A UX Review of Flux Joins vs. Pandas Joins
By
Anais Dotis-Georgiou
updated December 14, 2025
Product
Use Cases
Developer
Navigate to:
InfluxData recently released the latest versions of Chronograf and InfluxDB. With them comes the technical preview of Flux. Flux is the new query language and engine for time series data. The documentation for Flux can be found here.
In a previous blog post, I share how I used Flux Joins to perform math across measurements to calculate the efficiency of a heat exchanger. Please read “InfluxDB: How to Do Joins, Math across Measurements”, to contextualize the dataset and joins I’m trying to replicate. The repo for this blog series can be found here.
As I learn Flux, I compare it to languages or libraries I’m already familiar with. I decided to share my experience learning and using Flux because I am surprised that I prefer it over Pandas for time series data. I am surprised because I was very skeptical of Flux at first. For example, I was not a huge fan of the |>, pipe forward. I almost never use pipes, and I wasn’t sure about having to learn a new stroke. Now, I find that they greatly increase readability. Every pipe forward returns a result. Reading Flux queries feel like reading bullet points.
Before I explain why my language preference has changed, I want to share my review of Pandas prior to Flux.
Pandas Joins Review before Flux:
“I love Pandas. DataFrames are amazing. It’s so easy. I can’t imagine ever liking anything more than Pandas Joins or Merges. They behave exactly as expected.’”
Now that you know how I felt about Pandas going into Flux, let’s begin the comparison by taking a look at the first join I make in the previous blog.
The Join in Flux:
Th1 = from(bucket: "sensors")
|> range(start: dashboardTime)
|> filter(fn: (r) => r._measurement == "Tc1")
|> drop(columns:["_start", "_stop", "_measurement", "position", "_field"])
Tc2 = from(bucket: "sensors")
|> range(start: dashboardTime)
|> filter(fn: (r) => r._measurement == "Tc2")
|> drop(columns:["_start", "_stop", "_measurement", "position", "_field"])
TC = join(tables: {Tc1: Tc1, Tc2: Tc2}, on: ["_time"]])Where Tc1 looks like:

Where Tc2 looks like

And the Join looks like:
The Join in Pandas:
My dataset looks like this as a DataFrame.

To replicate the joins, I separate out the data into 4 different DataFrames to reflect 4 different measurements in InfluxDB:

Now if I want to replicate the Flux Join I made, I have to reset the index of my smaller DataFrames. This is because Joins in Pandas operate on the index.
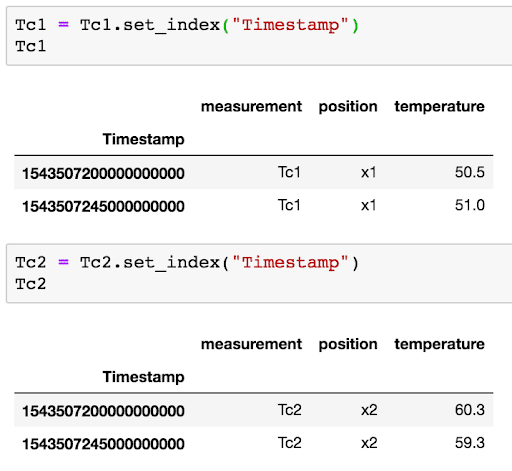
Now I can perform the join.

If I wanted to clean my DataFrame so that it resembles my Flux Join exactly, I would have to drop a lot of columns (specifically, df.drop(["measurement_Tc1, "position_Tc1", "measurement_Tc2", "position_Tc2").
This is what the Pandas Join looks like all together:
Tc1 = df.loc[df['measurement']=='Tc1'
Tc2 = df.loc[df['measurement']=='Tc2'
Tc1 = Tc1.set_index("Timestamp")
Tc2 = Tc2.set_index("Timestamp")
df = Tc1.join(Tc2, how="left", lsuffix='_Tc1', rsuffix='_Tc2')
df.drop(["measurement_Tc1, "position_Tc1", "measurement_Tc2", "position_Tc2"This join is clunky in comparison to the Flux Join for several reasons. First, I have to reset the index. Second, I have to specify the left and right suffixes. I like how, with Flux, I can just store my tables in variables and then associate the tables with suffix of my choice with just a colon. join(tables: {Th1: Th1, Th2: Th2}, on: ["_time", "_field"]) is easy and clear. I don’t have to keep track of my left and right sides. Third, If I wanted to drop columns to make my Pandas Join identical to my Flux Join, I would have to either: a) make copies of my DataFrames first so I don’t lose my data or b) store the join in a new DataFrame and drop the columns after. Option a) means writing more lines of code. Option b) is less efficient.
Flux Joins are really more similar to Pandas Merges, so let’s take a look at one.

This is fine, but there are still some benefits to the Flux Join. Again, I prefer Flux’s colon syntax over having to specify “left_index” and “right_index” as I would with Pandas. Additionally, I love how I can join on more than one column with Flux. Unfortunately, I can’t do this with Pandas. Joining on more than one column is useful when the content of those columns is identical. Imagine that there was only one value for the tag key “position” where position = x. My Pandas Join would look the same as the one above except that the “position_x” columns and the “position_y” columns would be identical. However with Flux, I could join on ”time” and “position”. My resulting table would have only one position column. By Joining on multiple columns with Flux, I can eliminate duplicated or verbose columns easily and efficiently. This feature is especially useful for time series data, where having duplicate tag values, timestamps, or field keys is normal and frequent.
I am left with this new impression of Pandas.
Pandas Joins Review after Flux:
“I still love Pandas. However, I’m starting to understand why Flux is purpose-built for time series data. It’s not really fair to compare Pandas against Flux, because Pandas wasn’t written exclusively for time series data.”
As I continue comparing and contrasting Flux with other ways of working with data, I keep coming back to the same thought. Time series data has unique attributes and the time series data exploration experience needs to be specifically tailored to them. It is apparent that Flux is being written with that consideration in mind.
