Flight, DataFusion, Arrow, and Parquet: Using the FDAP Architecture to build InfluxDB 3.0
By
Andrew Lamb
updated February 21, 2024
Developer
Navigate to:
This article coins the term “FDAP stack”, explains why we used it to build InfluxDB 3.0, and argues that it will enable and power a generation of analytics applications in the same way that the LAMP stack enabled and powered a generation of interactive websites (by the way we are hiring!).
Background
When he announced the InfluxDB IOx project, InfluxData founder Paul Dix effectively bet that the FDAP stack would form the future foundation of analytic systems. Several years later, this prediction is proving ever more prescient.
The need for new analytic systems such as databases, data prep pipelines, and ETL/ELT tools grows with the exponential growth of data to manage (estimated to be 463 exabytes per day by 2025). One size does not fit all for data system design and systems focused on particular data types, such as time series, robotic logs, or financial transactions, can be 10–100x faster and more efficient (and therefore less expensive) than monolithic data platforms.
However, until the last five years, there was a notable lack of reusable components for building data-centric systems. This forced system designers to continually re-implement (and retest, and maintain) many complex, but by now well understood, systems techniques. The Flight, DataFusion, Arrow, and Parquet, (FDAP) stack, finally permits us to build new systems without such reinvention, resulting in more features and better performance than legacy designs.

Figure 1: Relative investment for building analytic systems, where the size of each colored box represents the relative effort invested. A tightly integrated system (left) has fewer domain-specific features (smaller pink box) because it must reimplement many complex, low-level, but undifferentiated components (orange boxes) with the same budget. With an FDAP-based system (right), the FDAP components (blue) are free, which results in more features (larger pink box) and each individual component is better than a custom reimplementation.
The FDAP stack
This section describes the technologies of the FDAP stack, and why we chose them for InfluxDB 3.0.
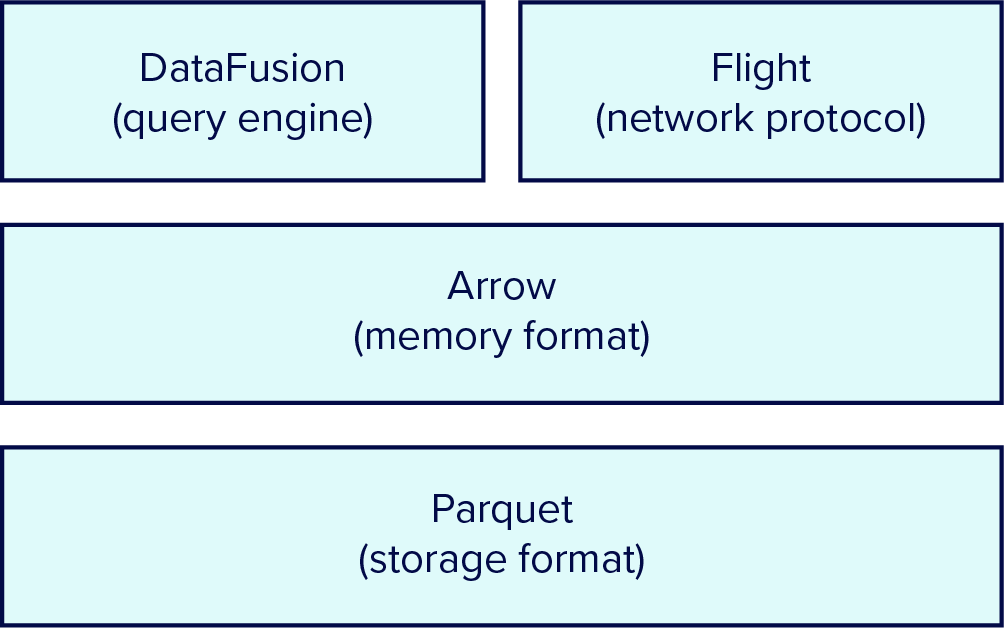
Figure 2: The FDAP Stack: Flight provides efficient and interoperable network data transfer. DataFusion provides data access via queries and execution operators. Arrow provides an efficient memory representation and fast computation. Parquet provides well-compressed, high performance storage.
Arrow
To process data, a system must represent the data in main memory in a format amenable for processing. When implementing InfluxDB 3.0, we chose to use Apache Arrow for this purpose due to its efficiency, performance, open libraries, and broad open ecosystem.
By using Arrow we:
- Sidestepped the mundane (but important) definition, implementation, and maintenance of details such as memory layouts, validity / null representations, endianness, variable length data storage, timestamp/duration representation, dictionaries, and hierarchical data types.
- Avoided runtime overhead of translating an internal memory representation to a format suitable for other libraries and systems, such as writing Parquet files or providing data to a Python script.
At its core, Arrow simply standardizes data representation in-memory, using best practice, cache-efficient, columnar layouts. If you find yourself worrying about details such as how to represent nulls (as a bitmask? Does 1 mean null or valid?), how to efficiently compare multiple columns, or how to best vectorize low-level filtering operations of varying selectivity, you probably should be using Arrow and its libraries.
When we began using the Rust implementation of Arrow, arrow-rs, it was relatively new. Over time, InfluxData and many other contributors invested significant time and expertise to make it one of the best Arrow implementations, including many highly-optimized computation kernels, fast comparisons via normalized keys, and complete type support. It is unlikely InfluxDB 3.0 would have such features if we tried to reimplement this all ourselves.
Flight
InfluxDB 3.0, like many databases designed for cloud operation, consists of several services that communicate with each other as well as clients over network links. We chose Apache Arrow Flight for much of this communication, both within the cluster and when communicating to/from clients. Flight is a protocol for sending Arrow arrays quickly across the network using a gRPC-based API.
Using Flight saved us from having to:
- Define our own efficient network protocol (for which I am glad, given there is ample evidence that creating such efficient protocols is non-trivial)
- Implement that protocol in multiple languages: Rust on the server, and then individual implementations for each client language (Rust, Golang, Python, and Java at the time of this writing).
Adding a new language client to InfluxDB 3.0 has been straightforward: we simply build the new client on top of an existing Flight client for that language (there are at least thirteen!), which takes care of the heavy lifting.

Figure 2.5: Arrow Flight handles all the low-level details of sending Arrow arrays over the network quickly and efficiently, in a streaming fashion, with no transcoding overhead. The InfluxDB 3.0 server provides Arrow arrays and the client gets Arrow arrays.
Additionally, we implemented the Arrow FlightSQL protocol, on top of Flight, which lets InfluxDB 3.0 work in the SQL-based ecosystem. There are clients for FlightSQL that implement popular interfaces such as JDBC, ODBC, and Python DBI, which we can use without modification. Unlike other systems I have worked on, InfluxDB 3.0 does not have a client driver team and likely won’t need one, thanks to Flight and FlightSQL. (By the way, if you don’t understand why implementing a JDBC or ODBC driver is so complex and nuanced it often takes a whole team of developers, consider yourself lucky.)

Figure 2.6: By implementing the Arrow FlightSQL API, InfluxDB 3.0 gets access to pre-existing client interfaces, such as JDBC, without having to create and maintain those drivers.
Parquet
In addition to Arrow for fast random access for in-memory processing, InfluxDB 3.0 needs to store large amounts of time series data in a space-efficient (economical) manner. The storage format must also support very fast queries. While first generation time series databases such as Gorilla, Monarch, and InfluxDB 1.x store time series data in custom formats specialized for time series, InfluxDB 3.0 instead uses the more general purpose Apache Parquet. In our testing, Parquet actually offered 5x better compression1 than more specialized time series file formats (once all index structures are taken into account), very fast query performance, and immediate interoperability with the vast array of tools that support Parquet files, such as Pandas, DuckDB, Spark, and Snowflake.
Parquet is an open, column-oriented data file format, heavily influenced by academic research in columnar storage. The format provides excellent data encoding and compression, efficient structured types via Dremel-style record shredding, embedded schema descriptions, and zone map-like metadata (statistics and bloom filters). If you don’t know what those terms mean, that is both OK and one of the key points. By using Parquet you get the benefits of these features without needing a database PhD or years of study to rediscover and reimplement the required techniques.
I am sure, with sufficient cleverness and engineering investment, specialized formats for time series (and other data types) can achieve slightly better compression and performance than Parquet. However, in practice I predict the existence of highly optimized Parquet implementations and the widespread adoption of Parquet files will relegate specialized formats to niche applications, much like what happened with JPEG2000.
DataFusion
InfluxDB 3.0 needs to quickly accept data and make it readable, and permit access to that data via queries. The ingest path has highly specialized requirements for the time series use case, but the query path looks much more like other OLAP systems, requiring support for SQL and the SQL-inspired InfluxQL (our language built for time series), predicate analysis to identify required time ranges for each query, as well as a streaming vectorized execution engine. From my personal experience working on several other databases, the scope of features required for such an engine requires effort measured in 10s of person-years to fully understand, let alone to implement and maintain. InfluxData knew this too, after investing similar orders of magnitude implementing both InfluxDB 1.x and the Flux language.
Instead of building another engine by ourselves, we chose to build on Apache Arrow DataFusion, a modular, state-of-the-art analytic query engine written in Rust, that uses Apache Arrow as its memory model. With just a few lines of code, Paul validated that DataFusion could quickly query time series data using SQL. We then built an InfluxQL frontend, custom operators for late arrival resolution (“deduplication”), time series gap filling, initially writing Parquet files, and merging multiple files together on top of DataFusion using its extension points. In our cloud environment, we were also able to power the Flux language with the same engine.

Figure 3: Query processing in InfluxDB 3.0 uses DataFusion to query data via three different language frontends (an internal gRPC API, SQL, and InfluxQL) as well as write and merge Parquet files (“reorg”).
Just like Arrow, as InfluxData and others in the community invest in DataFusion, its capabilities grow, magnified manyfold over what any one of us could hope to achieve on our own. DataFusion now features almost all the buzzwords you could hope for in a modern OLAP engine such as streaming vectorized execution, projection and selection/filter pushdown, automatic parallelization, resource management, query optimizations, subqueries, joins, multi-phase grouping, Python bindings, and more. No specific feature in DataFusion is “new”; instead the innovation is in how they are packaged to be reused, which we hope to explain more fully in a future paper.
Benefits of the FDAP stack
At the risk of sounding repetitive, here are the benefits InfluxDB 3.0 got building with the FDAP stack. I strongly believe other system designers can realize these benefits using the same stack.
Focus on what matters: By building on FDAP, the InfluxData 3.0 team focuses our efforts on time series-specific features, such as ingestion performance, InfluxQL, distributed operation and deployment, and very low latency recent data queries, rather than low-level, complex table stakes OLAP technology.
Integration and Interoperability: Because InfluxDB 3.0 uses open standards as its native data representations, integration becomes almost trivial. Rather than a N-to-N explosion of system-to-system integrations, InfluxDB 3.0 gets JDBC support “for free” by using Arrow FlightSQL, has very simple but full-featured native Python and golang clients, and query results that can instantly be used by anything that accepts Arrow (such as Pandas or Spark). Because InfluxDB natively stores data as Parquet files, other systems, such as Snowflake or Presto, can query it without creating or maintaining complex ETL / data pipelines.

Figure 4: The open data formats of FDAP provide instant interoperability with a broad range of existing products and technologies.
Amplified Investment: The technology behind the FDAP stack is complex, and there are a limited number of people with the skills and time to develop and maintain it. By joining forces with other projects that share the same needs, under the Apache Software Foundation, the open source development model allows a large, world wide pool of developers to work together on Flight, Arrow, DataFusion and Parquet. Anecdotally, I spent almost four years of my life on SQL JOINs nuances so Vertica could plan and run them efficiently. By building on the FDAP stack, InfluxDB 3.0 has SQL JOINs almost “for free”2.
Predictable, Open Standards: In addition to the benefits of shared investment, working within the Apache Software Foundation means that InfluxDB 3.0 is built on projects with well understood, predictable decision making, are not subject to mid-life license changes, single maintainer burnout, or other sources of uncertainty that can plague other similar open source projects.
FDAP in action
In addition to InfluxDB 3.0, there are several other systems we know of that utilize this architecture in production, including
- CeresDB: Distributed, cloud-native time series database.
- Coralogix: Full stack observability platform
- Greptime: Cloud-native time series database
- Synnada: Unified streaming and analytics platform
- OpenObserve: Observability platform built specifically for logs, metrics, and traces
- Dremio: Data-as-a-service platform
(Side note: it would be really interesting if these other projects could describe in more detail how they use the components of the FDAP stack and their perception of the benefits of doing so.)
Related work
The emergence of the FDAP technologies is due to ideas first published in database systems research, and the collective experience of implementing several waves of commercial and open source systems. The first wave started in the early 2000s, as exemplified by systems like Vertica and Vectorwise. The concepts were subsequently refined, reimplemented, and partially standardized by Hadoop-based systems such as Impala and Hive. Finally, they have been reimplemented yet again in contemporary systems such as Spark, Snowflake, and DuckDB, solidifying the understanding of the common structures.
I believe that the FDAP stack will play the same role in underpinning next generation data systems that the LAMP stack played in underpinning first generation web application development. The LAMP stack’s combination of easy composability, fast performance, and shared, open development, allowed early web application developers to focus on application logic rather than backend servers, state management, and the details of serving http requests (anyone else remember how much fun it was to implement the cgi-bin interface?).
Looking toward the future
Paul and I are not the only ones writing about the shift to composability in data systems. Notable recent writings include Voltron Data’s Composable Codex and The Composable Data Management System Manifesto, both of which eloquently express the value of composability in greater detail.
While DataFusion is written in Rust, and thus is easiest to integrate into projects also written in Rust, similar tools exist for other languages. Apache Calcite is a Java-based project for SQL planning and optimization, and the Velox Execution engine provides a native streaming, vectorized C/C++ engine. We predict that other projects, similar to DataFusion, will emerge for different languages, though perhaps DataFusion language bindings will be sufficient. In addition, DataFusion and similar projects themselves will also likely undergo componentization internally as new open standards, such as Substrait, mature and define new boundaries for interoperability.
Conclusion
Unless you have unlimited resources and/or an extremely specialized use case, I think you will be hard pressed to implement something anywhere near as good as what the FDAP offers. I predict that as more people also come to this conclusion, we will see a new wave of systems built on the FDAP stack and I for one can not wait to see what emerges.
To get involved with the various FDAP technologies, visit: https://arrow.apache.org/ https://parquet.apache.org/ https://arrow.apache.org/datafusion/
Want to see what these technologies can do when combined? Check out the new InfluxDB.
Acknowledgements
Thanks to Evan Kaplan for proposing this post and encouraging me to write it. Also my many thanks to Jason Myers and Charles Mahler for their help drafting and refining this article and to Paul Dix and Nga Tran who reviewed early drafts and provided valuable feedback.
