Getting Started with C++ and InfluxDB
By
Community
updated December 14, 2025
Product
Use Cases
Developer
Navigate to:
This article was written by Pravin Kumar Sinha and was originally published by The New Stack. Scroll down for the author’s bio.
While relational database management systems (RDBMS) are efficient with storing tables, columns, and primary keys in a spreadsheet architecture, they become inefficient when there’s a lot of data input received over a long period of time.
Databases designed specifically to store time series data are known as time series databases (TSDB).
For example, an RDBMS might look like this:
------------------------------------------------------------------
| Id | Name | Age | Phonenumber | email |
------------------------------------------------------------------
| 0 | Jonn | 26 | xxxxxx | [email protected] |
| 1 | Susan | 44 | xxxxxx | [email protected] |
| 2 | Alice | 19 | xxxxxx | [email protected] |
| 3 | Jennifer | 32 | xxxxxx | [email protected] |
---------------------------------------------------------------------In a TSDB, data is categorized in measurements. A measurement is a container, roughly equivalent to a table in RDBMS, which contains tuples of time and field data. Each entry is a tuple of (time, field data) and is recognized as a point. A point can optionally include a string tag.
A TSDB might look more like this:
----------------------------------------------------
| Tag | Field | Timestamp |
|city device name | temperature | |
------------------------------------------------------------------
|HUSTON deviceX | 23 | 2021-11-20T12-31-18.865954 |
|MIAMI deviceX | 26 | 2021-11-20T12-31-18.965954 |
|MIAMI deviceY | 23 | 2021-11-20T12-31-19.965954 |
|SEATTLE deviceY | 18 | 2021-11-20T12-31-19.965954 |
|SEATTLE deviceZ | 19 | 2021-11-20T12-31-20.814952 |
|ATLANTA deviceA | 20 | 2021-11-20T12-31-21.665954 |
|DALLAS deviceC | 28 | 2021-11-20T12-31-22.485954 |
------------------------------------------------------------------The sample TSDB shown above stores temperature (measurement) and value (field data) measured across various cities (tag) during a range of time (timestamp), measured through devices (tag) manufactured from more than one company.
But TSDBs can facilitate the continuous monitoring of a variety of data, like IoT sensors, market trading data, and stock exchange data. This article shows you how to set up, configure, connect, write, and query an InfluxDB database using a C++ library.
InfluxDB is an open source time series database built to handle high write and read/query timestamped data loads. In addition to providing a constant stream of data, like server metrics or application monitoring, InfluxDB also provides events generation, real-time analytics, automatic expiration and deletion of backed-up stored data, and easy ways to forecast and analyze time series data.
You’ll learn how to store real IoT sensor data in an InfluxDB database and then analyze the stored data as a block of time period samples. We’ll finish off by plotting the data in a graph.
Setting up the InfluxDB server
This tutorial is set up on Ubuntu 20.04 LTS, but you can find other installation support in InfluxDB’s documentation. You can follow along with the source code for this tutorial here.
sudo apt-get install influxdb
sudo systemctl start influxdb
sudo systemctl status influxdbsystemctl status influxdb should show the running status:
influxdb.service - InfluxDB is an open-source, distributed, time series database
Loaded: loaded (/lib/systemd/system/influxdb.service; enabled; vendor preset: enabled)
Active: active (running) since Sat 2021-11-20 14:24:56 IST; 39s ago
Docs: man:influxd(1)
Main PID: 23892 (influxd)
Tasks: 13 (limit: 4505)
Memory: 4.5M
CGroup: /system.slice/influxdb.service
??23892 /usr/bin/influxd -config /etc/influxdb/influxdb.confThe InfluxDB server version for this tutorial is 1.6.4. You can get more information about server configuration by running $influxd, and tweak your configuration with /etc/influxdb/influxdb.conf.
Setting up the influxdb-cxx C++ client library
This tutorial uses the influxdb-cxx client library, version 0.6.7, to connect, populate, and query the InfluxDB server. The InfluxDB server is listening at IP address 127.0.0.1 and at TCP port 8086.
Prerequisites
As mentioned earlier, this tutorial is set up on Ubuntu 20.04 LTS. The rest of the software dependency list is as follows:
- C++ 17 compiler. You can install g++ 9.3.0 through
sudo apt-get install g++. - CMake 3.12+ tool. You can install CMake 3.16.3 through
sudo apt-get install cmake. - Curl library. You can install curl4-openssl through
sudo apt-get install libcurl4-openssl-dev. - Boost 1.57+ library (optional). Install Boost 1.71 c through
sudo apt-get install libboost1.71-all-dev.
Get the influxdb-cxx client library
Create a new directory and execute the following command:
git clone https://github.com/offa/influxdb-cxx
Build the influxdb-cxx client library
cd influxdb-cxx
mkdir build && cd buildWhen the testing suite is not required, you can set the following options to OFF while running cmake.
cmake -D INFLUXCXX_TESTING:BOOL=OFF ..
Install the influxdb-cxx client library
sudo make install
The client library builds libInfluxDB.so and installs at /usr/local/lib/libInfluxDB.so. Header files InfluxDBFactory.h, InfluxDB., Point.h, Transport.h are installed at /usr/local/include/.
Header files and library files are required while compiling and linking the source code respectively.
The C++ application uses libInfluxDB.so while linking in order to generate an executable binary.

The influxdb-cxx client library class design
The influxdb-cxx client is designed to interact with the InfluxDB server through class InfluxDB. All influxdb-cxx classes are defined under the global namespace influxdb.

The InfluxDBFactory class provides the get() method, which accepts a URI string with information on IP address, port with optional protocol name, database name, database user, and password. The HTTP URI defaults to tcp. InfluxDBFactory returns the InfluxDB class, which is connected to the InfluxDB server.
The InfluxDB class then provides methods to create the database, write to the database, and query the database. The InfluxDB class writes a point (or list of points) to the database – the point class represents a measurement container.
Since a measurement container contains tag, field, and timestamp, the point class provides methods for adding tag, field, and timestamp to itself. Calling the write() method on the InfluxDB class with point as an argument, first serialize the point class data as per Line protocol rules.
Final line protocol data is then sent to the InfluxDB server. Batch mode is also supported by the InfluxDB class, where the batchOf() method specifies the batch size. The addPointToBatch() method takes the list of points to be added, and the flushBatch() method finally writes to the database.
Making a connection
The InfluxDBFactory.get() method is called with a URI string to create a connection with the InfluxDB server. Specify the URI as: [protocol]://[username:password@]host:port[?db=database]
For example, you can call the get() method as influxdb::InfluxDBFactory::Get("http://localhost:8086?db=temperature_db").
Here, HTTP (TCP) is the protocol, localhost (127.0.0.1) is the IP address, 8086 is the TCP port, and temperature_db is the database name. You can use HTTP (TCP), UDP, and Unix Socket as protocol. The IP address, protocol, username, password, port number, and database name can also be configured through the configuration file /etc/influxdb/influxdb.conf.
In this example, you can make a connection by specifying the database name. Create the database if it doesn’t exist.
auto db = influxdb::InfluxDBFactory::Get("http://localhost:8086?db=temperature_db");
db->createDatabaseIfNotExists();#include <iostream>
#include <InfluxDBFactory.h>
int main(int argc,char *argv[]) {
auto db = influxdb::InfluxDBFactory::Get("http://localhost:8086?db=temperature_db");
db->createDatabaseIfNotExists();
for (auto i: db->query("SHOW DATABASES")) std::cout<<i.getTags()<<std::endl;
return 0;
}Compiling, linking, and creating the executable
In a new directory, create a file called CMakeLists.txt.
mkdir cxx-influxdb-example && cd cxx-influxdb-example
Add the following lines to CMakeLists.txt.
cmake_minimum_required(VERSION 3.12.0)
project(cxx-influxdb-example)
find_package(InfluxDB)
add_executable(example-influx-cxx main.cpp)
target_link_libraries(example-influx-cxx PRIVATE InfluxData::InfluxDB)cxx-influxdb-example is the project name, whereas example-influx-cxx is the executable name.
Write your main.cpp code, including the influxdb-cxx client header files.
mkdir build && cd build
cmake ..
make
./example-influx-cxxOutput:
name=_internal
name=temperature_dbConnecting with SSL/TLS
HTTP is disabled by default. You’ll need to purchase an SSL key and certificate. Modify configuration file
/etc/influxdb/influxdb.conf
and modify or add the following key value pairs:
https-enabled=true
https-certificate=/etc/ssl/<signed-certificate-file>.crt (or to /etc/ssl/<bundled-certificate-file>.pem)
https-private-key=/etc/ssl/<private-key-file>.key (or to /etc/ssl/<bundled-certificate-file>.pemNext, run the following command:
$sudo chown influxdb:influxdb /etc/ssl/<CA-certificate-file>
$sudo chmod 644 /etc/ssl/<CA-certificate-file>
$sudo chmod 600 /etc/ssl/<private-key-file>
$sudo systemctl restart influxdbYou can specify https instead of http in the InfluxDBFactory.get() URI argument to get TLS(SSL) encryption.
influxdb::InfluxDBFactory::Get("https://localhost:8086?db=temperature_db");
Writing to the InfluxDB database
The InfluxDB database is organized into various measurements. As mentioned earlier, a measurement is like a container and is equivalent to tables in an RDBMS. Each measurement record is a point which is a tuple of (measurement, tag, field value, time).
Measurement - String
Tag name,value - String
Field name - String
Filed value - String, Integer, Float and Boolean
Timestamp - Unix nanosecond timestampsYou can write a point to the database with InfluxDB.write() method by specifying measurement name, tag name, value pair list (optional), field name, value pair list, and timestamp (optional). A missing timestamp would be added by the InfluxDB database server.
auto db = influxdb::InfluxDBFactory::Get("http://localhost:8086?db=temperature_db");
db->write(influxdb::Point{"temperature"}.addTag("city","DALLAS").addTag("device","companyX").addField("value",28));Querying data
You can query InfluxDB by calling the InfluxDB.query() method and passing the SQL query string as an argument. Database records in InfluxDB are returned in JSON format, where each record is represented by point class. Point.getName(), Point.getTags(), Point.getFields() and Point.getTimestamp() retun measurement, tag, field and timestamp respectively.
#include <iostream>
#include <InfluxDBFactory.h>
int main(int argc,char *argv[]) {
auto db = influxdb::InfluxDBFactory::Get("http://localhost:8086?db=temperature_db");
for (auto i: db->query("select * from temperature")) {
std::cout<<i.getName()<<":";
std::cout<<i.getTags()<<":";
std::cout<<i.getFields()<<":";
std::cout<<std::to_string(std::chrono::duration_cast<std::chrono::nanoseconds>(i.getTimestamp().time_since_epoch()).count())<<std::endl;
}
return 0;
}Output:
temperature:city=DALLAS,device=companyX:value=28.000000000000000000:1637659246724538477
You can set float type precision by setting influxdb::Point::floatsPrecision=4.
int main(int argc,char *argv[]) {
auto db = influxdb::InfluxDBFactory::Get("http://localhost:8086?db=temperature_db");
influxdb::Point::floatsPrecision=4;Output:
temperature:city=DALLAS,device=companyX:value=28.0000:1637659246724538477
Writing to InfluxDB in a batch
You can write data in a batch after mentioning the batch size. Call the flushBatch() method to flush the data to the database.
#include <iostream>
#include <InfluxDBFactory.h>
int main(int argc,char *argv[]) {
auto db = influxdb::InfluxDBFactory::Get("http://localhost:8086?db=temperature_db");
influxdb::Point::floatsPrecision=4;
db->batchOf(10);
for (int i=0;i<10;i++)
db->write(influxdb::Point{"temperature"}.addTag("city","SEATTLE").addTag("device","companyY").addField("value",28+i));
db->flushBatch();
return 0;
}Debugging with the influxdb-client utility
You can also verify data available in InfluxDB through the influxdb-client utility available on Ubuntu 20.04 through $sudo apt-get install influxdb-client.
$ influx
Connected to http://localhost:8086 version 1.6.4
InfluxDB shell version: 1.6.4
> SHOW DATABASES
name: databases
name
----
_internal
temperature_db
> use temperature_db
Using database temperature_db
> SELECT * FROM temperature
name: temperature
time city device value
---- ---- ------ -----
1637661663965328258 SEATTLE companyY 28
1637661663965352861 SEATTLE companyY 29
1637661663965357288 SEATTLE companyY 30
.....The finished application
The complete program is as follows:
#include <iostream>
#include <InfluxDBFactory.h>
int main(int argc,char *argv[]) {
auto db = influxdb::InfluxDBFactory::Get("http://localhost:8086?db=temperature_db");
influxdb::Point::floatsPrecision=4;
db->createDatabaseIfNotExists();
for (auto i: db->query("SHOW DATABASES")) std::cout<<i.getTags()<<std::endl;
db->write(influxdb::Point{"temperature"}.addTag("city","DALLAS").addTag("device","companyX").addField("value",28));
db->batchOf(10);
for (int i=0;i<10;i++)
db->write(influxdb::Point{"temperature"}.addTag("city","SEATTLE").addTag("device","companyY").addField("value",28+i));
db->flushBatch();
for (auto i: db->query("select * from temperature")) {
std::cout<<i.getName()<<":";
std::cout<<i.getTags()<<":";
std::cout<<i.getFields()<<":";
std::cout<<std::to_string(std::chrono::duration_cast<std::chrono::nanoseconds>(i.getTimestamp().time_since_epoch()).count())<<std::endl;
}
return 0;Real-time data from the experimental IoT sensor
The IoT sensor data measuring power, temperature, humidity, light, CO2, and dust is available at IoTSenser. Each data sample is recorded against a timestamp:
"2015-08-01 00:00:28",0,32,40,0,973,27.8
"2015-08-01 00:00:58",0,32,40,0,973,27.09
"2015-08-01 00:01:28",0,32,40,0,973,34.5
"2015-08-01 00:01:58",0,32,40,0,973,28.43
"2015-08-01 00:02:28",0,32,40,0,973,27.58
"2015-08-01 00:02:59",0,32,40,0,971,29.35
"2015-08-01 00:03:29",0,32,40,0,971,26.46
...In the example code, the database iotsensor_db is created with iotsensor as the measurement field.
The full code for inserting data in your database and plotting a graph is as follows. Also, note that the graph is drawn from the pbPlots utility available in the Cpp directory. The pbPlots.cpp, pbPlots.hpp, supportLib.cpp, and supportLib.hpp files are copied from the cxx-influxdb-example directory and added to the CMakeLists.txt file.
cmake_minimum_required(VERSION 3.12.0)
project(cxx-influxdb-example)
find_package(InfluxDB)
add_executable(example-influx-cxx supportLib.cpp pbPlots.cpp demomain.cpp)
target_link_libraries(example-influx-cxx PRIVATE InfluxData::InfluxDB)#include <iostream>
#include <string>
#include <fstream>
#include <boost/algorithm/string.hpp>
#include <InfluxDBFactory.h>
#include "pbPlots.h"
#include "supportLib.h"
#include <chrono>
std::chrono::system_clock::time_point createDateTime(int year, int month, int day, int hour, int minute, int second) // these are UTC values
{
tm timeinfo1 = tm();
timeinfo1.tm_year = year - 1900;
timeinfo1.tm_mon = month - 1;
timeinfo1.tm_mday = day;
timeinfo1.tm_hour = hour;
timeinfo1.tm_min = minute;
timeinfo1.tm_sec = second;
tm timeinfo = timeinfo1;
time_t tt = timegm(&timeinfo);
return std::chrono::system_clock::from_time_t(tt);
}
int main(int argc,char *argv[]) {
auto db = influxdb::InfluxDBFactory::Get("http://localhost:8086?db=iotsensor_db");
influxdb::Point::floatsPrecision=4;
db->createDatabaseIfNotExists();
for (auto i: db->query("SHOW DATABASES")) std::cout<<i.getTags()<<std::endl;
std::ifstream file("sensor-data.csv");
if (!file) {
std::cout<<"Unable to open file"<<std::endl;
return -1;
}
std::string dataline;
std::vector<std::string> sensordatavector, linevector, timestampvector;
while(getline(file,dataline)) {
dataline.erase(remove( dataline.begin(), dataline.end(), '\"' ),dataline.end());
sensordatavector.push_back(dataline);
}
std::cout<<"number of entries in sensor data "<<sensordatavector.size()<<std::endl;
auto t_start = std::chrono::high_resolution_clock::now();
db->batchOf(10000);
int counter=0;
for (std::string i : sensordatavector) {
boost::algorithm::split(linevector, i, boost::is_any_of(","));
boost::algorithm::split(timestampvector, linevector[0], boost::is_any_of(":- "));
std::chrono::system_clock::time_point tss=createDateTime(std::stod(timestampvector[0]),std::stod(timestampvector[1]),std::stod(timestampvector[2]),std::stod(timestampvector[3]),std::stod(timestampvector[4]),std::stod(timestampvector[5]));
db->write(influxdb::Point{"iotsensor"}
.addField("power",std::stod(linevector[1]))
.addField("temperature",std::stod(linevector[2]))
.addField("humidity",std::stod(linevector[3]))
.addField("light",std::stod(linevector[4]))
.addField("co2",std::stod(linevector[5]))
.addField("dust",std::stod(linevector[6]))
.setTimestamp(tss));
counter+=1;
if (counter==10000) {
db->flushBatch();
counter=0;
}
}
auto t_end = std::chrono::high_resolution_clock::now();
std::cout<<"Total time (ms) for write "<<std::chrono::duration<double, std::milli>(t_end-t_start).count()<<std::endl;
std::cout<<"database record count "<<db->query("select * from iotsensor").size()<<std::endl;
std::vector<double> doublevector;
std::vector<double> fieldvector[6];
std::vector<std::string> fieldnamevector;
sensordatavector.resize(0);linevector.resize(0);
// for (auto i: db->query("select * from iotsensor")) {
for (auto i: db->query("select * from iotsensor where time> '2015-08-04 00:00:00' and time<'2015-08-08 01:00:00'")) {
doublevector.push_back(std::chrono::duration_cast<std::chrono::nanoseconds>(i.getTimestamp().time_since_epoch()).count());
boost::algorithm::split(sensordatavector, i.getFields(), boost::is_any_of(","));
for (int j=0;j<6;j++) {
boost::algorithm::split(linevector, sensordatavector[j], boost::is_any_of("="));
fieldnamevector.push_back(linevector[0]);
fieldvector[j].push_back(std::stod(linevector[1]));
}
}
RGBABitmapImageReference *imageref=CreateRGBABitmapImageReference();
size_t length;
double *pngdata;
std::string filename;
for (int j=0;j<6;j++) {
DrawScatterPlot(imageref, 600, 400, &doublevector[0], doublevector.size(),&fieldvector[j][0],doublevector.size());
pngdata=ConvertToPNG(&length,imageref->image);
filename="plot_partial_"+fieldnamevector[j]+std::to_string(j)+".png";
WriteToFile(pngdata,length,(char*)filename.c_str());
}
return 0;
}Output:
name=_internal
name=temperature_db
name=iotsensor_db
number of entries in sensor data 88688
Total time (ms) for write 5874.81
database record count 79992It takes 5874.81 milliseconds to write 79992 points in a database where each point has six fields.
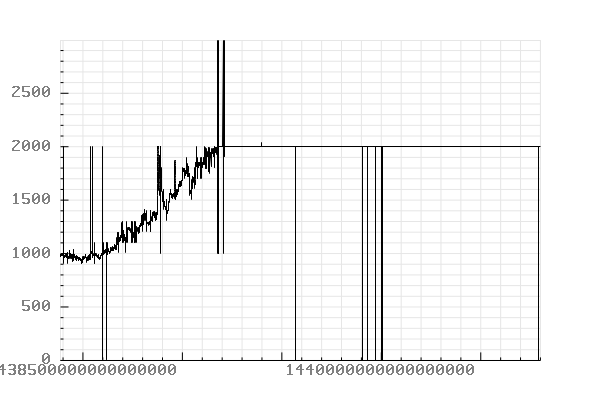
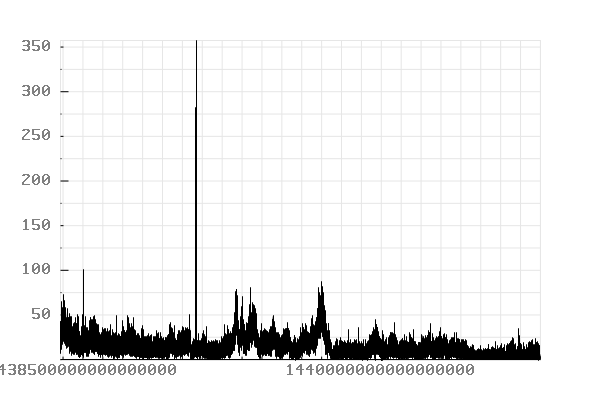
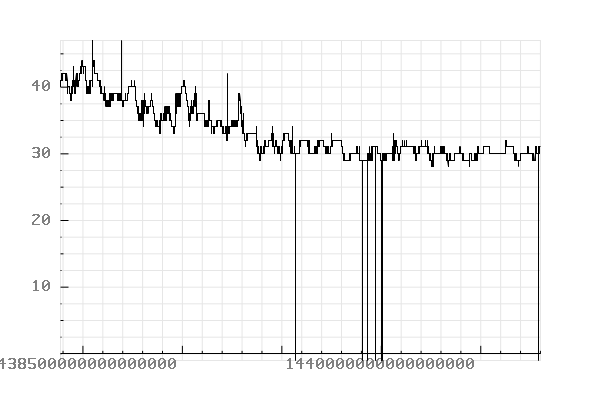
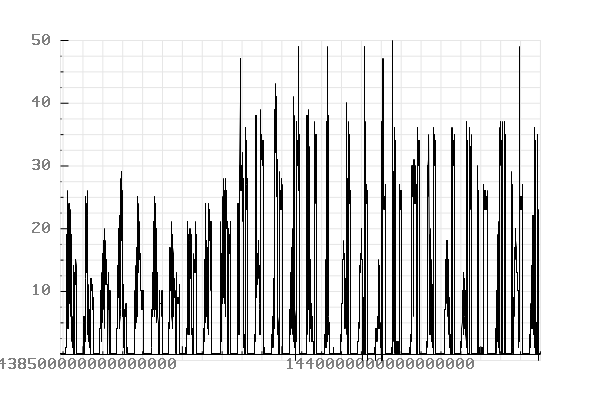

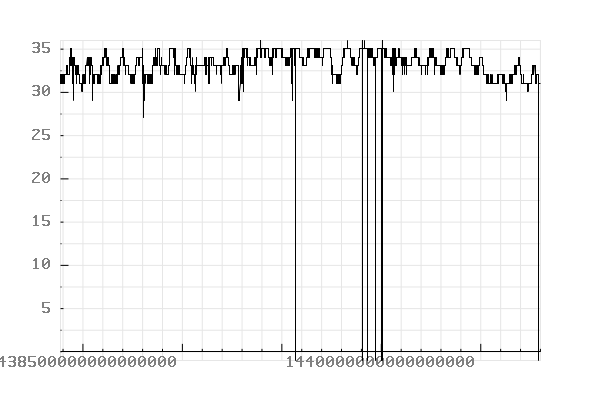
Records timestamped between “2015-08-04 00:00:00” and “2015-08-08 01:00:00”.
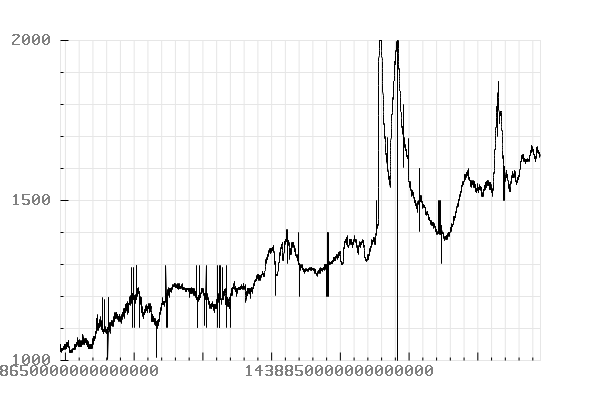
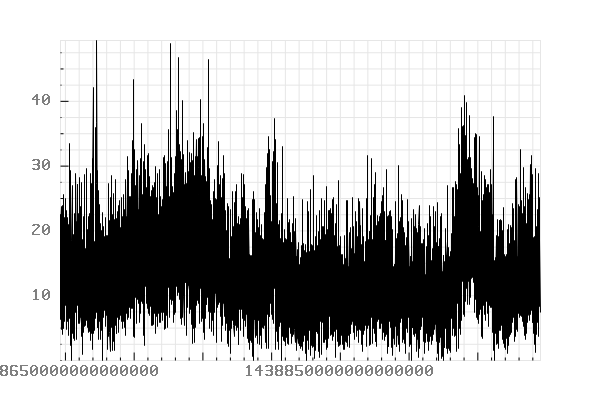
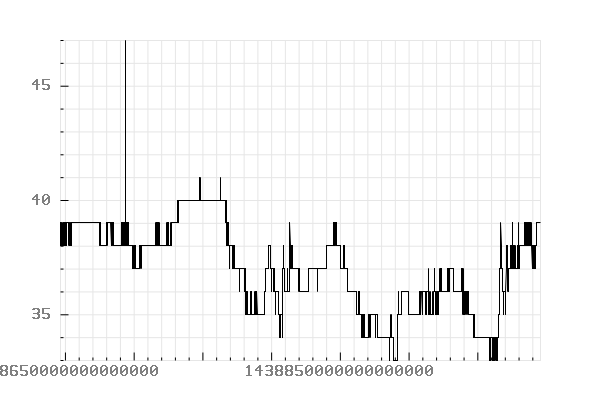
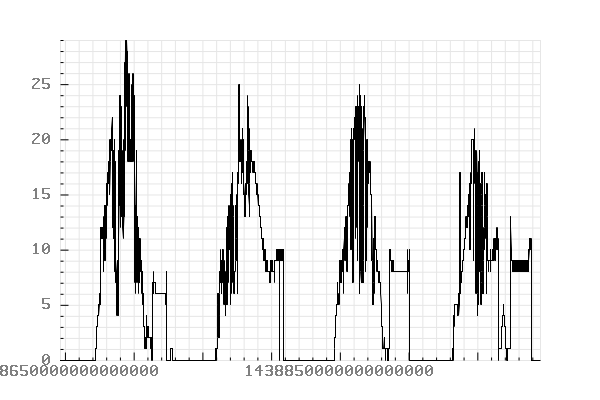

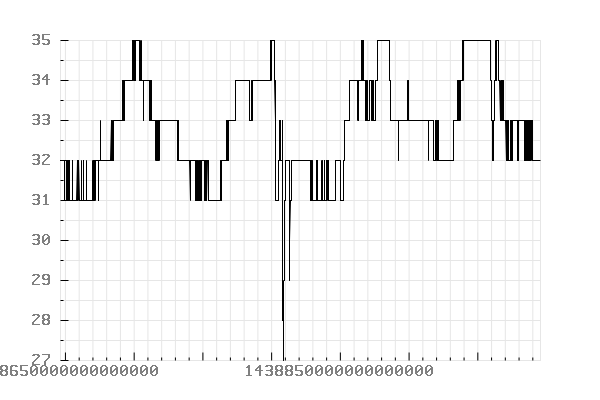
Conclusion
To recap, time series databases (TSDBs) are different from RDBMSes in the sense that a TSDB is highly specialized in backing up stored time series data. As a result, writing and querying the data happens at lightning speed.
For your own applications, check out InfluxDB, a database that provides metrics, events, and data analytics for time series data.
