InfluxDB and Kafka: How InfluxData Uses Kafka in Production
By
Anais Dotis-Georgiou
updated December 14, 2025
Product
Use Cases
Developer
Navigate to:
Following CTO Paul Dix’s original release announcement for InfluxDB 2.0 and a new release of InfluxDB Cloud 2.0 to public beta, I thought the community would be interested in learning about how InfluxData provides a multi-tenanted, horizontally scalable time series storage.
Part One of this series introduced us to Kafka and some basics concepts of Kafka. We also learned about how Wayfair and Hulu use InfluxDB and Kafka to create fault-tolerant, scalable, fast data pipelines. It turns out that Hulu and Wayfair aren’t the only companies to take advantage of Kafka’s solutions. InfluxData uses Kafka in production as a sophisticated Write-Ahead-Log for InfluxDB Cloud 2.0, joining several other companies
Part Two of this blog series includes:
- An overview of the problem Kafka solves
- How and why Kafka is a good solution
- A summary of the advantages of using Kafka internally for InfluxDB Cloud 2.0
What is a WAL?
A Write-Ahead-Log or WAL is a common practice across almost every performance database, including time series databases. It is a log, an append-only file, of the actions that are going to be made to the database. WALs have several advantages, but they are primarily used to maintain write durability and atomicity in database systems.
Durability – Persisting actions in WAL first ensures that those actions will be executed even if the database crashes. By logging the actions in WAL before making changes to the in-memory representation, the actions can be recovered and reapplied if needed, thereby ensuring write durability.
Atomicity – Atomicity refers to a database system property that is guaranteed to occur completely. If a server crashes midway executing various actions, the database can look at the WAL to find where it left off and finish the job, guaranteeing that the job will be executed completely.
Additionally, incorporating WAL batching is also a lot faster than doing exactly one mutation per WAL sync, which saves the client from long waiting times. Several time series database companies including Prometheus, Cassandra, Timescale, and InfluxDB all use WAL. However, WALs have some disadvantages:
- They aren't scalable because they can only be as big as ram; it's not big enough for the request volume of a multi-tenant cloud solution.
- While WAL is fast, it's not that fast – Kafka is much faster.
- WAL is only as durable as the filesystem that it's using. There isn't replication; so if the disk dies, you lose all of your data.
InfluxDB Cloud 2.0 uses Kafka as a WAL to overcome these disadvantages.
InfluxDB Cloud 2.0 and the problem Kafka solves – changes from 1.x to 2.0
WAL worked great for Cloud 1.x because it only had to scale for a single tenant. Cloud 2.0 is not only multi-tenant, but the storage nodes in Cloud 2.0 are also like the OSS storage nodes – they are self-contained, individual storage engines that don’t communicate with each other. Still, Cloud 2.0 is more elastic and robust (it provides an SLA for 99% level). So, how is multi-tenancy and efficient horizontal scaling achieved? By complex data partitioning. This data partitioning is handled by Kafka. Kafka partitions are used as WALs and Kafka broker nodes provide the durability, scalability, and efficiency that InfluxDB Cloud 2.0 requires. Kafka acts as a very large, distributed WAL.
What makes Kafka a good solution for InfluxDB Cloud 2.0?
InfluxDB Cloud 2.0 meets several requirements that InfluxDB Cloud 1.x did not. InfluxDB Cloud 2.0 includes the following requirement milestones:
- Multi-tenant – Handles multiple tenants in a cluster well. Handles performance issues around authorization.
- Elastic – The storage tier is horizontally scalable.
- Efficient – The storage tier should make as much use as possible of hardware resources across tenants. Tenants should share resources.
- Robust – Data integrity should be robust against failures.
- Tolerant – It should be easy to replace nodes within the storage tier where necessary (failure, deployment etc).
- Isolation – It should be impossible for a tenant to access another tenant's data or adversely affect another tenant.
Kafka is a good solution because it helps InfluxDB Cloud 2.0 meet these requirements in the following ways:
- Multi-tenant – A single batch of data is distributed across Kafka partitions within a Topic. Each storage engine runs a Kafka consumer that is tasked with reading messages from the partition log. Since batching is used on the producer side of Kafka, the messages that are read from a partition log typically contain points destined for multiple tenants.
- Elastic – Within the InfluxDB Cloud 2.0 platform, the write path comprises two main components: a write-ahead log and a storage engine. The WAL in Cloud 2.0 is represented by Kafka partitions, which are scalable and battle-hardened. The partitions and storage engine are distributed and independently scalable. Unlike InfluxDB 1.x, where the WAL and storage engine are in the same process, in InfluxDB Cloud 2.0 they're a separate, distributed processes. When WALs aren't decoupled from the storage tier the storage tier can't be scaled independently. If the storage tier only needs to support a heavier read load, it's not efficient to scale both the storage tier and the WAL if the write load is remaining constant. Decoupling the WAL from the storage tier enables InfluxDB Cloud 2.0 to efficiently scale just the storage tier when needed.
- Efficient – When a client writes a batch of points into the Kafka tier, the data is distributed to Kafka producers for the owning partitions, where it is briefly held and not immediately written to the Kafka partition. Kafka producers hold onto data until the producers has a large enough batch to write. The Kafka producers hold onto the growing batches while simultaneously writing other batches of data to Kafka partitions – enabling the storage engine to process large batches of data efficiently, instead of processing small batches of data from individual clients. Also, when a client writes to the WAL, they are not blocked waiting for the write to be made durable within the storage tier.
- Robust – Capturing every write and delete submitted via a Kafka producer, and archiving them on an external system, in an append-only fashion mitigates against several possible defects. If a defect or user error occurs, then a bucket can be restored by replaying the archived commands back into the WAL. This architecture protects against any defects arising from improper data serialization, dropped writes, rejected writes, improper compaction, silent deletes, and accidental data deletion (from user error).
- Tolerant – The storage tier is designed to be tolerant to a total loss of the Kafka tier. In such a scenario, the storage tier would still be available for reading. Each partition is replicated on multiple storage nodes, so the tier can tolerate a subset of storage nodes being unavailable without impacting reads.
- Isolation – Storage engines and storage nodes are not aware of each other in 2.x.
The InfluxDB Cloud 2.0 storage tier architecture
Let’s take a look at the InfluxDB Cloud 2.0 storage tier architecture to get a better understanding of how Kafka helps InfluxDB achieve those requirements.
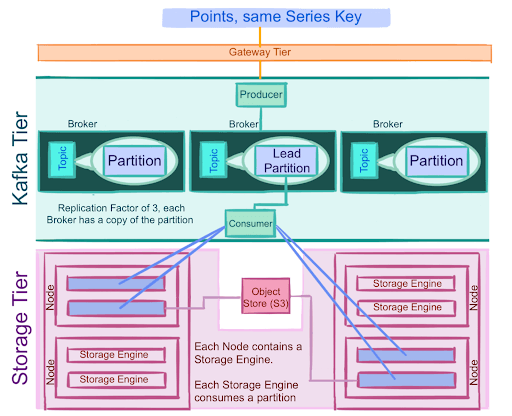
- Point data is evenly distributed among partitions by series key.
- Each partition is replicated 3 times. Therefore, the loss of one Kafka broker node does not result in the loss of its partitions' data.
- Producers write to a single leader to load balance production so that each write can be serviced by a separate broker and machine.
- Kafka manages replication across nodes. The client only needs to write into one node. This node is the leader, and leaders are per-partition. If the node is unavailable, a node with replicas will become the new leader for the necessary partitions.
- The Storage Tiers' Write API (not shown) writes a batch of points into the Kafka tier where it is held until the batch contains an optimal number of points, to ensure that efficient writes are being made to partitions.
- Multiple storage engines consume the same partition.
- Storage nodes have multiple storage engines, and each storage engine consumes one Kafka partition.
- Since there are multiple replica data sources to read from, the consumption of partitions can happen at different rates. One data source might be ahead of the other. The query tier uses the storage tier's Kafka consumption progress to determine which replica is most-up-to-date. The partition with the highest offset or farthest along log is used to determine where the query tier should read from because it is most-up-to-date.
- Some storage engines are responsible for syncing data to an Object Store.
A summary of the advantages of using Kafka as a sophisticated WAL
Using Kafka as a sophisticated WAL transforms InfluxDB Cloud into a horizontally scalable and multi-tenant time series database. Kafka is both durable and fast. Kafka’s durability provides confidence in that the users’ writes are safe and secure. Kafka’s speed eliminates bottlenecks and saves the client from long wait times. I hope this post gets you excited about InfluxDB Cloud 2.0 or at the very least Kafka. If you have any questions, please post them on our community site or Slack channel.
