How InfluxDB IOx Manages the Data Lifecycle of Time Series Data
By
Paul Dix
updated December 14, 2025
Product
Use Cases
Developer
Navigate to:
Last month we announced InfluxDB IOx (pronounced: eye-ox), a new Rust and Apache Arrow based core for InfluxDB. While InfluxDB IOx is a columnar database built on top of object storage, that’s only part of its role. In addition to query functionality, one of the big goals of InfluxDB IOx is to help manage the data lifecycle for time series data. This post will cover the design for how InfluxDB IOx plans to manage that data lifecycle.
The data lifecycle of time series data usually involves some sort of real-time ingest, buffering of data for asynchronous replication and subscriptions, in-memory data to query, and writing out large blocks of immutable data in a compressed format. Add the movement of that data to/from memory and object storage, removal of high-precision data to free up space and that’s most of what InfluxDB IOx is considering with the data lifecycle. Deletes are also handled, but those details are for another post.
The real-time aspect of time series data for monitoring, ETL, and visualization for recent data is what InfluxDB IOx is optimizing for. Because InfluxDB IOx uses object storage and Parquet as its persistence format, we can defer larger scale and more ad hoc processing to systems that are well-suited for the task.
InfluxDB IOx defines APIs and configuration to manage the movement of data as it arrives and periodically in the background. These can be used to send data to other InfluxDB IOx servers for processing, query or sending it to object storage in the form of write ahead log segments or Parquet files and their summaries.
How data is logically organized
Data that is queryable falls into either the MutableBuffer, the ReadBuffer, or ObjectStore. The MutableBuffer is where real-time writes land. It’s optimized for writes, but can also be queried. The ReadBuffer is where blocks of data from either the MutableBuffer or ObjectStore are kept and optimized for compression and query speed. Finally, the ObjectStore is where blocks of immutable data are kept in compressed format (Parquet files) along with summaries of the data to speed up query time and cache warming.
Whether data is in the MutableBuffer, the ReadBuffer, or ObjectStore, it has a consistent logical organization describing it. Queries should work across all sources and be combined at query time. Real-time writes can only be written into the MutableBuffer, which can then be converted over to immutable chunks in the form of Parquet files and their summaries in object storage or as read-only blocks of memory with summary statistics in the ReadBuffer.
Here’s an example of how data is logically organized for a setup where partitions have been defined by day:
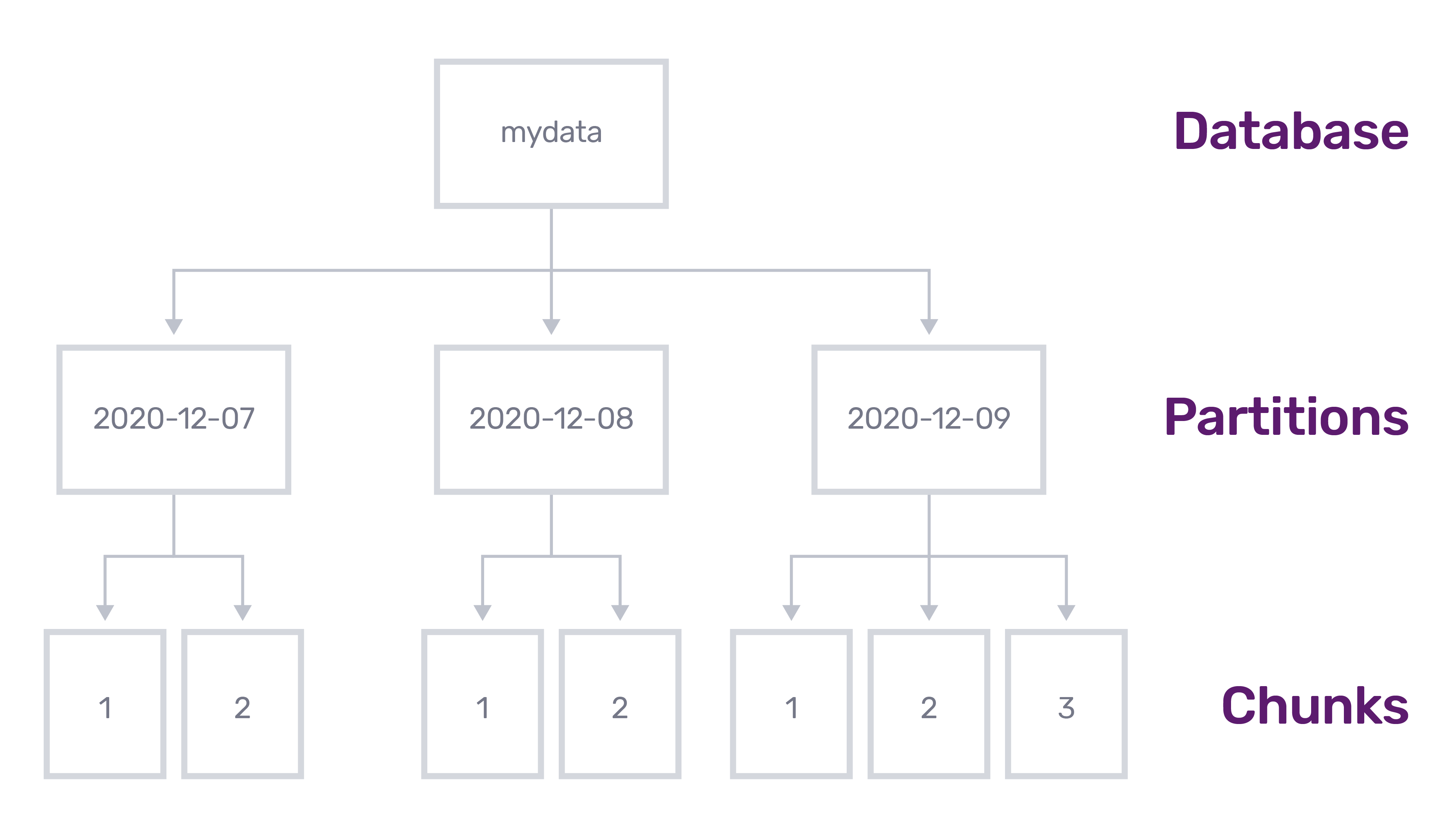 <figcaption> How time series data is logically organized for a setup in InfluxDB IOx</figcaption>
<figcaption> How time series data is logically organized for a setup in InfluxDB IOx</figcaption>
Partitions are defined by their partition key, which is a string that is generated for each row as it is written in. Partitions serve to separate data as it is written into the database or replicated to other servers. A partition key can use any combination of the table name (measurement), column values (tags or fields), or a formatted time string from the time column or any column with a time datatype.
Chunks are collections of data. All rows in a Chunk share the same partition key value. They are defined by what tables exist in them, their schemas, and their summary statistics (min, max, count). Chunks are useful for buffering up data, which can later be changed to be immutable so they can be moved over to the ReadBuffer or ObjectStore.
Within a partition, chunks have identifiers that are monotonically increasing. The goal here is to help determine what order data was written in if a later write overwrites some data in an older chunk within a partition. InfluxDB IOx follows single-writer, many-reader semantics with its interactions with the ObjectStore. This means that InfluxDB IOx servers can write and ensure chunk order without distributed coordination. However, partitions can be spread across multiple writers.
While the example in the diagram above has partition keys that are mutually exclusive, this isn’t a strict requirement. The rules for generating partition keys can change over time and can vary from server to server.
Managing data movement to object storage
As data is written into InfluxDB IOx, it lands in the WAL Buffer and/or the MutableBuffer. The WAL Buffer isn’t queryable and only exists to buffer writes and modifications to the database. This buffer is useful for handling subscription requests for data roughly as it arrives or as a way to buffer data into a WAL Segment, which is then written to object storage.
Each InfluxDB IOx server has a unique identifier, which is used as the prefix in the path for any files written to object storage. This design gives InfluxDB IOx interactions with the ObjectStore the semantics of single-writer, many-reader. This means that writers need zero coordination to do their work and readers can be scaled up on an as-needed basis without any impact or interaction with the writer pipeline.
The MutableBuffer can be used to handle query workloads or as a staging area for written data until it is rolled over and converted into Chunks in the ObjectStore or ReadBuffer.
The operator can control this data movement either explicitly by API call, or based on configuration. The configuration can specify a rollover event and shipment to object storage based on one or more of:
- Row count (or WAL entry count)
- Size in bytes (rollover after this number is reached)
- Time since first write (rollover after this segment or chunk has been open for X time)
In the WAL Buffer, a rollover will simply create the next segment number and have the new segment accept incoming WAL entries. The segment that was just rolled over can then be copied up to object storage. Operators can define when old WAL Segments get deleted. This could be triggered by request, by time (age out old segments), or based on when a segment has been captured entirely by Chunks that have been persisted to object storage.
In the MutableBuffer, a rollover will convert the currently open Chunk within the given Partition to be read-only. If writes arrive for that partition after this point, a new chunk will be created with the next ID. Once the older chunk is read-only, it can be written out to the ObjectStore in the form of Parquet files and a summary of it can be converted over to the ReadBuffer. If moving over to the ReadBuffer, the switch from MutableBuffer Chunk to ReadBuffer Chunk is atomic so that queries only hit one or the other.
While data in the MutableBuffer and object storage is organized by partition, the WAL exists for the entire logical database. Writes to different partitions will land in the same WAL, which gets rolled over independently of when Chunks in Partitions in the MutableBuffer get rotated.
Wrapping up
Most of this work is currently in flight. The details for this blog post were pulled from internal design documents that we’re working from. We’re not producing builds of InfluxDB IOx yet since there’s still much to do. Our goal is to have alpha builds with documentation in early February 2021. We’ll be writing more about the design choices of InfluxDB IOx as we go.
If you’re interested in more details as they develop, please join us on Wednesday, January 13th at 8am Pacific for the next monthly InfluxDB IOx tech talk and community office hours. And if you missed last week’s InfluxDB IOx Tech Talks, click here to view the recording.
