Table of Contents
The team at InfluxData is excited to announce the stable version of InfluxDB 0.10! This is a significant release because it now uses the TSM storage engine. The improvements to stability, performance, compression are huge. This is the biggest and most important release of InfluxDB yet, so now is the time to start thinking about your migration strategy. Read on for all the details.
Performance
The work we’ve done on the TSM storage engine has significantly improved performance on writes. In addition to overall throughput, we’ve reduced the IOPS load by more than an order of magnitude. With a test on a 4 core system with 16GB of RAM we wrote 100B data points in 5,000 point batches. The sustained write load over the course of the test was >350,000 points per second and IOPS were fairly steady around 750.
This makes it feasible to run TSM and InfluxDB under significant write load on hardware with spinning disks. The write performance at this point is mostly CPU bound. Servers with more CPUs will be able to support higher write throughput.
The performance for this version of InfluxDB now supasses anything from 0.9.x by more than a factor of 70x. This version also significantly passes the write performance of any previous InfluxDB release, including the 0.8.x line of releases.
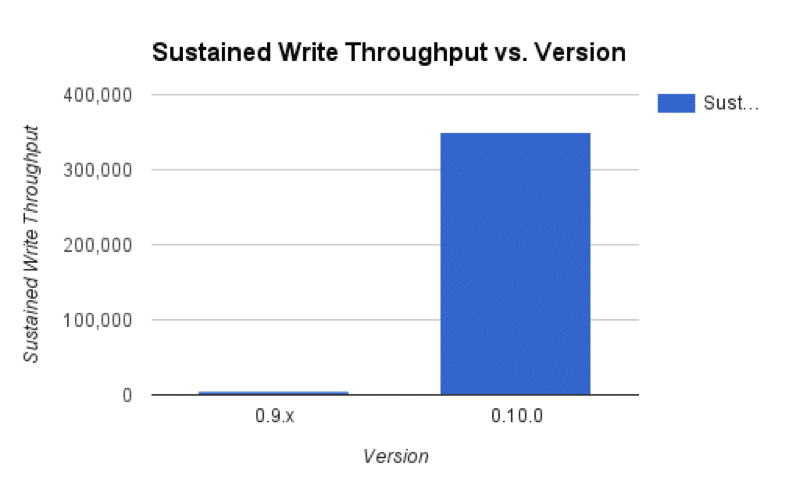
InfluxDB write throughput comparison (bigger is better)
Compression
The TSM storage engine features compression that is specific to time series. For each data type we use different compression techniques. It depends greatly on the shape of your data, but with regularly spaced timestamps at second level precision and float64s, we’ve seen compression reduce each point down to around 2.2 bytes per point.
This compression is 98% better than what we saw with 0.9.x and better than what 0.8 provided. If you’re running tests, you’ll see compression improve as the compaction process runs in the background. This happens automatically while InfluxDB is running.
With this release InfluxDB has some of the best compression available for time series solutions.
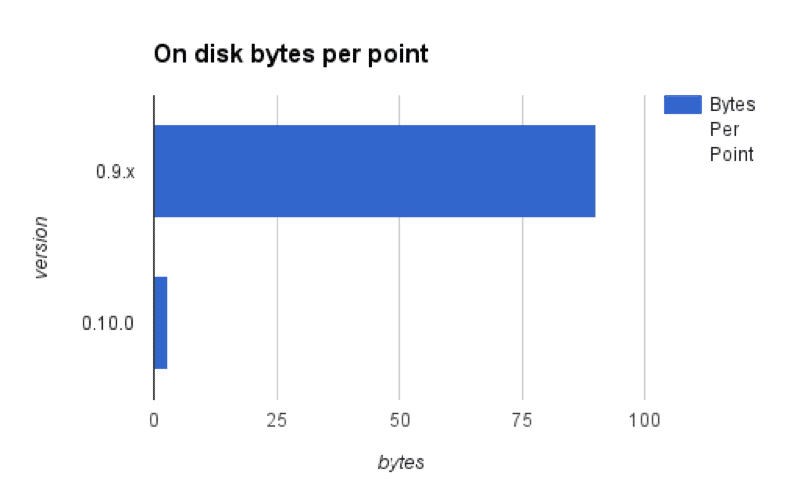
InfluxDB bytes per point comparison (smaller is better)
Stability and testing
We put significant effort into this release on testing and improving stability. For the TSM storage engine, we’ve been actively testing it for months on various hardware configurations, in customer deployments, and in the cloud. We did tests that killed the database in the middle of compactions, write and queries and did it over and over again.
With the code in this release, we were unable to create a scenario in which the database became corrupted. Put simply, this release has more testing and burn in behind it than any other code or release we’ve put out previously. Check the video below recently given at the SF InfluxDB Meetup where VP of Engineering and Co-Founder Todd Persen walks you through the testing and benchmarking methodology.
Upgrading from previous versions
How do upgrade from 0.9 to 0.10?
If you’re upgrading from version 0.9.x, it should be an in place upgrade if you’re running a single server. The existing shards will still use the old storage engine, while new shards will use the TSM storage engine. This means that if you upgrade, you won’t see the performance increases immediately. You’ll have to wait for new shards to get created.
What about 0.9 shards?
Future versions of InfluxDB will remove support for shards using the old storage engine. We’ve created a migration tool to convert from the old storage engine to TSM. For running this release it’s not a requirement, but you’ll get a huge reduction in the amount of disk space those old shards take if you do the conversion.
What about upgrading a 0.9 cluster?
If you’re running a clustered setup of 0.9.x and want to upgrade, you’ll need our help to do so. Please drop us a line at [email protected] to setup a consultation with one of our solution architects.
What about upgrading from 0.8?
If you’re running version 0.8.9 or earlier, now is the time to start looking at migrating to 0.10.0. If there are any show stoppers that prevent you from migrating over, let us know and we’ll prioritize getting those into the next release. Need help in putting together a migration plan? We can help with that! Drop us a line at [email protected] to schedule a consultation.
Clustering improvements
“What about clustering?” is likely your next question. We’ve put a lot of effort into improving our clustering implementation and enabling some useful new configurations. We now have the concept of a Meta Node and a Data Node. By default, all servers in a cluster will act as both. However, it’s now possible to separate them.
This means in very large clusters or configurations where Data Nodes are under heavy load, Meta Nodes can be separated. Another configuration that is useful is with two nodes that act as both Meta and Data nodes, while a third, lesser powered node can act only as a Meta node. This is kind of similar to some other databases that allow you to run with two large servers and an “arbiter”.
The new configuration has changed slightly how clusters get set up with this version. Read this guide on how to setup an InfluxDB cluster for more information.
Clustering is still marked as experimental, but our testing is ramping up and we’ve found it to be much more reliable. If you’re interested in running clusters in production with the current versions, [email protected] to schedule a consultation on how to get deployed to production with the least amount risk.
What's next?
Head on over to the downloads page to start evaluating the new release. We have much more planned, but this release marks a huge milestone in the continued development and maturity of InfluxDB. More time-series goodness to come!
