Benchmarking LevelDB vs. RocksDB vs. HyperLevelDB vs. LMDB Performance for InfluxDB
By
Paul Dix
updated December 14, 2025
Product
Navigate to:
For quite some time we’ve wanted to test the performance of different storage engines for our use case with InfluxDB. We started off using LevelDB because it’s what we had used on earlier projects and RocksDB wasn’t around yet. We’ve finally gotten around to running some basic tests against a few different engines. Going forward it looks like RocksDB might be the best choice for us.
However, we haven’t had the time to tune any settings or refactor things to take advantage of specific storage engine characteristics. We’re open to suggestions so read on for more detail.
Before we get to results, let’s look at the test setup. We used a Digital Ocean droplet with 4GB RAM, 2 Cores, and 60GB of SSD storage.
The next release of InfluxDB has a clearly defined interface for adding different storage engines. You’ll be able to choose LevelDB, RocksDB, HyperLevelDB, or LMDB. Which one you use is set through the configuration file.
Under the covers LevelDB is a Log Structured Merge Tree while LMDB is a mmap copy on write B+Tree. RocksDB and HyperLevelDB are forks of the LevelDB project that have different optimizations and enhancements.
Our tests used a benchmark tool that isolated the storage engines for testing. The test does the following:
- Write N values where the key is 24 bytes (3 ints)
- Query N values (range scans through the key space in ascending order and does compares to see if it should stop)
- Delete N/2 values
- Run compaction
- Query N/2 values
- Write N/2 values
At various steps we checked what the on disk size of the database was. We went through multiple runs writing anywhere from 1 million to 100 million values. Which implementation came out on top differed depending on how many values were in the database.
For our use case we want to test on databases that have more values rather than less so we’ll focus on the results for the biggest run. We’re also not benchmarking put operations on keys that already exist. It’s either inserts or deletes, which is almost always the use case with time series data.
The keys consist of 3 unsigned integers that are converted into big endian bytes. The first is an id that would normally represent a time series column id, the second is a time stamp, and the third is a sequence number. The benchmark simulates values written into a number of different ids (the first 8 bytes) and increasing time stamps and sequence numbers. This is a common load pattern for InfluxDB. Single points written to many series or columns at a time.
Writes during the test happen in batches of 1,000 key/value pairs. Each key/value pair is a different series column id up to the number of series to write in the test. The value is a serialized protobuf object. Specifically, it’s a FieldValue with an int64 set.
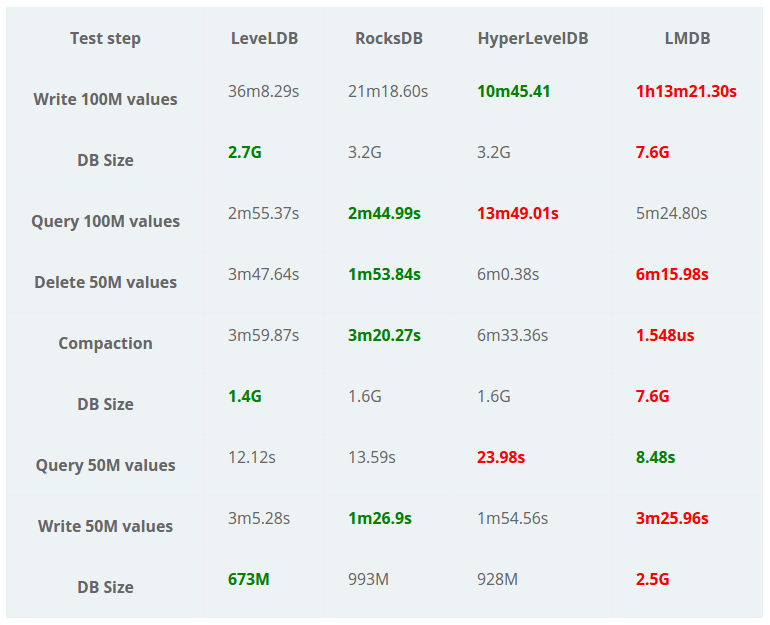
Here are the results of a run on 100 million values spread out over 500k columns:
 ode> method of each of the storage engines.
ode> method of each of the storage engines.
A few interesting things come out of these results. LevelDB is the winner on disk space utilization, RocksDB is the winner on reads and deletes, and HyperLevelDB is the winner on writes. On smaller runs (30M or less), LMDB came out on top on most of the metrics except for disk size. This is actually what we’d expect for B-trees: they’re faster the fewer keys you have in them.
I’ve marked the LMDB compaction time as a loser in red because it’s a no-op and deletes don’t actually reclaim disk space. On a normal database where you’re continually writing data, this is ok because the old pages get used up. However, it means that the DB will ONLY increase in size. For InfluxDB this is a problem because we create a separate database per time range, which we call a shard. This means that after a time range has passed, it probably won’t be getting any more writes. If we do a delete, we need some form of compaction to reclaim the disk space.
On disk space utilization, it’s no surprise that the Level variants came out on top. They compress the data in blocks while LMDB doesn’t use compression.
Overall it looks like RocksDB might be the best choice for our use case. However, there are lies, damn lies, and benchmarks. Things can change drastically based on hardware configuration and settings on the storage engines.
We tested on SSD because that’s where things are going (if not already there). Rocks won’t perform as well on spinning disks, but it’s not the primary target hardware for us. You could also potentially create a configuration with smaller shards and use LMDB for screaming fast performance.
Here’s a gist of more of the results from different benchmark runs.
We’re open to updating settings, benchmarks, or adding new storage engines. In the meantime we’ll keep iterating and try to get to the best possible performance for the use case of time series data.
Next Steps:
- Download InfluxDB
- Read more about the TICK stack
