InfluxDB 3.0 is up to 45x Faster for Recent Data Compared to InfluxDB Open Source
By
Charles Mahler /
Product
Aug 09, 2023
Navigate to:
With the release of InfluxDB 3.0, one of the big questions is: how does it compare to previous versions of InfluxDB? We have begun benchmarking InfluxDB 3.0 with production workloads to start giving users more insight into the benefits of adopting InfluxDB 3.0. In this post, we look at recent benchmarks comparing InfluxDB 3.0 to InfluxDB Open Source (OSS) 1.8.
We summarize the performance benchmark results as follows:
- InfluxDB 3.0 provides 45x better write throughput over InfluxDB OSS.
- InfluxDB 3.0 has 4.5x better storage compression compared to InfluxDB OSS.
- InfluxDB 3.0 is more efficient for given hardware resources and can reduce storage costs by 90%+ as compared to InfluxDB OSS.
- InfluxDB 3.0 queries are 2.5-45x faster across a broad range of query types for recent data (5m) as compared to InfluxDB OSS.
- InfluxDB 3.0 queries are 5-25x faster across a broad range of query types for past 1-hour time ranges as compared to InfluxDB OSS.
Our overriding goal was to create a consistent, up-to-date comparison that reflects the latest developments in InfluxDB 3.0 in contrast to InfluxDB Open source. We will re-run these benchmarks regularly and update our detailed benchmark technical papers with our findings.
This benchmarking test provides a clear framework for comparing InfluxDB 3.0 with previous versions of InfluxDB, including 1.x and 2.x. You can try our interactive benchmarking tool, here.
Products & versions tested
InfluxDB 3.0
InfluxDB 3.0, the newest version of InfluxDB, gives developers unprecedented scale and performance. InfluxDB 3.0 supports the full range of time series data including high cardinality data such as metrics, events, and traces. Built in Rust on top of Apache Arrow, this decoupled architecture allows compute and storage to scale independent of one another. InfluxDB 3.0 provides query support for both SQL and InfluxQL (custom SQL-like query language with added support for time-based functions). InfluxDB 3.0 has two products on the market and one product launching later this year. InfluxDB Cloud Serverless is a multi-tenant instance of the database, and InfluxDB Cloud Dedicated is a single-tenant offering. Both are currently available. InfluxDB Clustered, launching later this year, is a dedicated instance of InfluxDB 3.0 that customers can manage and operate in their own environments.
InfluxDB OSS 1.8
InfluxDB 1.8 is the latest version of the v1 line of InfluxDB. At its core is the Time-Structured Merge (TSM) Tree, a custom-built storage engine optimized for time series data. InfluxDB OSS supports InfluxQL and is popular within the community because of its time-series-specific capabilities (we focused on testing queries using InfluxQL because both InfluxDB 3.0 and InfluxDB 1.8 support InfluxQL natively, resulting in stronger direct comparisons).
Benchmark methodology
Workload
We designed this benchmark to simulate real world conditions. The test executes queries sequentially for various time ranges and schedules during ingest to simulate actual workload conditions. Future benchmark testing plans include adding parallel execution of query workloads. We selected Telegraf as the data collection agent of choice for testing write throughput. The test increases the number of clients writing data until a degradation in performance is observed.
Dataset
We designed the data for this benchmark to simulate an application performance monitoring workload using Telegraf input plugins to collect a variety of metrics and measurements. Here are the high level details of the dataset:
- Dataset duration: 24 hours
- Measurement interval: 10 seconds
- Cardinality: 160,000
For complete details on the benchmark, you can download the full report here.
Write performance
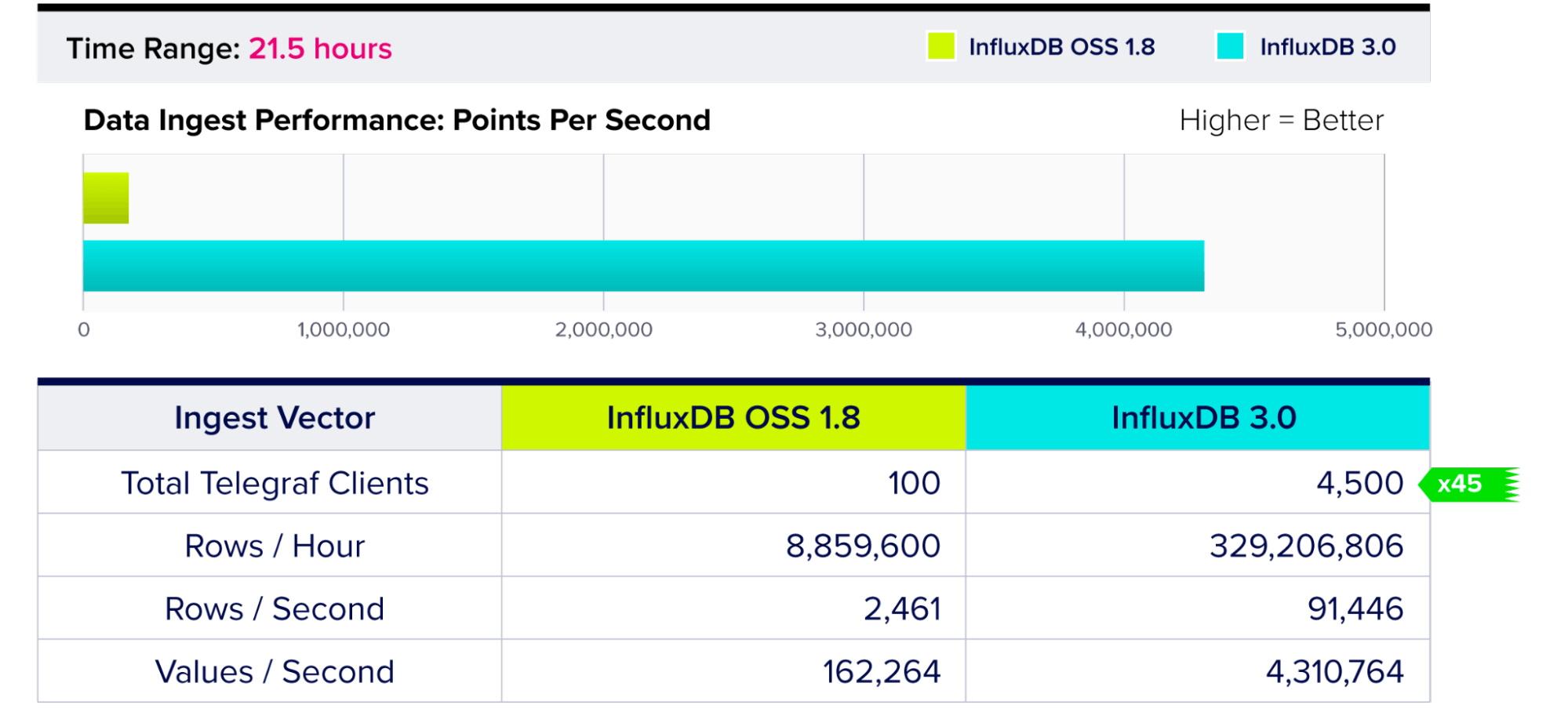
When compared to InfluxDB OSS, InfluxDB 3.0 can handle 45x more clients writing data simultaneously without a performance degradation. InfluxDB 3.0’s superior execution, despite access to fewer hardware resources than InfluxDB OSS (download the full report for hardware specification details), is further proof of the newer product’s efficiency and advancements.
Data Ingest Performance
Results represent 21.5 hours of metrics reported from varying load of Telegraf instances.
Storage performance
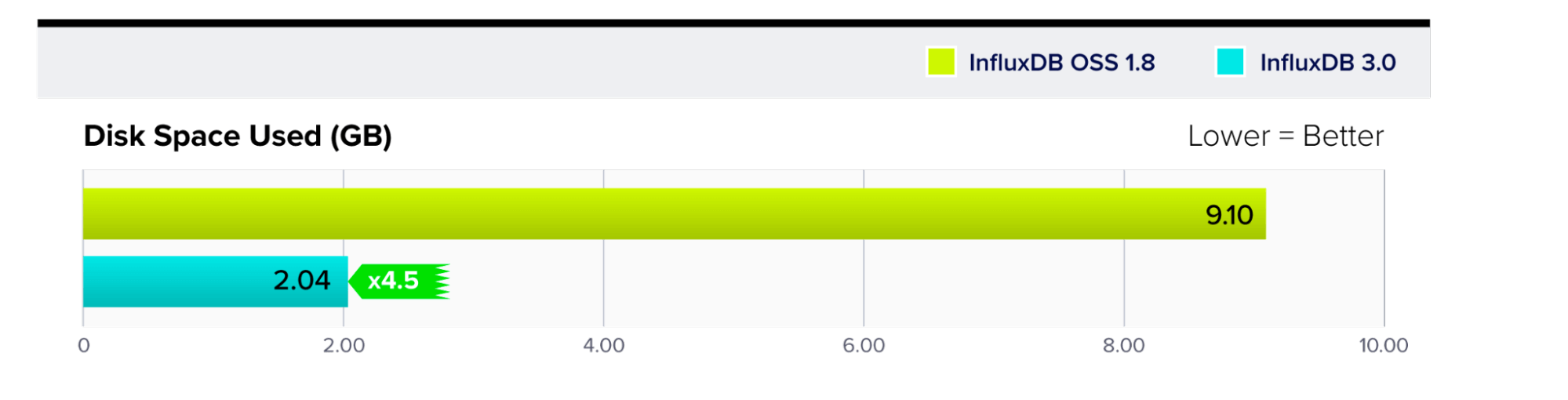
When it comes to data compression, InfluxDB 3.0 outperformed InfluxDB OSS by roughly 4.5x. The cost saving is maximized because InfluxDB 3.0 uses object storage which is cheaper than the SSD (Solid State Devices) based storage used by InfluxDB OSS.
Storage Size on Disk
Query performance observations
InfluxDB 3.0 outperformed InfluxDB OSS by 2.5-45x in the category of query performance. Thes 22 different types of queries were grouped by real-world use cases for time series data. For specific types of queries, the performance improvement is even larger.
We ran each query in the query test case 10 times for each product. The 95th percentile of the query latency metric determined performance. Queries included two separate time frames: data from the last 5 minutes and data from the last 60 minutes.
The queries can be broadly put into the following categories:
- Aggregates: Aggregates queries include those that output the aggregate values (e.g. count, sum, min, max etc.) derived from the original rows.
- Statistic / Math: Statistic / Math queries perform math (e.g. mode, median, etc.) or statistical (e.g. spread, stddev, percentile, etc.) functions on the rows selected.
- Threshold: Threshold queries return rows whose fields meet one or more threshold conditions.
- In / Or: In / Or queries return rows that match multiple values as provided by the IN / OR clauses
- Group by time: Group by time queries perform time-based operations on the rows returned.
- Group by / Order by: Group by / Order by queries return the rows that are the result of grouping of certain columns or contain results in sorted order.
- Limit / Top / Bottom: Limit / Top / Bottom queries return only the rows specified by LIMIT or TOP or BOTTOM clauses.
- Like / Union: Like / Union queries return multiple rows by matching the pattern provided by the LIKE clause or return the union of multiple queries.
Some of the charts below show the performance comparison of InfluxDB 3.0 and InfluxDB OSS after the benchmark has been running for 24 hours and querying over data within the last 5 minutes.
Query Performance – Aggregate Query Types
Queries that output aggregate values (e.g. count, sum, min, max etc.) derived from selected rows.
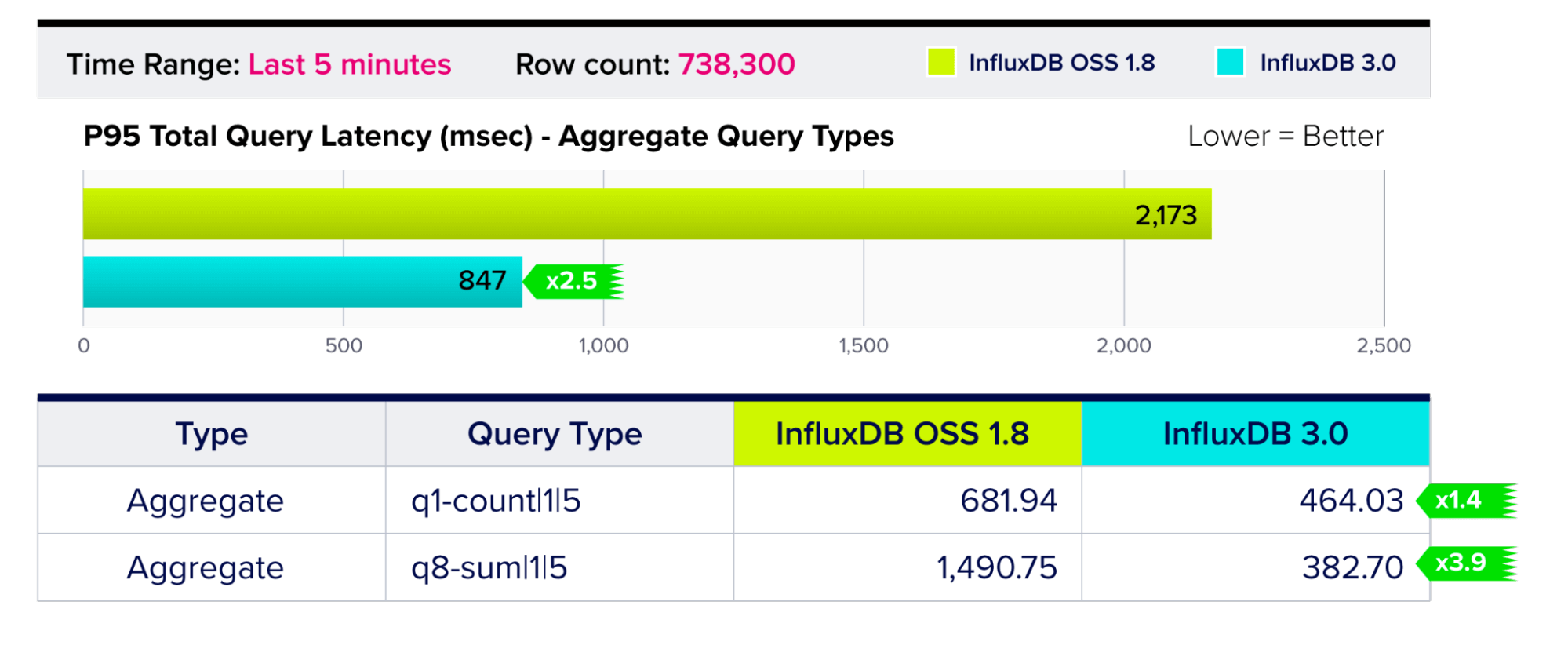
The results reflect InfluxDB 3.0’s improved performance for common analytics queries like summing all the values for multiple column values within a time range.
Query Performance – Group by / Order by Query Types:
Queries return the rows resulting from grouping certain columns or contain results in sorted order.

This group of queries use the Order by / Group by clauses to filter and sort data. The Order by query specifically shows a 78x performance improvement for InfluxDB 3.0 over InfluxDB OSS.
Query Performance – Limit / Top / Bottom Query Types
Queries return only the rows specified by LIMIT or TOP or BOTTOM condition.

These queries involve selecting the 10 most recent values and the 5 most recent CPU values using the Limit and Top clauses.
Query Performance – Statistic / Math Query Types
Queries that perform math (e.g. mode, median, etc.) or statistical (e.g. spread, stddev, percentile, etc.) functions on the rows selected.
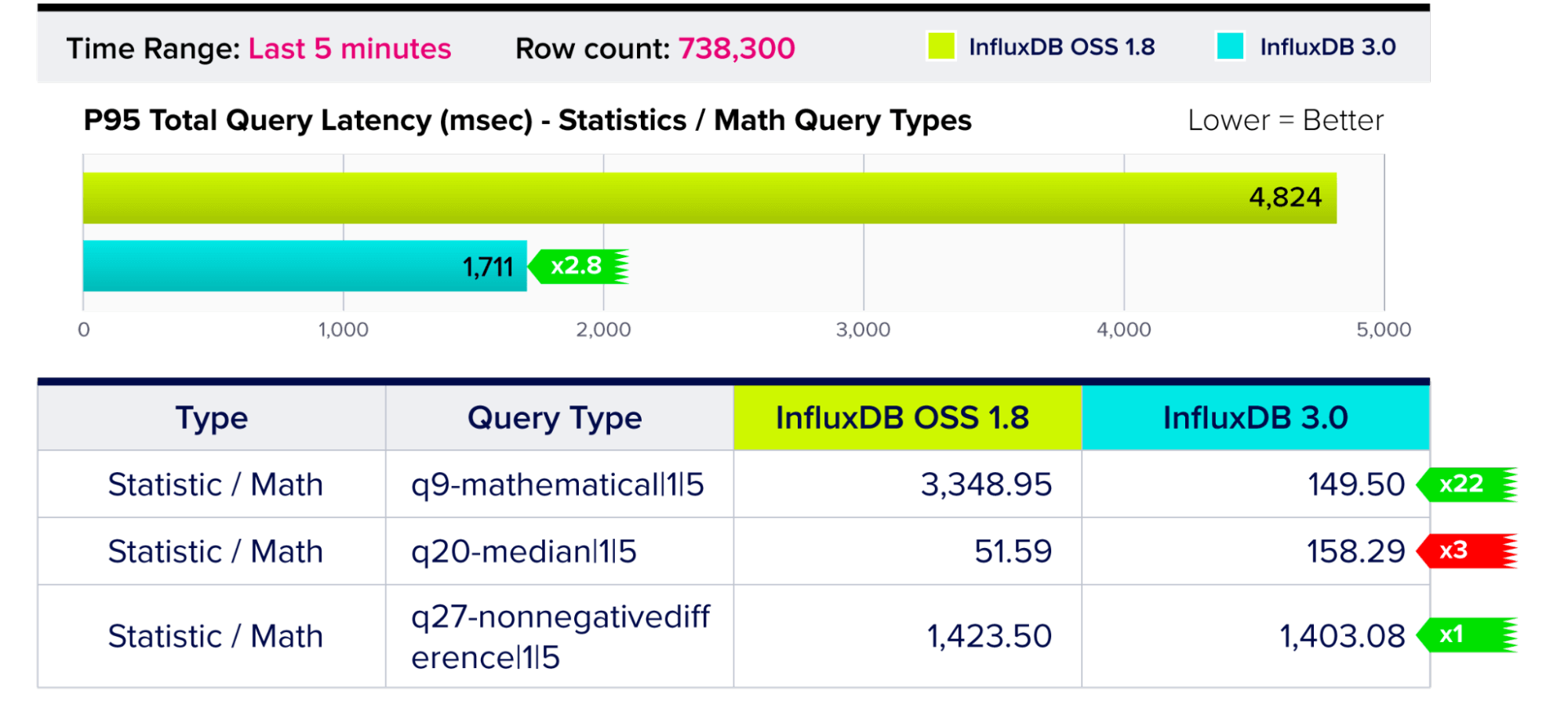
This chart includes three separate queries with a range of results. The statistics/math queries include a five-minute time range at the start of the benchmark. InfluxDB 3.0 is 22x faster for certain queries, equal for others, and a bit slower for the median operator query.
Next steps
In this post, we reviewed recent benchmarks comparing InfluxDB 3.0 to InfluxDB OSS across three vectors: data ingestion, query performance, and storage. InfluxDB 3.0 outperformed InfluxDB OSS by a significant margin in all areas.
We built InfluxDB 3.0 after many years of experience with developing previous versions of InfluxDB. We believe this is reflected in the benchmarks and detailed sections throughout the full benchmark study. Download your free copy of the full benchmark report here.
Interested in a proof of concept? Talk to someone on our sales team now!