Announcing Flux (formerly IFQL) v0.0.3
By
Nathaniel Cook
updated December 14, 2025
Product
Use Cases
Developer
Navigate to:
The Flux (formerly IFQL) team releases a new version every two weeks. We want to get our changes into the hands of our community quickly so we can hear of your experiences early. Please submit issues and PRs on the repo. Check out the Flux release announcement for details on the vision behind Flux .
These last two weeks we have focused on performance and resource management (i.e. managing CPU and memory resources so that a single query cannot overwhelm the Flux process).
Benchmarking
We have put together benchmarks comparing Flux to InfluxQL. These benchmarks have been put in place early so that we can ensure going forward in continuing to maintain strong performance. Here are some initial charts showing where Flux is compared to equivalent InfluxQL queries.
Five representative queries have been run on both systems1. To see details of the benchmarks, check out the PR.
Here are the five queries:
Query #1
IFQL - from(db:"db").range(start:2017-11-01T00:00:00Z, stop:2017-11-02T00:00:00Z).filter(exp:{"_measurement" == "m0" and "_field" == "v0" and $ > 0}).sum()
InfluxQL - SELECT sum(v0) FROM m0 WHERE time >= 2017-11-01T00:00:00Z AND time < 2017-11-02T00:00:00Z AND v0 > 0 GROUP BY *Query #2
IFQL - from(db:"db").range(start:2017-11-01T00:00:00Z, stop:2017-11-05T00:00:00Z).filter(exp:{"_measurement" == "m0" and "_field" == "v0" and $ > 0}).sum()
InfluxQL - SELECT sum(v0) FROM m0 WHERE time >= 2017-11-01T00:00:00Z AND time < 2017-11-05T00:00:00Z AND v0 > 0 GROUP BY *Query #3
IFQL - from(db:"db").range(start:2017-11-01T00:00:00Z, stop:2017-11-05T00:00:00Z).filter(exp:{"_measurement" == "m0" and "_field" == "v0" and $ > 0}).group(by:["tag0"]).sum()
InfluxQL - SELECT sum(v0) FROM m0 WHERE time >= 2017-11-01T00:00:00Z AND time < 2017-11-05T00:00:00Z AND v0 > 0 GROUP BY tag0Query #4
IFQL - from(db:"db").range(start:2017-11-01T00:00:00Z, stop:2017-11-13T00:00:00Z).filter(exp:{"_measurement" == "m0" and "_field" == "v0" and $ > 0}).sum()
InfluxQL - SELECT sum(v0) FROM m0 WHERE time >= 2017-11-01T00:00:00Z AND time < 2017-11-13T00:00:00Z AND v0 > 0 GROUP BY *Query #5
IFQL - from(db:"db").range(start:2017-11-01T00:00:00Z, stop:2017-11-13T00:00:00Z).filter(exp:{"_measurement" == "m0" and "_field" == "v0" and $ > 0}).group(by:["tag0"]).sum()
InfluxQL - SELECT sum(v0) FROM m0 WHERE time >= 2017-11-01T00:00:00Z AND time < 2017-11-13T00:00:00Z AND v0 > 0 GROUP BY tag0First, let’s look at execution time as that is most important when considering the performance of a query engine.
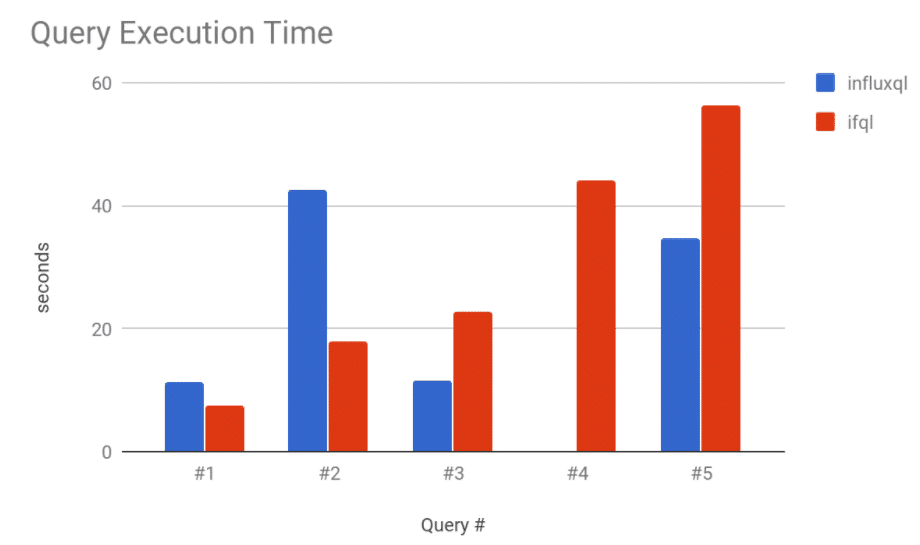
For most queries, Flux is already faster than InfluxQL. Note Query #4 did not complete using InfluxQL and so has no time. We have an issue open already that should improve Query #5.
Next examining the heap usage of the processes, we can see that Flux is significantly more efficient in its usage.
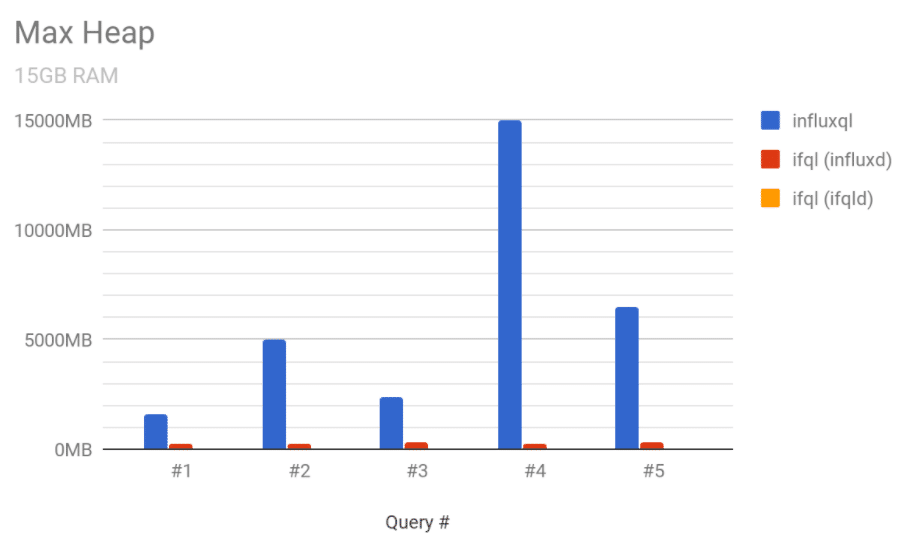
The heap usage of both ifql processes barely registers in comparison to the heap usage of InfluxQL. Note, there are two ifql processes, ifqld which can be any number of sidecar processes, and influxd running with the new IFQL API enabled.
Resource Management
With version v0.0.3, it is now possible to limit the resources a query consumes. Our goal is to ensure that primarily a really hungry query can’t crash the process and secondarily the hungry query will fairly share resources with other concurrent queries according to its priority.
Now with these limits in place, a bad query that tries to consume too much memory is killed and an appropriate error is returned, instead of allowing the query to crash the process.
We also ran tests comparing v0.0.2 with v0.0.3. The test submitted more queries than the processes had resources. We then compared the execution times of the queries and could see that v0.0.3 reduced the overall execution time by 15%. This is accomplished by queuing and scheduling the work instead of letting all the queries concurrently fight over resources. The long tail latencies increase in v0.0.3 because of the queueing, but we have a plan to solve that issue later.
Overall v0.0.3 is a solid iterative release, and we will see you again in two weeks with another release. For a complete list of all changes see the CHANGELOG.
Footnotes:
[1] Note that InfluxDB master now has a Prometheus “/metrics” endpoint we used to collect these stats. We also used a new tool ingen to create the test datasets.
