InfluxDB for Predictive Maintenance in Industrial Operations
#1
Time Series Database
Source: DB Engines
1B+
Downloads of InfluxDB
Take the complexity out of time series data management
Try InfluxDBTurn high-volume, high-velocity, high-resolution time series data into actionable intelligence without sacrificing performance.
Get high-speed ingestion, real-time querying, and seamless scalability in a highly performant time series database that can handle unlimited volumes of time series data, even as data complexity and cardinality increases.
Run InfluxDB at scale in any environment in the cloud, on-premises, or at the edge. InfluxDB consists of the core database and storage engine, an API, and an ecosystem of tools and integrations to manage time-stamped data. Easily integrate with 5K+ prebuilt connections using Telegraf, our open source agent with 5B+ downloads.
Run InfluxDB 3 where you need it
Start for free, scale in seconds
Start NowFor small workloads and getting started
Deploy anywhere: on-prem, private cloud, edge, or multi-tenant cloud.
Secure, dedicated cloud infrastructure
Run a Proof of ConceptFor scaled workloads
Fully-managed, single-tenant service with unlimited scale, high availability, secure private connections, and enhanced Support.
Own your data with enterprise features
Run a Proof of ConceptFor scaled workloads
Control your infrastructure with unlimited scale, high availability, enterprise-grade security, and enhanced Support. On-prem, private cloud, and edge deployment.
Why InfluxDB
Limitless data collection
Ingest and analyze millions of time series data points per second without limits or caps.
Predict and prevent
Maximize uptime and prevent costly failures with real-time monitoring and preventative insights.
Real-time query
Data is immediately available for querying in InfluxDB, enabling real-time SQL queries and lightning-fast responses.
Why InfluxDB for industrial operations?
InfluxDB can handle the scale, volume, and precision of industrial data. It integrates with key Operations Technology stacks and ecosystems.
Why predictive maintenance?
A broken process
The established approach to industrial maintenance is reactionary and broken. Servicing industrial equipment occurs on a set schedule, or after it fails. In a sector where efficiency matters, this process is inefficient and expensive. It results in unnecessary maintenance on machines that don’t need it, or emergency repairs and unplanned downtime. All this costs money and negatively impacts your bottom line.

Improving effectiveness
Predictive maintenance is an approach that combines historical and real-time data with machine learning and advanced analytics tools to identify patterns and predict machine behavior.
For example, you can use historical data to understand the typical lifespan of a machine valve and combine that with real-time data about the valve’s performance. When the valve shows signs of wear, you can schedule maintenance to replace the valve to minimize the impact on production.
Powering predictive maintenance with InfluxDB
The reason predictive maintenance isn’t more widely practiced is because legacy data historians lack the necessary capabilities. Industrial data can originate from many different sources, arriving in different formats, and at different intervals. This can lead to data gaps with legacy data historians where industrial operators must make critical decisions with incomplete data.
InfluxDB is a purpose-built time series database designed to handle the time series workloads required for predictive maintenance. Providing business-critical insights faster allows industrial operators to set more accurate tolerances and indicators for when components need service or replacement. This improves failure predictions and generates more granular and timely alerts.
Architecture
Predictive maintenance processes rely on machine learning and advanced analytics tools. Training these tools requires massive amounts of data. Therefore, organizations need a way to collect, store, and manage all this data. They also need a solution that integrates with machine learning, analytics, and other tools needed to optimize predictive maintenance processes.
Telegraf is InfluxData’s open source data collection agent. With 300+ plugins, it collects data from any system or protocol, including MQTT, ModBus, OPC-UA, Kafka, Node-Red, and more. Telegraf works seamlessly with InfluxDB, which provides equal access to ‘hot,’ in-memory data, and ‘cold’ data in object storage. This means that organizations can access historical and real-time data with a single solution. When it comes to querying this data, InfluxDB integrates with visualization tools, like Grafana, to ensure stakeholders across the organization have the information they need at their fingertips.
Interoperability
Built using the open source Apache Arrow project, industrial organizations can extend and integrate InfluxDB with a wide range of tools, solutions, and ecosystems. InfluxDB saves data in the Apache Parquet file format, which many other ecosystems use (e.g., Hadoop, Snowflake, Cloudera). These solutions can read Parquet files directly, extending the value of your time series data.
Related resources for developers
Industry 4.0 and InfluxDB
InfluxDB Integrations
IIoT/OT Technical Paper
InfluxDB Edge Data Replication
Free InfluxDB training
Open data standards drive performance and interoperability
InfluxDB 3 is built in Rust and the FDAP stack—Flight, DataFusion, Arrow, and Parquet—leveraging Apache-backed technologies to efficiently ingest, store, and analyze time series data at any scale.
Try InfluxDBF
Flight for efficient columnar data transfer
D
DataFusion for high-performance querying

A
Arrow for optimized in-memory columnar analytics

P
Parquet for high-compression storage
InfluxDB’s columnar database supports time series data at a lower TCO
See ways to get started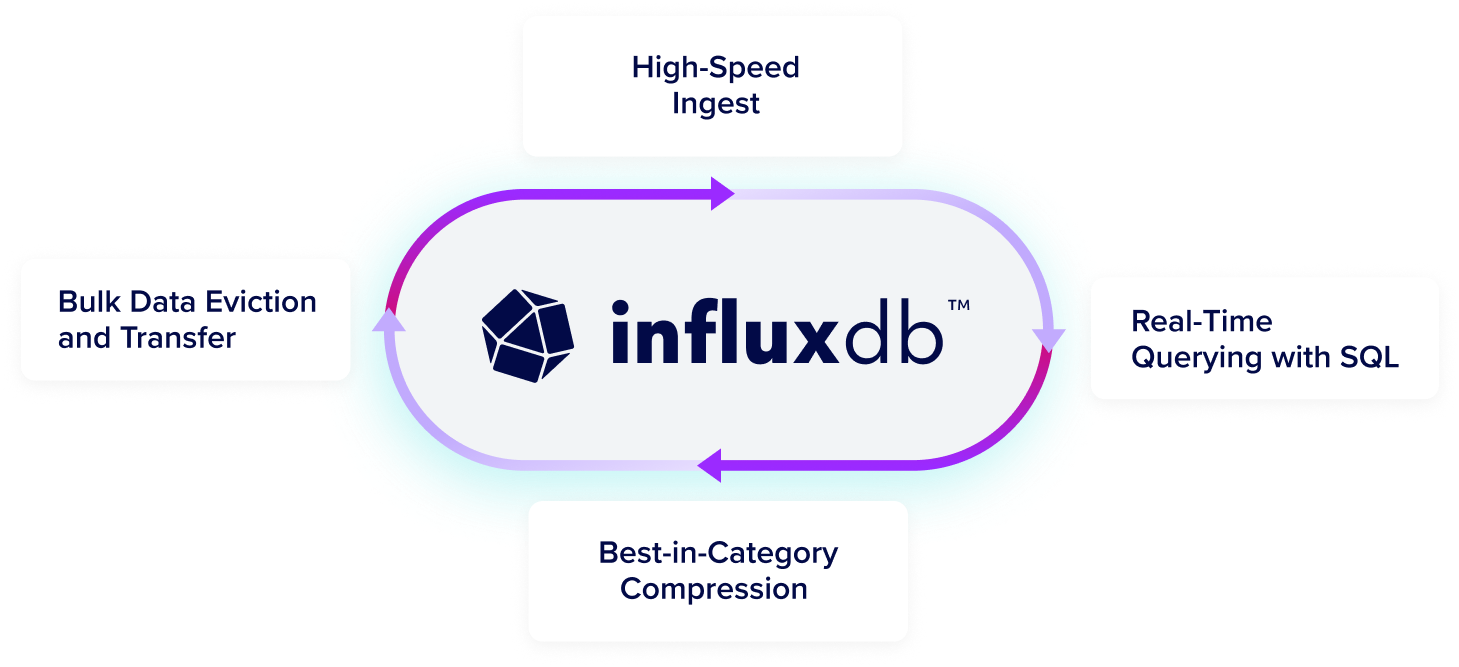

Loved by developers, trusted by enterprises

65M+
daly events processed
45x
more resource efficient
Siemens Energy
"[We] long used InfluxDB open source... Moving to commercial InfluxDB was a strategic move to unify our data infrastructure, ensuring we have the reliability, scalability, and real-time performance to keep pace with production... and proactive maintenance."
Jan Petersen
Senior Manufacturing Engineer
500M+
Metrics collected daily
Mission-critical monitoring
Real-time data access for queries
LOFT ORBITAL
Space Made Simple: How Loft Orbital Delivers Unparalleled Speed-to-Space with InfluxDB Cloud
Read Case Study65M+
daly events processed
45x
more resource efficient
CAPITAL ONE
"InfluxDB is a high-speed read and write database. The data is written in real-time, you can read it in real-time, and while reading, you can apply your machine learning model. So, in real-time, you can forecast and detect anomalies."
Rajeev Tomer
Sr. Manager of Data Engineering
50%
lower total cost of ownership
100K
real-time metrics with simplified deployment
TERÉGA
Teréga Replaced Its Legacy Data Historian with InfluxDB
Lorem ipsum
Lorem ipsum dolor sit amet consectetur.
65M+
daly events processed
45x
more resource efficient
WIDEOPENWEST
"I was blown away with how easy it was to install and configure InfluxDB. The clustering was easy. The documentation was great, and the support has been second to none."
Dylan Shorter
Engineer III, Software and Product Integration Engineering
45%
Less equipment downtime
10%
Reduced waste
MAJIK SYSTEMS
From Reactive to Proactive: How MAJiK Systems Embraced Predictive Maintenance with InfluxDB and Time Series Data
Dylan Shorter
Engineer III, Software and Product Integration Engineering
65M+
daly events processed
45x
more resource efficient
JU:NIZ ENERGY
"With InfluxDB Cloud Dedicated, the great thing is that we don't need to think about data storage costs or usage anymore because data storage gets way cheaper."
Ricardo Kissinger
Head of IT Infrastructure and IT Security



