The Decomposable Monolith: Long Live the Monolith, Long Live Services!
By
Paul Dix
updated December 14, 2025
Developer
Navigate to:
This is an idea I’ve been kicking around for a little while, and I’m curious what others think about it. Everyone seems to be talking about microservices these days, but in most projects there is a transition point from monolith to service-based designs. I contend that for new projects you should almost always start with a monolith. I said it seven years ago when I wrote about Service Oriented Design with Ruby: if there’s any way you can avoid services, build a monolith application. However, making the shift to services later can be quite tricky, so in this post I’ll explore the advantages of a monolith while proposing a way to structure a new project that lends itself to being broken out into services later. I call this design/architecture pattern The Decomposable Monolith. To help illustrate the idea, we’ll work through an example using Go as the implementation language and a next-generation data platform (say for time series data) as the application.
The Case for the Monolith
With most new software projects, the biggest risk you have is building something that nobody wants. Either it doesn’t meet requirements, or you didn’t understand what users really needed so you started off with the wrong requirements in the first place. In the early phases of a project, feature velocity and iteration with users matter more than almost any other factor. Even if scale is important in your project, all the scale in the world won’t matter if you don’t have the right mix of features and functionality.
Monolithic applications are much faster to develop and iterate on. For example, consider an application that is broken into three services vs. one monolithic application. In a monolith, when you update the code and logic behind any part, there’s only one thing to ship and test. In the services-based design you have to update the API in a service, test it, update the client library, then update the primary application that uses the service to use the updated library. Finally, you need to run a full set of integration tests with everything tied together. Multiply that complexity by the number of services you’re working on that might have changing requirements. Any service that isn’t feature complete & frozen becomes a new layer to be iterated and dealt with.
Monoliths reduce the communication and documentation overhead within your team. With services you have to document and communicate about the client, the API, and the code in the service, where a monolith has only the code. Having separate services and repositories creates silos and communication boundaries. In large mature projects, particularly those with many developers, these silos are an advantage. They become a way to scale your team and your code base while achieving some isolation between the components. However, in a new project that requires feature velocity and quick iterations to tease out requirements, communication overhead and silos become a liability that slow you down.
Finally, monoliths have the advantage that they’re generally easier to setup, test and debug. A developer can get the single thing running and be off to the races. If there are bugs, they don’t have to jump through the complexities of a distributed system and multiple repositories to fix. While tracing might help with this kind of debugging in services-based designs, it has an implementation cost and overhead.
Designing The Decomposable Monolith
I’ve been thinking about this pattern while we’ve been designing out the next generation of InfluxData’s platform. We’re going to be pulling InfluxDB, Kapacitor (processing, monitoring, alerting), and Chronograf (UI, dashboards, admin) together into one cohesive whole (Telegraf will still act as a satellite collection agent). From the beginning, it will be designed as a multi-tenanted system that provides much more than just a database for storing and querying time series data.
The user-facing portions of the product will be an API, presented over REST or gRPC, and a sleek web UI. What it looks like behind those user facing parts depends on the deployment scenario. In the cloud, it will look like a complicated SaaS application architecture consisting of many services. On a developer laptop, it may look like a single binary monolithic application that exposes the same API and UI. In an enterprise on-premise deployment it may be some other architecture.
The idea is that the cloud platform will address scalability and handling many tenants while the monolith will give the developer or user a consistent experience whether working on their laptop, a single deployed server, or our cloud platform. Ideally, they would be able to seamlessly move data from one place to the other and work with it in the same way from an API standpoint. Supporting this kind of deployment scenario is my original motivation for this kind of structure. This could just be a matter of creating the user API and designing down from there, but I’m also trying to think about how to get the best code reuse in the libraries, services, and test suites to support both.
Ok, let’s dive into an example so we can start to think about how to design this thing. First, we start with the API that we want to support. We’ll use a gRPC spec with just the service definition. I’m using gRPC because it’s a nice declarative way to define an API. Converting it into a RESTful interface is an exercise for later. Here’s the service:
// The user facing service definition
service API {
// Some of the multi-tenant stuff
rpc CreateOrganization(Organization) returns (Response) {}
rpc DeleteOrganization(Organization) returns (Response) {}
rpc CreateDB(DBRequest) returns (Response) {}
rpc DropDB(DBRequest) returns (Response) {}
// InfluxDB storage/query API
rpc Write(WriteRequest) returns (Response) {}
rpc Query(QueryRequest) returns (stream QueryResponse) {}
// Kapacitor batch tasks
rpc RunPeriodicQuery(PeriodicQueryRequest) returns (Response) {}
rpc StopPeriodicaQuery(PeriodicQueryRequest) returns (Response) {}
rpc GetPeriodicQueryStatus(PeriodicQueryRequest) returns (PeriodicQueryStatus) {}
// Kapacitor streaming tasks
rpc RunStreamQuery(StreamQueryRequest) returns (Response) {}
rpc StopStreamQuery(StreamQueryRequest) returns (Response) {}
rpc GetStreamQueryStatus(StreamQueryRequest) returns (StreamQueryStatus) {}
}For the purposes of this example, we don’t really need to think about the messages in the requests and response. This is just a subset of what we’ll be doing overall, but it’s enough to illustrate the concepts.
We have the concept of an organization, databases, writes, queries, and Kapacitor tasks running in the background. If we’re building a monolithic application, we could simply take the libraries from those projects and piece them together into a single binary that exposes this API.
However, the goal with this monolith is that we’d like the flexibility to break it up later into distributed services. So instead of jumping straight to implementing the monolith API, we can think about how the service-oriented design might look. Here’s a diagram of what that might look like:
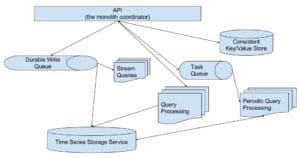
In this example I’ve created some services that are basic building blocks, like the durable write queue, the consistent key/value store and the task queue. Then there are some services that are domain-specific like the time series storage, and the three different types of query processing. The API and the domain-specific services use the shared building blocks to put everything together.
A more traditional service design might look like this:
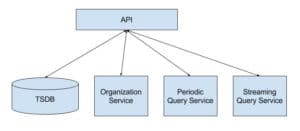
However, I think it’s sometimes better to think in services that provide more atomic building blocks that can be used by the API and other more domain-specific services. I think it’s why many AWS services are so successful.
Going back to the first diagram, let’s get into some specifics of how it might work. Writes would go into the write queue (something like Kafka, which is frequently used as a write ahead log for distributed databases and use cases). The API tier would store organization info, what stream and periodic queries exist and what DBs exist in the consistent key value store. This data would be accessible to the other services through the API, not by hitting the key/value store directly.
The Task Queue in this diagram is just a simple in-memory queue for handing out the jobs for periodic query processing to any number of workers.
Our query processing tier in this diagram is decoupled from the storage tier. This makes it horizontally scalable, highly elastic, and gives us greater control to achieve tenant and resource isolation for query workloads (which are all design goals for our new IFQL query engine). This also makes it easy to isolate interactive queries issued by users from background queries that run periodically.
Putting It Together in Go
Now that we’ve laid out the basics of what we think we’d like to move to in the services model, let’s put together a code organization structure that would let us break things apart later. This code will merely be a sketch of the idea. I’ll stick primarily to using interfaces and structs with some hand waving in the middle. For a great primer on organizing a Go codebase, read Ben Johnson’s excellent writeup on Structuring Applications in Go.
We’re going to break down the application into a directory/package structure like this:
influx/
cmd/
influx-mono/
main.go
influx-service-based/
main.go
tsdb/
in-memory/
local-disk/
service/
kvstore/
in-memory/
bolt/
etcd/
taskq
in-memory/
nats/
stream
in-memory/
service/
server.go
api.protoWe have influx as the top-level package. There are sub packages for some of the concepts in the architecture diagram. The cmd package is where we’ll keep the main runner programs that initialize each implementation of the API. The implementations and runners of the services would live in their own repos. Meanwhile, the service directories in this repo like tsdb/service would import the client library for that service and implement whatever wrapper the API would need to interact with it to conform to the expected interfaces. One design consideration for these internal APIs is that the exported functions will be expected to move from in-process monolith implementation to services. So consider that they may be passing network boundaries and need to think about how chatty they are.
The API definition, server and all other logic related to implementing this APIregardless of which service is usedwould exist in the top-level directory. Let’s look at the interfaces and some shell code that would go into service.go:
// Time series storage interfaces
// Writer writes time series data to the store
type Writer interface {
Write(context.Context, WriteRequest) error
}
// Querier will execute a query against the store
type Querier interface {
Query(context.Context, QueryRequest) (<-chan QueryResponse, error)
}
// Note that the functions on all interfaces take context objects.
// This is intentional because they could either be in-process/in-memory
// implementations or they could be network services.
// Key/value storage interface
type Key []byte
type Value []byte
type Pair struct {
Key Key
Value Value
}
type KVStorer interface {
Put(context.Context, []Pair) error
Get(context.Context, Key) (Value, error)
Delete(context.Context, Key) error
RangeScan(context.Context, Key) (KVScanner, error)
}
type KVScanner interface {
Next() ([]Pair, error)
}
// Tasker is an interface for running periodic query tasks
type Tasker interface {
Queue(context.Context, PeriodicQuery) error
Stop(context.Context, PeriodicQuery) error
Status(context.Context, PeriodicQuery) (PeriodicQueryStatus, error)
}
// Server implements the gRPC API
type Server struct{}
// NewServer takes interfaces for initialization so they can
// be replaced with local in process implementations or services
// that call over the network.
func NewServer(w Writer, q Querier, store KVStorer) *Server {}In a fully functioning example, there would certainly be more code and more packages, but this skeleton should give us enough to illustrate the idea. The server struct is where all our code for working with the API and business logic exists.
Note that for initializing it, we take interfaces defined in this package. This is one of those Go concepts that took me a little while to internalize: consumers should define interfaces, not the implementations. It’s backwards from how you think about things in Java. Taking that concept, we can have different implementations for these interfaces.
In the early monolith, only the in-memory or local-disk implementations would be used. I added in-memory to show that you could have a simple test implementation that doesn’t persist anything. Or in some cases, like the tasker, you may want to use in-memory in the monolithic app since periodic tasks can be reloaded from the KVStore on startup.
For the writer interface that takes the time series data, the local tsdb can act as both the writer and the querier interfaces. Later, when pulling things out into services, each part can be implemented separately. A thin wrapper around Kafka could act as the writer while a horizontally scalable service of IFQL query services could be used for the querier.
The implementations in this repo of those individual components wouldn’t implement the service. They would only be responsible for wrapping the client to the service to ensure that it conforms to the interface and adds any other kind of monitoring and observability hooks that we’d need in a distributed system.
One of the design goals is to have services that are lower-level building blocks. This makes it easier to use thin wrappers around other well-known projects like etcd, Nats.io, or even cloud- based services available in AWS, Google Cloud, or Azure. Within the cmd directory, each different runner would initialize the server instance with the implementations that either use in-process single server implementations, or services, or some other mix.
Conclusion
Designing your monolith up-front while thinking about services could give you the ability to build a monolith to start with the ability to expand to services later. I think this might lend itself to better feature velocity early on, with the advantage of having both implementations later.
The drawback is that once you’ve created the services-based solution, it becomes a maintenance task to keep the monolith up to date. We’re currently evaluating doing something like this with our next-generation platform and cloud product, but it’s still very early. Yet the ability to have both a monolithic application (which many of our users want) and a more scalable services one within the same code base is very appealing.
One of my colleagues that reviewed this post noted that this didn’t seem like decomposing a monolith so much as it was just API driven design. You create a user facing API that is useful and has a fixed contract and that frees you up to iterate beneath the surface. However, the way I think about this is slightly different. Normally when you replace a monolith you do almost a complete rewrite below the API level. My goal with this approach is to think ahead of time about how components will be pulled out into services and design the monolith’s codebase so that lower level components and libraries beneath the API can be replaced with services.
