading and writing data.
The pg_stat_bgwriter View

The pg_stat_bgwriter view supplies information about the checkpoint process in order to determine how much load is being placed on the database while it’s updating or replicating files. The variables cover the number of total checkpoints occurring across all databases in the clusterboth scheduled and requested checkpointsin addition to the amount of time spent in checkpoint processing. The buffers_checkpoint, buffers_clean, and buffers_backend indicate how the buffers were written to disk.
The Basics - Resource Utilization
In order for anything to be written, updated, and queried within PostgreSQL, the database needs to have adequate resources with which to achieve these tasks successfully. PostgreSQL, like other databases out there, relies heavily on various system resources such as CPU, network bandwidth, disk space/disk utilization, and RAM. Therefore, having insight into these system metrics and others like disk IOPS, swap space, and network errors can generally provide a good indication of the health of your overall database.
A few other metrics you may want to keep tabs on that PostgreSQL collects information on include connections, shared buffer usage, and disk usage. Tracking variables like numbackends in relation to max_connections (the pg_settings view) can draw attention to possible issues with slower queries and applications having to create new connections in order to carry out requests rather than using already active connections. You would rather keep a small pool of connections alive than have to constantly start up new ones and terminate idle ones.
Keeping an eye on shared buffer usage can be significant for reading or updating data. The shared buffer cache is where PostgreSQL will check first when executing a request, and if the block is not found there, it will then need to grab the data from disk, after which the data will be cached in the database’s shared buffer cache and possibly the OS cache. This allows for subsequent querying of that data without needing to access it on disk. However, the downside to this is that some data could end up cached in several places at once. Keep an eye on blks_hit and blks_read, which represent shared buffer hits and blocks read from disk, but also keep in mind that data sometimes gets saved in the OS cache, which PostgreSQL doesn’t report on.
Lastly, gathering information about the database’s disk usage (see pg_table_size or pg_indexes_size) can help to illuminate possible problems with query performance. There is a direct relationship between the twoas tables and indexes increase in size, queries will inevitably take longer, resulting in a need to allocate more disk space. A sudden rise in table or index size can also hint at problems with the VACUUM process (the process of cleaning up and removing dead rowsread more on that below).
Read/Write Throughput
Monitoring read and write query throughput helps to ascertain that your applications are able to both add data to the database and access it as well. Issues arising in this area can often lead to problems in other parts of the database, especially with regards to replication and reliability. In order to ensure availability, it’s not a bad idea to keep an eye on your reads and writes.
Take a look at tup_returned, the number of rows read or scanned versus tup_fetched, the number of rows fetched that contained data necessary to execute the query successfully. These two variables should consistently stay pretty close in number, which would point to the database carrying out read queries efficiently, since it wouldn’t be scanning through extra rows to satisfy the query requirements. Additionally, you may want to track temp_files and temp_bytes, since PostgreSQL sometimes has to write data temporarily to disk in order to successfully execute various queries (if there is not enough memory available). High numbers in this area indicate a potentially increasing number of resource-draining queries.
You’ll also want to make sure your write performance is up to snuff, so keeping tabs on tup_inserted, tup_updated, and tup_deleted is crucial. High rates of updated and deleted rows could lead to a higher number of dead rows (n_dead_tup in the pg_stat_user_tables view), which is another metric to keep tabs on. Having a huge number of dead rows (rows that have already been deleted and are waiting to be cleaned out) indicates something may be wrong with the clean-up processin PostgreSQL, this process is known as the VACUUM process. Essentially, its job is to remove dead rows from tables and indexes in order to make the space available for new row insertions. As a side note, the VACUUM process should be run on a routine basis to allow for continued query efficiency and to update PostgreSQL’s internal statistics regularly. Remember that high amounts of dead rows (essentially wasted space) can definitely slow down your queries in the long-term.
If you encounter high rates of change in both read and write throughput, it makes sense to check if there are delays occurring from locks (lock from the pg_locks view) on tables or rows that are currently experiencing or awaiting updates. Related to this is the presence of any deadlocks in the database, which occur when several transactions hold locks on a row or table that another transaction needs in order to execute a query. It’s best avoid the occurrence of deadlocks altogether if possible by ensuring that locks are assigned in a consistent order each time.
Reliability
If your data is pretty important to you, then you’re probably keeping multiple copies of it (so you don’t lose it all in the event of a crash) and you want it to be highly available at all times. This is where the pg_stat_bgwriter view can make a big difference. It tracks a number of checkpoint metrics.
Checkpoints are periodic moments in the transaction process that ensure data files have been updated up to that moment on disk. If that sounds confusing, think of how word processors periodically auto-save the files you’re working on and if your program were to crash, upon reboot you’re brought back to that previous auto-saved version. Checkpoints operate similarly with respect to recorded and updated data files. Generally, the process of flushing the updated data to disk can cause significant I/O load, and as a result, checkpoint activity is spaced out in order to avoid a loss in performance. This means that a single checkpoint must complete before the next one can start.
Compare the following two variables: checkpoints_req and checkpoints_timed. The first shows the number of checkpoints requested while the latter represents the number of checkpoints scheduled. It’s preferable to have more checkpoints scheduled than requested; the other way around could point to your checkpoints not being able to keep up with the rate of data updates and indicate heavy load on the database.
The pg_stat_bgwriter also shows metrics on how PostgreSQL chooses to flush data in memory (buffers) to disk. It can do this in three different ways
buffers_backend- via backendsbuffers_clean- via the background writerbuffers_checkpoint- via the checkpoint process
Ideally you want most of the flushes happening via the checkpoint process, but sometimes the background writer steps in to help lighten the I/O load that often occurs in the checkpoint process. An increase in buffers written directly by backends could mean a write-intensive load that is creating buffers so fast the checkpoint process can’t keep up. Ultimately, it’s in your best interest to keep an eye on these three.
Summary
Hopefully all this information can be combined with the previous tutorial to make it super easy for you to monitor your PostgreSQL databases using Telegraf and InfluxDB. Feel free to reach out to us on Twitter @InfluxDB and @mschae16 with any questions or comments or you can check out our community forum to see what other InfluxData users are building.
