Building a Simple, Pure-Rust, Async Apache Kafka Client
By
Marco Neumann
updated December 14, 2025
Use Cases
Developer
Navigate to:
This article was originally published in The New Stack.
For InfluxDB IOx, the future core of InfluxDB, we use Apache Kafka to sequence data:
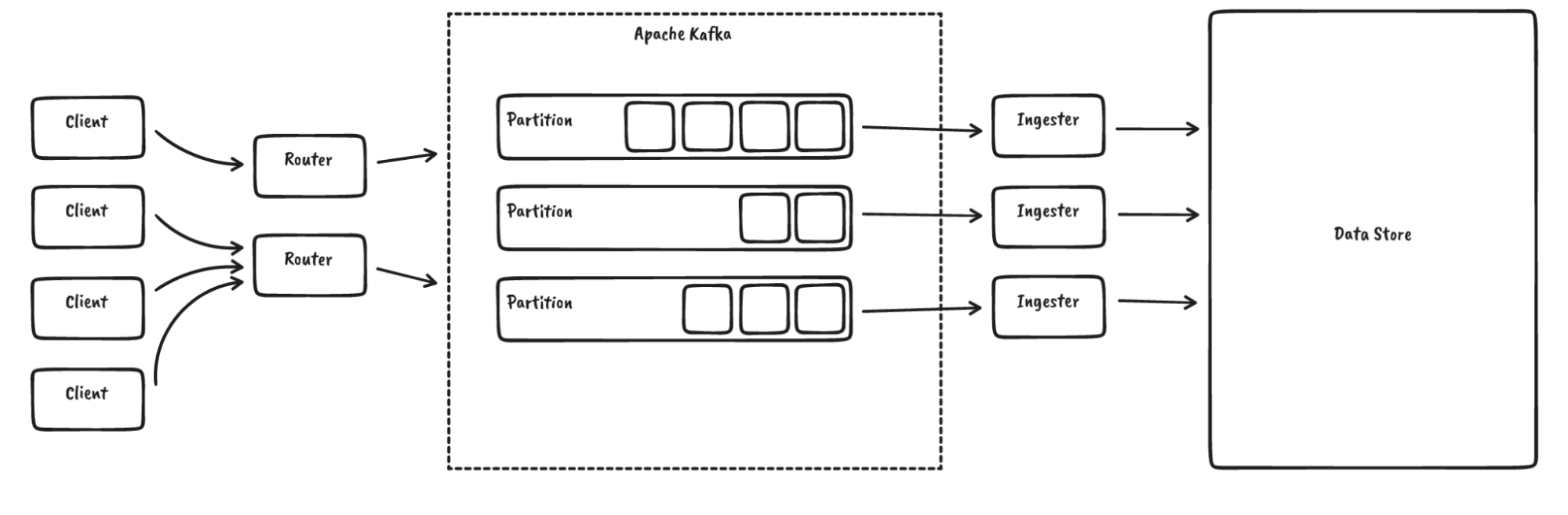
Up until now, we have relied on rust-rdkafka, which provides async binding for librdkafka, which in turn is written in C. So why would we replace that? Here are some reasons:
- Complexity: librdkafka is a complex library with loads of features that we do not need or want, and that supports a wide range of Kafka versions while we basically run the "latest." Since rust-rdkafka also only exposes a small subset of librdkafka's functionality, we think that this might apply to other users as well.
- Bindings: rust-rdkafka tries to shoehorn librdkafka into the Rust async ecosystem. This somewhat works but has led to issues, such as tokio getting confused when callbacks are executed from different threads. The bindings themselves come with some limitations as well.
- Buffering/Modularity: We have limited control over how buffering and batching work in librdkafka. This is an inherent issue of cross-language libraries.
- Expertise and Insights: Bugs and unexpected behavior are hard to debug. We do not feel comfortable using the current state in production.
- Feasibility: We only use a very limited subset of the Kafka functionality (for example, no transactions), for which the Kafka protocol is rather simple. For this subset, it is actually doable to write a new client.
This is why we decided to start a simple, fresh, fully-async Kafka client in Rust: RSKafka.
Here is a quick usage example. First, we set up a client:
let connection = "localhost:9093".to_owned();
let client = ClientBuilder::new(vec![connection]).build().await.unwrap();Let’s create a topic:
let topic = "my_topic";
let controller_client = client.controller_client().await.unwrap();
controller_client.create_topic(
topic,
2, // partitions
1, // replication factor
5_000, // timeout (ms)
).await.unwrap();And then we produce and consume some data:
// get a client for writing to a partition
let partition_client = client
.partition_client(
topic.to_owned(),
0, // partition
)
.await
.unwrap();
// produce some data
let record = Record {
key: b"".to_vec(),
value: b"hello kafka".to_vec(),
headers: BTreeMap::from([
("foo".to_owned(), b"bar".to_vec()),
]),
timestamp: OffsetDateTime::now_utc(),
};
partition_client.produce(vec![record]).await.unwrap();
// consume data
let (records, high_watermark) = partition_client
.fetch_records(
0, // offset
1..1_000_000, // min..max bytes
1_000, // max wait time
)
.await
.unwrap();You might jump straight to the source code, but I also invite you to read along and learn how we have built it and what practices can work for client libraries in general.
Kafka protocol
The first question when writing a new client for a protocol is: How complex is it? This question should, hopefully, be answered by the protocol specification. In the Kafka case, there are a few documentation pieces, even though none of them fully covers the whole protocol:
- Kafka Protocol Guide: Gives a high-level overview of how the protocol works and a detailed description of the message layout, but not of the message semantics.
- Kafka Documentation: Provides details of how record batches (such as the actual payload) are serialized.
- Kafka Improvement Proposals: These are in-depth explanations of why and how the protocol has evolved. There are over 800 of them, and navigating them is a bit tricky. Also be aware that in a few cases, they are slightly out of sync with the actual implementation.
- librdkafka: Looking at the source code of other implementations can help.
- Wireshark: Especially when hunting down bugs or trying to understand what other implementations do, just looking at the sent and received packages can be helpful. Luckily, Wireshark comes with native Kafka protocol support.
Kafka uses a single TCP connection per client?broker connection. This is good because we can rely on the operating system to provide us message ordering, backpressure, connection-level retries and some form of error handling. The data is then framed using a 32-bit signed integer size followed by the payload:
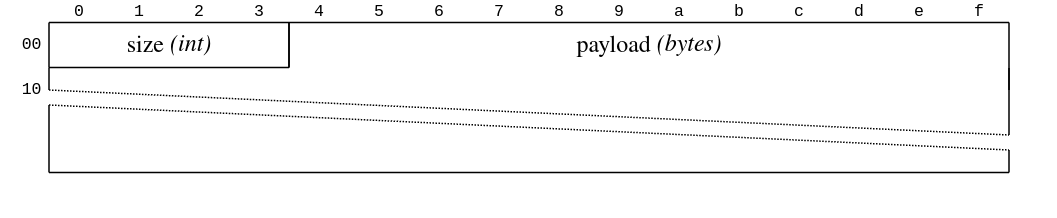
A network engineer might wonder, “Which type of 32-bit integer?” Indeed, Kafka declares its protocol primitives in a dedicated section of the protocol documentation for this particular type:
“Represents an integer between -231 and 231-1 inclusive. The values are encoded using four bytes in network byte order (big-endian).” (It is implicitly assumed that signed integers are encoded as two’s complement.)
The payload itself is a simple request-response model with headers and body. Here is the request:
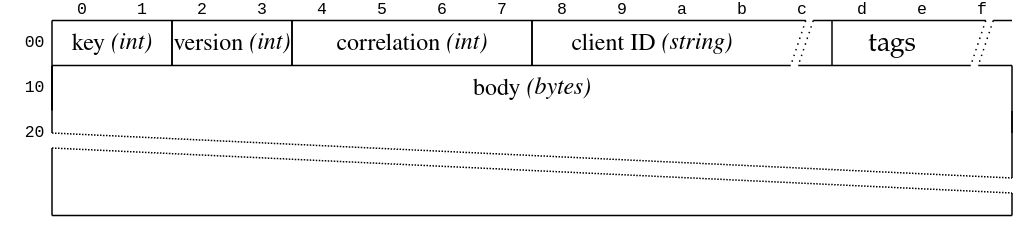
And here is the response:

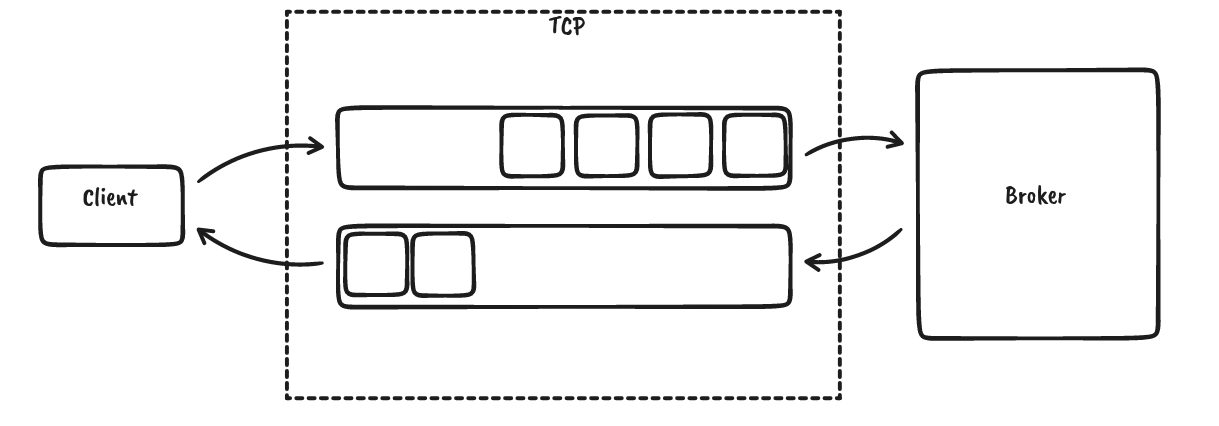
Requests are sent from the client to the broker, and the broker will only send responses for the requests it received. There are no server-initiated transfers. The correlation ID maps responses to the requests. The data can be pipelined; for instance, we can already send more requests even though we are waiting for a response, but no message reordering will be done by the server even though the correlation IDs would allow that:
The other important fields in the request header shown above are the API key and version. (The client ID is just a string, and the tags are an extension mechanism.) The version is specific to the API key and is negotiated using a special message called ApiVersion, which signals the version ranges (one per API key) that the broker supports. The client then picks the highest versions it supports from these ranges. For new versions, fields are added and removed, data types are altered, but also the semantics of certain fields can change. This is a bit different to other protocols like protocol buffers. RSKafka tries to be a good citizen and supports this form of negotiation, even though it does not implement all known versions. Instead, we have implemented only a sufficient set of versions for the functionality we need.
While implementing a new protocol seems like a lot of work, in general you almost always can use some tooling to implement a protocol client – the standard library that supports reading and writing integers in big and little endian encoding, helper libraries for specific tasks like CRC computation, parser frameworks like nom (not used by RSKafka), transport-related crates like rustls and more.
Testing
Testing protocol implementations can and should be done in multiple layers. Let me walk you through them.
Serialization roundtrips
When serializing and deserializing a data type, like the primitive types mentioned earlier, it can be helpful to check if a number of different values can be stored and read successfully. A quick and convenient way to do this is proptest:
proptest! {
#[test]
fn roundtrip_in16(orig: Int16) {
let mut data = vec[]!;
orig.write(&mut data).unwrap();
let restored = Int16::read(&mut Cursor::new(data)).unwrap();
assert_eq!(orig, restored);
}
}Serialization snapshots
While roundtrip tests ensure that we can read data that we have written, it does not ensure any spec compliance. For example, we might have misread the protocol definition and use a totally wrong serialization format. Binary snapshots are a byte sequence that we know are an encoding of a certain data structure. These can be either acquired from a protocol specification (if listed there) or by observing what other clients do, such as by using Wireshark:
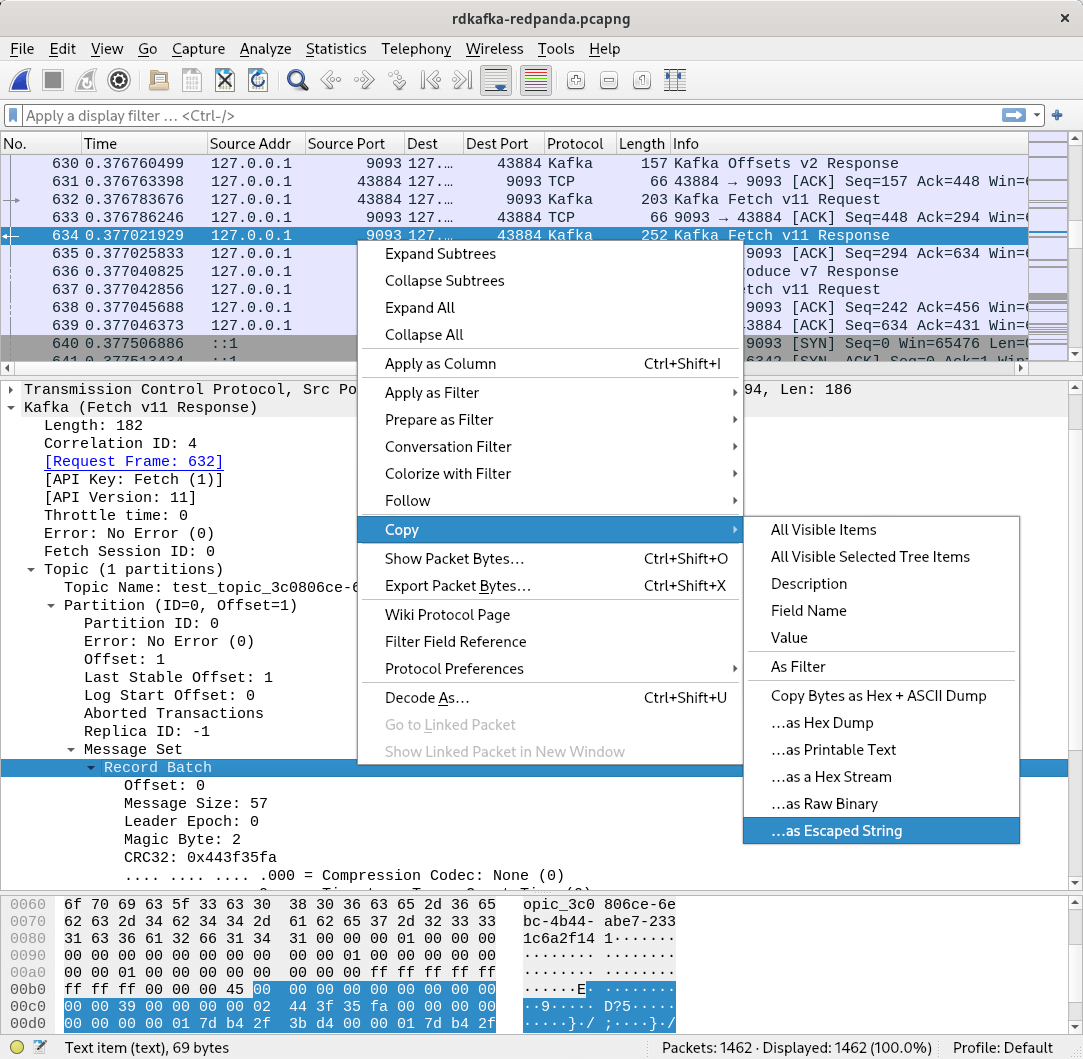
Snapshots can also help you to understand a protocol when the specification is unclear or confusing. (Or if no specification is available at all, in which case we are talking about reverse engineering.) We use these snapshots in a few places and deserialize the data, check the resulting structure against a ground truth, and then do an additional roundtrip test to ensure that we are also writing the correct byte sequence.
Integration tests
While developing a new protocol client, it makes sense to do some form of integration testing rather early to double-check whether the protocol documentation was understood correctly. We perform a bunch of actions like creating partitions and producing and consuming data against Apache Kafka as well as Redpanda; both integrate rather easily into our CircleCI pipeline. We also produce and consume messages using rdkafka to crosscheck that other clients would work with the payload produced by RSKafka. Luckily, both server implementations are rather picky and reject any gibberish. Apache Kafka even prints out helpful backtraces on the server console. Be aware that this is not the case for every protocol.
Unit tests
Integration tests will rarely trigger all edge cases that a client needs to handle. For that and to speed up testing, it is important to also test parts of the client without any external dependencies. We are in the process of improving our test coverage in that area by abstracting some inner parts of the client so that they can be tested against mocks or even as free-standing functions.
Fuzzing
For every new protocol parser, it is highly recommended to implement some form of fuzzing. Even though you might not expect that your Kafka cluster is attacking you, scrambled bytes from your network or a misinterpretation of the protocol could still lead to unwanted panics. The amazing cargo-fuzz makes fuzzing very simple:
fuzz_target!(|data: &[u8]| {
RecordBatchBody::read(&mut Cursor::new(data)).ok();
});It is helpful to focus on data structures without many length markers or CRC (cyclic redundancy check) fields, since a fuzzer would have a hard time passing these checks. You might wonder how a parser without any unsafe code can panic? Two things that we have found and fixed:
- Out of Memory (OOM): Some data types are serialized as a length marker followed by the actual payload. When reading the length and then preallocating a buffer without considering how much data gets allocated or how much data is left to read, you can easily run out of memory. For Rust, this would abort the process, killing the whole server as a consequence.
- Overflows: Certain integer types require bit shifting while deserializing. Doing this carelessly can lead to overflows. Note that these are normally not checked when compiling in release mode.
Modularity
One of our goals was to give users the choice of how they want to manage prefetching during consumption or batching when writing to Kafka. To accumulate records in batches using a maximum size and a linger time (as shown below), all it needs is:
// construct batch producer
let producer = BatchProducerBuilder::new(partition_client)
.with_linger(Duration::from_secs(2))
.build(RecordAggregator::new(
1024, // maximum bytes
));
// produce data (from multiple threads / places)
let offset: i64 = producer.produce(record).await.unwrap();Another use case that came to our mind while designing the batching mechanism was custom aggregation algorithms. For example, what if instead of RSKafka consolidating multiple records into a batch, the user could provide their own aggregator? One situation where this is useful is IOx. There we can reuse string dictionaries instead of encoding them in every record, improving performance and size consumption. We achieved this by providing a nice extension point via traits:
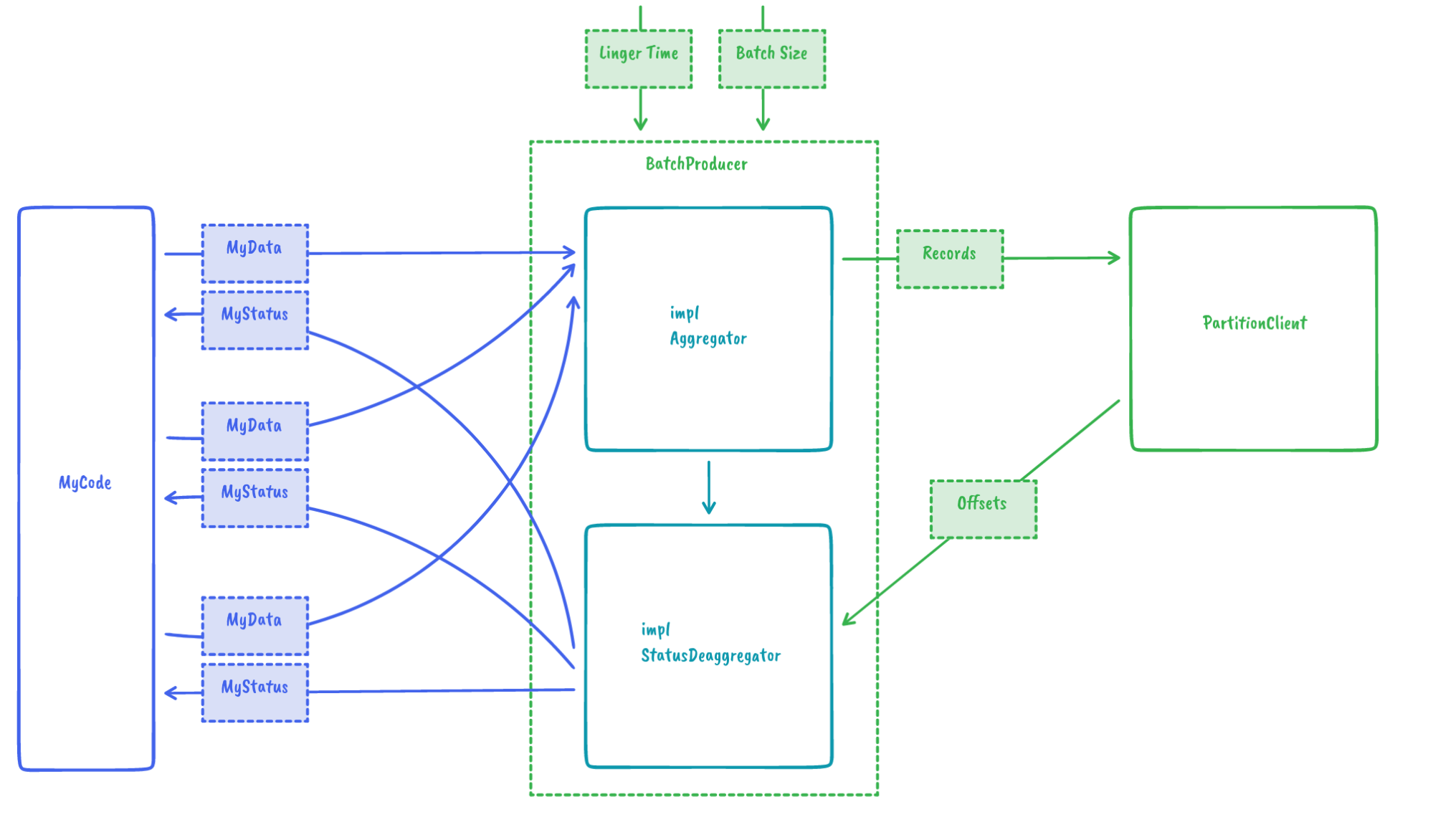
This then leads to the following simple user code:
// construct batch producer
let producer = BatchProducerBuilder::new(partition_client)
.with_linger(Duration::from_secs(2))
.build(MyAggrgator::new(...));
// produce data (from multiple threads / places)
let status: MyStatus = producer.produce(my_data).await.unwrap();Contributions
At the moment, RSKafka is deliberately minimal – it does not support any form of transaction handling. While we do not have any plans to massively extend the functionality ourselves, we are willing to accept community contributions and are looking forward to interesting use cases. See you at https://github.com/influxdata/rskafka.
