Table of Contents
In distributed databases it’s a common benchmark goal to get to 1 million writes per second. With InfluxDB, we’ve been optimizing towards that goal over the last year as we built a storage engine from scratch, had multiple releases of clustering in our InfluxDB Cloud and InfluxDB Enterprise offerings and performed optimizations specific to our implementation language, Go. Over this time we’ve been testing clusters and improving performance and stability along the way. With the upcoming release of InfluxDB 1.1, we’ve achieved writes greater than 1 million values per second on very modest configurations. In this post we’ll look at some of the configurations and give pointers to our test code.
We tested on multiple configurations in AWS. The minimal configuration was 4 m4.4xlarge instances running as data nodes with a replication factor of 2. With this configuration we were able to get 1 million writes per second. Obviously, your mileage may vary and we’d recommend a larger setup to run at that load 100% of the time, but we think it’s a great start. With the next few releases we’ll be improving that throughput and getting even better numbers, but let’s look at what’s current.
We tested on AWS M4 instances using replication factors of 1, 2, and 3. Unlike other distributed databases, InfluxDB doesn’t require users to triply replicate their data, which gives nice throughput and disk space savings. Using 4 m4.4xlarge instances, an InfluxDB cluster sustained 1 million writes per second for 1 billion total values written. Writes were batched through the HTTP protocol using the influx-stress load testing tool.
We also tested a 5 node cluster using m4.4xlarge instances and a replication factor of 3 that sustained 1 million writes per second. The following graph tracks the CPU, memory, and disk utilization of the hardware during the test and you can see that the activity was consistent and stable.
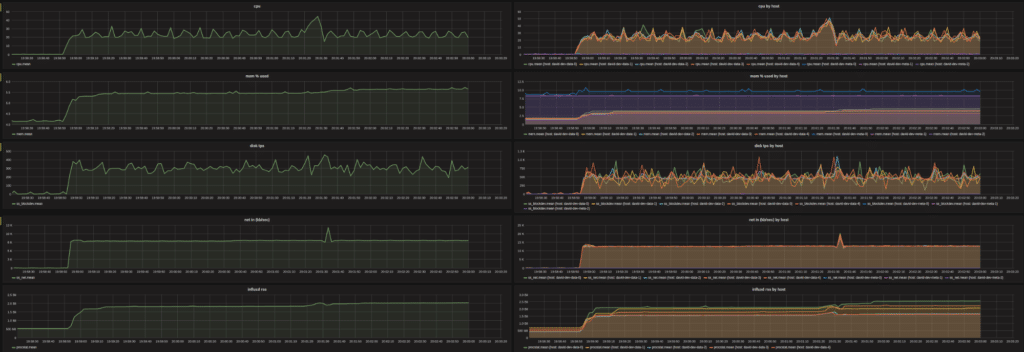
Finally, we tested a larger cluster of 5 nodes with a replication factor of 2 and clocked it at 1.5 million writes per second. In a real world scenario, users would want to operate with extra headroom. Most real-world production installations would likely require 2x the hardware during these tests.
Even in a real-world production setting, InfluxDB achieves 1M writes per second on significantly cheaper and smaller footprints than other distributed databases. In the coming weeks we’ll be updating our technical performance papers with comparisons against clustered setups. We’ll also benchmark larger clusters in the runup to 10 million writes per second.
What's next
- Downloads for the TICK-stack are live on our "downloads" page
- Deploy on the Cloud: Get started with a FREE trial of InfluxDB Cloud featuring fully-managed clusters, Kapacitor and Grafana.
- Deploy on Your Servers: Want to run InfluxDB clusters on your servers? Try a FREE 14-day trial of InfluxDB Enterprise featuring an intuitive UI for deploying, monitoring and rebalancing clusters, plus managing backups and restores.
- Tell Your Story: Over 100 companies have shared their story on how InfluxDB is helping them succeed. Submit your testimonial and get a limited edition hoodie as a thank you.
