Assessing Write Performance of InfluxDB's Clusters w/ AWS
By
Todd Persen
updated December 14, 2025
Product
Navigate to:
While conducting the various benchmark tests against InfluxData, we decided to also explore the aspects of scaling clusters of InfluxDB with our closed-source InfluxDB Enterprise product, primarily through the lens of write performance.
This data should prove valuable to developers and architects evaluating the suitability of InfluxDB Enterprise for their use case, in addition to helping establish some rough guidelines for what those users should expect in terms of write performance in a real-world environment.
To read the complete details of the benchmarks and methodology, download the "Assessing Write Performance of InfluxDB's Clusters w/ AWS" technical paper or watch the recorded video titled: "How cluster creation and differences impact performance."
Our goal with this benchmarking test was to create a consistent, up-to-date comparison that reflects the latest developments in InfluxDB and InfluxDB Enterprise. Periodically, we'll re-run these benchmarks and update this document with our findings. All of the code for these benchmarks are available on GitHub. Feel free to open up issues or pull requests on that repository or if you have any questions, comments, or suggestions.
Now, let's take a look at the results
Versions Tested
InfluxDB Enterprise: v1.1.0
InfluxDB is an open-source time-series database written in Go. At its core is a custom-built storage engine called the Time-Structured Merge (TSM) Tree, which is optimized for time series data. Controlled by a custom SQL-like query language named InfluxQL, InfluxDB provides out-of-the-box support for mathematical and statistical functions across time ranges and is perfect for custom monitoring and metrics collection, real-time analytics, plus IoT and sensor data workloads.
About the Benchmarks
In building this benchmark suite, we identified a few parameters that are most relevant to scaling write performance. As we'll describe in additional detail below, we looked at performance across three vectors:
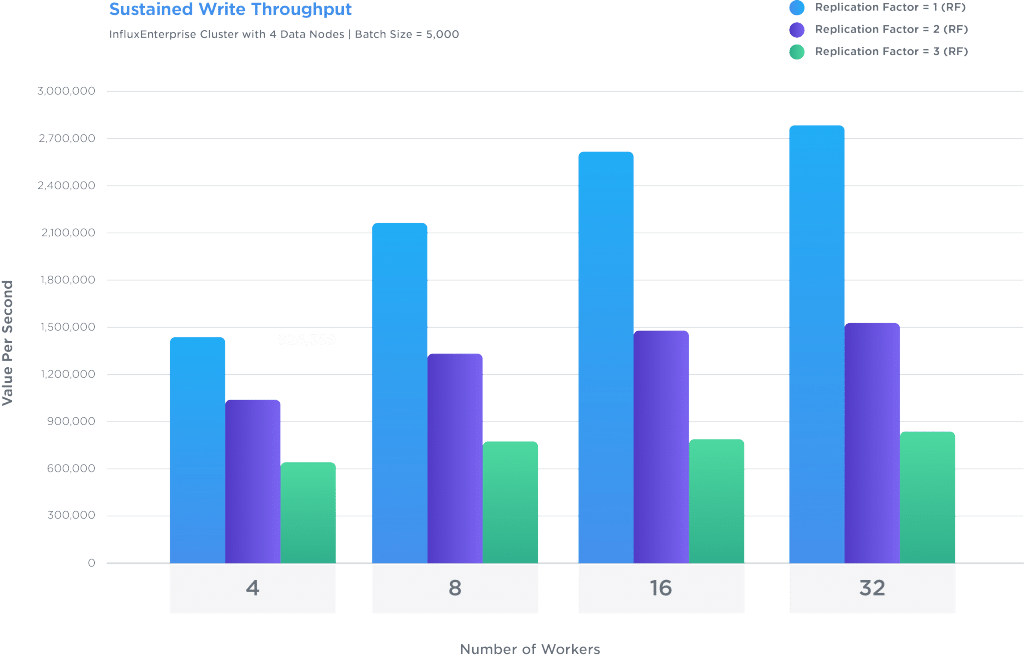
 For maximum write performance, make sure you use multiple concurrent workers per data node.
For maximum write performance, make sure you use multiple concurrent workers per data node.
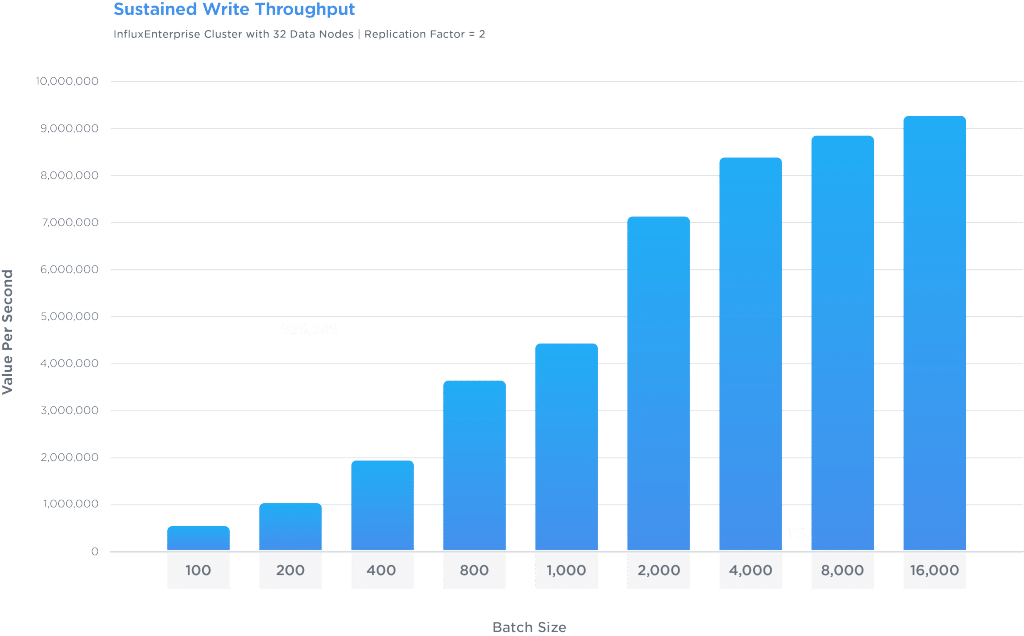
 Using larger batch sizes will generally increase total write throughput to the cluster.
Using larger batch sizes will generally increase total write throughput to the cluster.
- Number of Data Nodes
- Replication Factor
- Batch Size
About the Data Set
For this benchmark, we focused on a dataset that models a common DevOps monitoring and metrics use case, where a fleet of servers are periodically reporting system and application metrics at a regular time interval. We sampled 100 values across 9 subsystems (CPU, memory, disk, disk I/O, kernel, network, Redis, PostgreSQL, and Nginx) every 10 seconds. For the key comparisons, we looked at a dataset that represents 10,000 servers over a 24-hour period, which represents a decent-sized production deployment. We also provided some color about how these comparisons scale with a larger dataset, both in duration and number of servers.
- Number of Servers: 1,000
- Values measured per Server: 100
- Measurement Interval: 10s
- Dataset duration(s): 24h
- Total values in dataset: 8,640,000,000/day
Write Performance
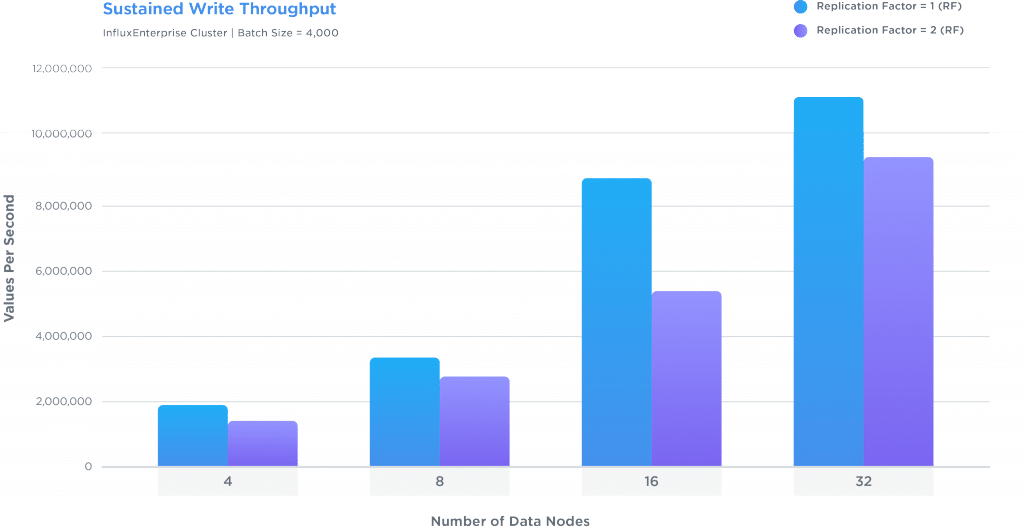
InfluxDB Enterprise scales horizontally for writes, showing throughput increases for up to 32 datanodes
For maximum write performance, make sure you use multiple concurrent workers per data node.
Using larger batch sizes will generally increase total write throughput to the cluster.
Summary
The benchmarking tests and resulting data demonstrated that along these vectors, InfluxDB Enterprise should generally:
- Achieve higher write throughput with more data nodes
- Achieve lower write throughput with a higher replication factor
- Achieve higher write throughput with larger batch sizes
Most excitingly, we demonstrated that a 32-node cluster of InfluxDB Enterprise is capable of handling over 11.1 million writes per second singly-replicated, and over 9 .3 million writes per second doubly-replicated. In contrast, single nodes of InfluxDB generally hit peak performance at just under 1 million writes per second, even on the most performant hardware.
We highly encourage developers and architects to run these benchmarks themselves to independently verify the results on their hardware and data sets of choice. However, for those looking for a valid starting point on which settings will help optimize write performance, these results should serve as a useful guide for scaling and optimizing InfluxDB Enterprise clusters.
What's next
- Chronograf Getting Started
- Downloads for the TICK-stack are live on our "downloads" page
- Deploy on the Cloud: Get started with a FREE trial of InfluxDB Cloud featuring fully-managed clusters, Kapacitor and Grafana.
- Deploy on Your Servers: Want to run InfluxDB clusters on your servers? Try a FREE 14-day trial of InfluxDB Enterprise featuring an intuitive UI for deploying, monitoring and rebalancing clusters, plus managing backups and restores.
