Getting Started with Java and InfluxDB
By
Community
updated December 14, 2025
Product
Use Cases
Developer
Getting Started
Navigate to:
This article was written by Reshma Sathe. Scroll down for the author’s picture and bio.
Time series data is becoming vital, from IoT devices’ sensors to financial processing. The data collected from these sources can help in sales forecasting and making informed decisions about marketing and financial planning. In this article, you will learn about InfluxDB, one of the most efficient time series databases currently available, and explore how to use InfluxDB with Java.
Time series basics
As per statisticians, a time series is a collection of observations of well-defined data items obtained through repeated measurements over time. This data helps us to analyze and track the changes in data over time. A few sources of time series data include IoT device sensors, self-driving cars, temperature changes, stock market prices, and even daily rising and falling COVID-19 cases.
To understand why time series data is important, consider the following example:
Traditionally, organizations use the mean daily temperature (MDT) metric to track the changes in temperature over a period at a particular location. For a particular location, the daytime and nighttime temperatures or the environmental factors that cause temperature changes may vary drastically, but the MDT may change only slightly. Hence, the MDT does not give an accurate picture of the temperature change throughout the day. Instead, using time series data can provide an accurate picture of how the temperature changed hourly and under what particular conditions. It provides a clear picture of the environmental factors that caused the temperature changes like precipitation, cloud cover, wind speed, etc. All this information can help organizations better model and optimize energy utilization at their location.
Time series data is invaluable in providing deep and meaningful insights into the data available and helps build patterns. However, the amount of data required to build patterns is extensive and requires fast and reliable storage and retrieval for analysis. This is where time series databases (TSDBs) come in.
Time series database (TSDB)
A time series database is designed specifically for processing time series data. Time series data can be handled using “normal” databases, but TSDBs are preferred because of scale and usability.
- Scale: Time series data tends to grow exponentially. Most non-TSDBs are not optimized to handle this scale of change. Consequently, their performance deteriorates, severely affecting the analysis rate and overall application speed. TSDBs, however, are optimized for timestamp-based data and thus allow for lightning-fast insertion and retrieval queries for time series data.
- Usability: Since TSDBs are optimized to handle time series data, they come packaged with many built-in features like time aggregations, continuous queries, flexible retention policies, and more. A TSDB simplifies the analysis of trends and has more options.
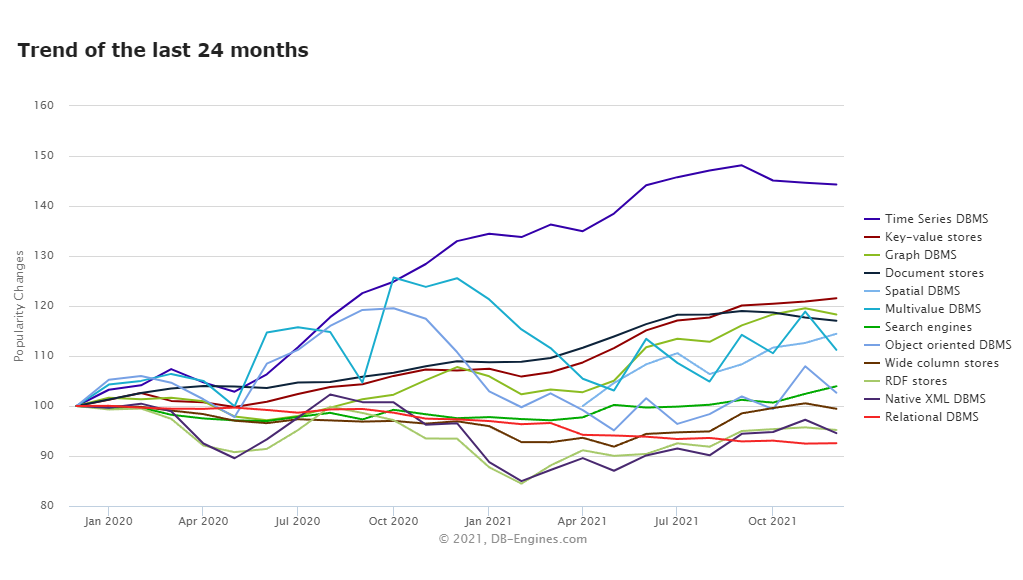
These are the main reasons why developers favor TSDBs. In fact, according to DB Engines, TSDBs are currently the fastest-growing segment of databases.
Why InfluxDB?
InfluxDB is a TSDB by InfluxData. It comes with features supporting the collection, storage, monitoring, and visualization of data, and also provides a time series data alert. InfluxDB supports microseconds and nanoseconds precision, which makes it the ideal choice for scientific and financial analysis.
It has excellent documentation, complete with syntax and examples for all its features. The newest version of InfluxDB 2.0 provides support for the entire Telegraf, InfluxDB, Chronograf and Kapacitor (TICK) stack.
InfluxDB comes with the Flux language, which, unlike SQL, is a functional language that makes it more verbose, readable, composable, and easier to test. Its creator, Paul Dix, gave this reason for its creation:
“I don’t want to live in a world where the best language humans could think of for working with data was invented in the ’70s.”
Since InfluxDB provides support for the TICK stack, the UI comes with “Alerting” and “Dashboard” features. There is also an integrated Query Builder, which reduces the developer’s workload.
InfluxDB Client Library
InfluxDB supports connecting with Java, Kotlin, Scala, Python, and many other programming languages. To connect to Java specifically, use the InfluxDB Client Java library. This client library replaces the earlier InfluxDB Java library. The complete documentation is available here.
The influxdb-client-java requires a Java version greater than 8.0 and InfluxDB version 2.0. Before you can begin using the client, you will need to install an InfluxDB instance. The instructions to set up InfluxDB can be found in its documentation.
Assuming InfluxDB is installed and set up on your system, the easiest way to include the InfluxDB client in your Java application is via Maven. The Maven dependency is as follows:
<dependency>
<groupId>com.influxdb</groupId>
<artifactId>influxdb-client-java</artifactId>
<version>3.3.0</version>
</dependency>The latest Maven dependency is available at the Maven repository.
Once InfluxDB is set up, and an instance is running, you can create a user, a bucket, and an organization on the UI. Alternatively, you can also use the Management API from the client.
Sample application
To better understand how to use the Influx Java client, review the following sample application. The sample application has two files:
App.javais the main application and makes all the calls.InfluxDBConnection.javamakes all the InfluxDB calls and has the token, bucket, and org as class members.
The application code is available on GitHub.
Making a connection
To create a connection using the Influx client, ensure that an InfluxDB instance is running on your system.
In a Java application, use the InfluxDBClientFactory Class’s create() method to make the connection. You will need to provide the URL, organization name, bucket, and token for this method.
To generate a token, go to the UI of your InfluxDB instance and log in with your user ID. To better understand how to use the InfluxDB UI, see the Set up InfluxDB through the UI section of the documentation.
Then navigate to the Data table and click Tokens. Here, you can generate a token for your user. The token generated is used for connecting to the InfluxDB instance.
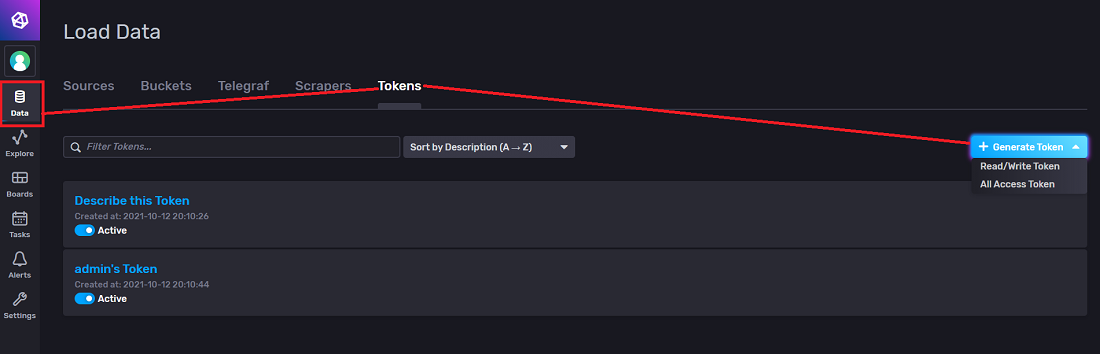
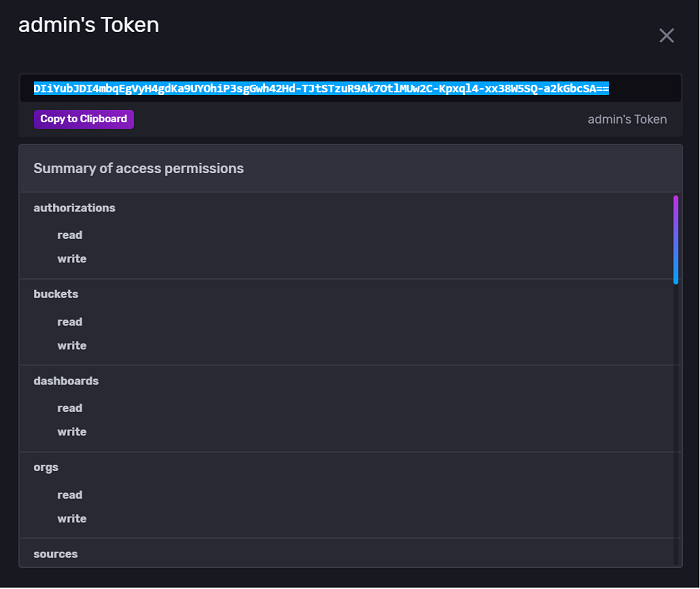
InfluxDB recommends that there is at least one “All Access” token that gives admin rights.
In the sample application, you can build the connection in the InfluxDBConnectionClass as follows:
public InfluxDBClient buildConnection(String url, String token, String bucket, String org) {
setToken(token);
setBucket(bucket);
setOrg(org);
setUrl(url);
return InfluxDBClientFactory.create(getUrl(), getToken().toCharArray(), getOrg(), getBucket());
}Inserting Data
The InfluxDB client can be either a Synchronous Blocking API or an Asynchronous Blocking API. For the Synchronous Blocking API, the InfluxDB client provides the WriteApiBlocking API.
Using the WriteApiBlocking, you can perform:
- Single data point insert
- Multiple points insert
- Insert using POJO
To initialize the WriteApiBlocking, use the following command:
WriteApiBlocking writeApi = influxDBClient.getWriteApiBlocking();Next, you can create a single data point and insert it into InfluxDB:
Point point = Point.measurement("sensor").addTag("sensor_id", "TLM0100").addField("location", "Main Lobby")
.addField("model_number", "TLM89092A")
.time(Instant.now(), WritePrecision.MS);
writeApi.writePoint(point);You can also build a list of multiple points and insert the list into InfluxDB:
WriteApiBlocking writeApi = influxDBClient.getWriteApiBlocking();
Point point1 = Point.measurement("sensor").addTag("sensor_id", "TLM0103")
.addField("location", "Mechanical Room").addField("model_number", "TLM90012Z")
.time(Instant.now(), WritePrecision.MS);
Point point2 = Point.measurement("sensor").addTag("sensor_id", "TLM0200")
.addField("location", "Conference Room").addField("model_number", "TLM89092B")
.time(Instant.now(), WritePrecision.MS);
Point point3 = Point.measurement("sensor").addTag("sensor_id", "TLM0201").addField("location", "Room 390")
.addField("model_number", "TLM89102B")
.time(Instant.now(), WritePrecision.MS);
List<Point> listPoint = new ArrayList<Point>();
listPoint.add(point1);
listPoint.add(point2);
listPoint.add(point3);
writeApi.writePoints(listPoint);Finally, you can also insert data using a POJO:
WriteApiBlocking writeApi = influxDBClient.getWriteApiBlocking();
Sensor sensor = new Sensor();
sensor.sensor_id = "TLM0101";
sensor.location = "Room 101";
sensor.model_number = "TLM89092A";
sensor.last_inspected = Instant.now();
writeApi.writeMeasurement(WritePrecision.MS, sensor);
flag = true;The Measurement is the POJO and needs to be defined as a class:
@Measurement(name = "sensor")
private static class Sensor {
@Column(tag = true)
String sensor_id;
@Column
String location;
@Column
String model_number;
@Column(timestamp = true)
Instant last_inspected;
}Querying data
InfluxDB provides Flux for querying data. To query the database, use the Query API and the query method to retrieve data. In the sample application, you will retrieve sensor data based on the sensor ID.
There are many more examples for querying data; all of those possibilities are discussed in the Query API documentation.
If you want all the records, then the range should start at 0. The query with specific sensor IDs looks like this in Flux:
String flux = String.format( "from(bucket:\"%s\") |> range(start:0) |> filter(fn: (r) => r[\"_measurement\"] == \"sensor\") |> filter(fn: (r) => r[\"sensor_id\"] == \"TLM0100\"or r[\"sensor_id\"] == \"TLM0101\" or r[\"sensor_id\"] == \"TLM0103\" or r[\"sensor_id\"] == \"TLM0200\") |> sort() |> yield(name: \"sort\")", getBucket());To trigger the Flux query above, the influxdb-client provides the QueryApi which contains the query method.
QueryApi queryApi = influxDBClient.getQueryApi();
List<FluxTable> tables = queryApi.query(flux);
for (FluxTable fluxTable : tables) {
List<FluxRecord> records = fluxTable.getRecords();
for (FluxRecord fluxRecord : records) {
System.out.println(fluxRecord.getValueByKey("sensor_id"));
}
}Deleting data points
To delete data from an InfluxDB bucket, use the DeleteAPI. One binding condition is that the delete queries should have at least one timestamp. If you do not mention the predicate, InfluxDB will delete all the data from the measurement (table).
To delete specific data, use the following query:
DeleteApi deleteApi = influxDBClient.getDeleteApi();
try {
OffsetDateTime start = OffsetDateTime.now().minus(72, ChronoUnit.HOURS);
OffsetDateTime stop = OffsetDateTime.now();
String predicate = "_measurement=\"sensor\" AND sensor_id = \"TLM0201\"";
deleteApi.delete(start, stop, predicate,getBucket(), getOrg());
flag = true;
}Conclusion
As you can see, time series data is crucial for better analysis and for gaining meaningful insights. With the advent of IoT devices, self-driving cars, and other, more efficient systems, the need for and scope of time series data are increasing.
A specially designed and optimized time series database like InfluxDB is perfectly suited to handle the volume and speed of time series data growth as opposed to a “traditional” database. InfluxDB manages time series data in an optimized manner and provides lightning-fast retrieval. Its new query language, Flux, makes querying it for data simple. Flux is a stand-alone, JavaScript-like language and one of its most useful features is that it can integrate with different data sources and tools using third-party APIs. As a result, you can hook up InfluxDB very easily with third-party analytics tools, data sources, and so on.
Depending on the needs of your application, you can easily integrate InfluxDB, whether your application is written in Java, Python, Kotlin, Scala, or one of many other programming languages.
In this article, you learned how to get started using InfluxDB with Java and reviewed some standard operations like inserting data, querying for data, etc., using the InfluxDB client.
There are many features you can add to your application like creating and managing buckets, setting up health checks for your database application, connecting with Telegraf, etc. The documentation provides excellent examples and is the best place to explore these great features.
About the author:

Reshma is a recent Master of Computer Science degree graduate from the University of Illinois at Urbana-Champaign who loves to learn new things. She has previously worked as a Software Engineer with projects ranging from production support to programming and software engineering. She is currently working on self-driven projects in Java, Python, Angular, React, and other front-end and back-end technologies.
