InfluxDB Cloud 2.0 Launches as a Serverless Platform for Time Series Data
By
Paul Dix
updated December 14, 2025
Use Cases
Product
Developer
Navigate to:
Today we’re excited to announce the general release of InfluxDB Cloud 2.0. InfluxDB 2.0 brings together storage, UI and visualization (formerly Chronograf), processing, monitoring and alerting (formerly Kapacitor) into one cohesive whole. It’s the evolution of the TICK Stack into a single unified experience with InfluxDB 2.0 in the center and Telegraf data collectors at the edge. There’s a common API that is shared between open source InfluxDB 2.0 and InfluxDB Cloud 2.0. On top of that shared API we’ve built an all new UI for building dashboards and exploring your data, defining data collection configurations, monitoring and alerting rules, background processing, and administrative functions.
InfluxDB 2.0 is the evolution of our vision to create a complete platform for solving time series data based problems. Our goal, as always, is to optimize for developer productivity and happiness when using InfluxDB to create time series applications. These could be in server monitoring, sensor data and monitoring, real-time analytics, application performance metrics, network monitoring, financial market data, and almost anything you might want to examine, study, monitor, and act on over time. This release represents the foundation upon which we’re building a whole new set of features and capabilities. It also introduces an easy to use application for creating monitoring and alerting rules based on time series data.
InfluxDB Cloud 2.0 is a serverless platform for working with time series data, whether you’re storing and querying, processing in the background, integrating with third party systems, configuring collection agents, or creating dashboards. We’re calling it InfluxDB, but it’s nothing like a traditional database or a DBaaS. It features a paid usage based pricing model, or a free tier with rate and data retention limitations. The paid usage model is based on the storage, compute, and network resources that you consume and has the ability to scale up without any reconfiguration or contact with sales. That means you no longer need to spend time guessing at what size InfluxDB server or cluster you need ahead of your actual project.
Even though today’s announcement is about our cloud offering, we continue to develop many of these components in open source. I’ll cover the specific libraries, projects, and the InfluxDB 2.0 open source releases later in this post.
Today we’re launching with support for the AWS Oregon region, with a beta in AWS EU in the next few weeks. We’ll be rolling out to other AWS regions and making the service available on Google Cloud and Azure in the coming months. If you’d like to be notified when other regions and cloud provider support launches you can sign up here.
If you’re anxious to get started with InfluxDB Cloud 2.0, you can go here. Otherwise, in the rest of this post I’ll talk about why we decided to build out an all new API for 2.0. In addition to the API, we’ve created Flux, an all new language for querying, analytics, and data processing. Finally, I’ll step through some of our recent development of monitoring and alerting features using core API concepts and the Flux language to highlight the power of InfluxDB 2.0 as a platform for building complex time-series-based applications.
Using the platform for creating monitoring and alerting features
One of the bigger goals of InfluxDB 2.0 is to provide a unified API and language for the entire platform. We wanted to create a set of building blocks that can be used to compose more complex applications. Writing and querying data, functionality represented by InfluxDB 1.x are only one part of the platform. To represent background processing, what Kapacitor is used for, we defined an API for creating Tasks. To give users the ability to define complex logic that we don’t have built into a declarative query language, we created our new language Flux, which can be used for interactive querying or background processing.
The combination of Flux and Tasks make InfluxDB 2.0 a serverless platform for working with time series data. Using this combination and the built in time series storage, we were able to create an opinionated monitoring and alerting application, which is the focus of this release.
Our monitoring application breaks down the problem into five distinct concepts: checks, statuses, notification rules, notification endpoints, and notifications. Checks take input data, defined by some Flux query, check them against criteria defined by some Flux logic, which then generate statuses of different levels (ok, info, warn, crit, and unknown). The Flux logic and frequency at which a check is run are defined in a Task under the covers. Statuses are just more time series data that is kept in the TSDB.
Notification rules define query criteria for what statuses to look for at what frequency and level to determine when to send a notification to a specific endpoint. Endpoints are places where notifications might be sent like Slack, PagerDuty, or an HTTP target. Whenever a notification gets sent, that action gets logged to another time series. The Notification Rule contains user-configured formatting information for what to send to the notification endpoint.
In the user interface this is all driven by the building of a basic query through our point-and-click data explorer, the selection of thresholds for when to trigger statuses of a certain level and the configuration of notification rules to look for statuses of a level (like crit). To use this system a user needn’t know anything about Flux, our API, the Task system or the other underlying components. Here are a few screenshots of the experience.
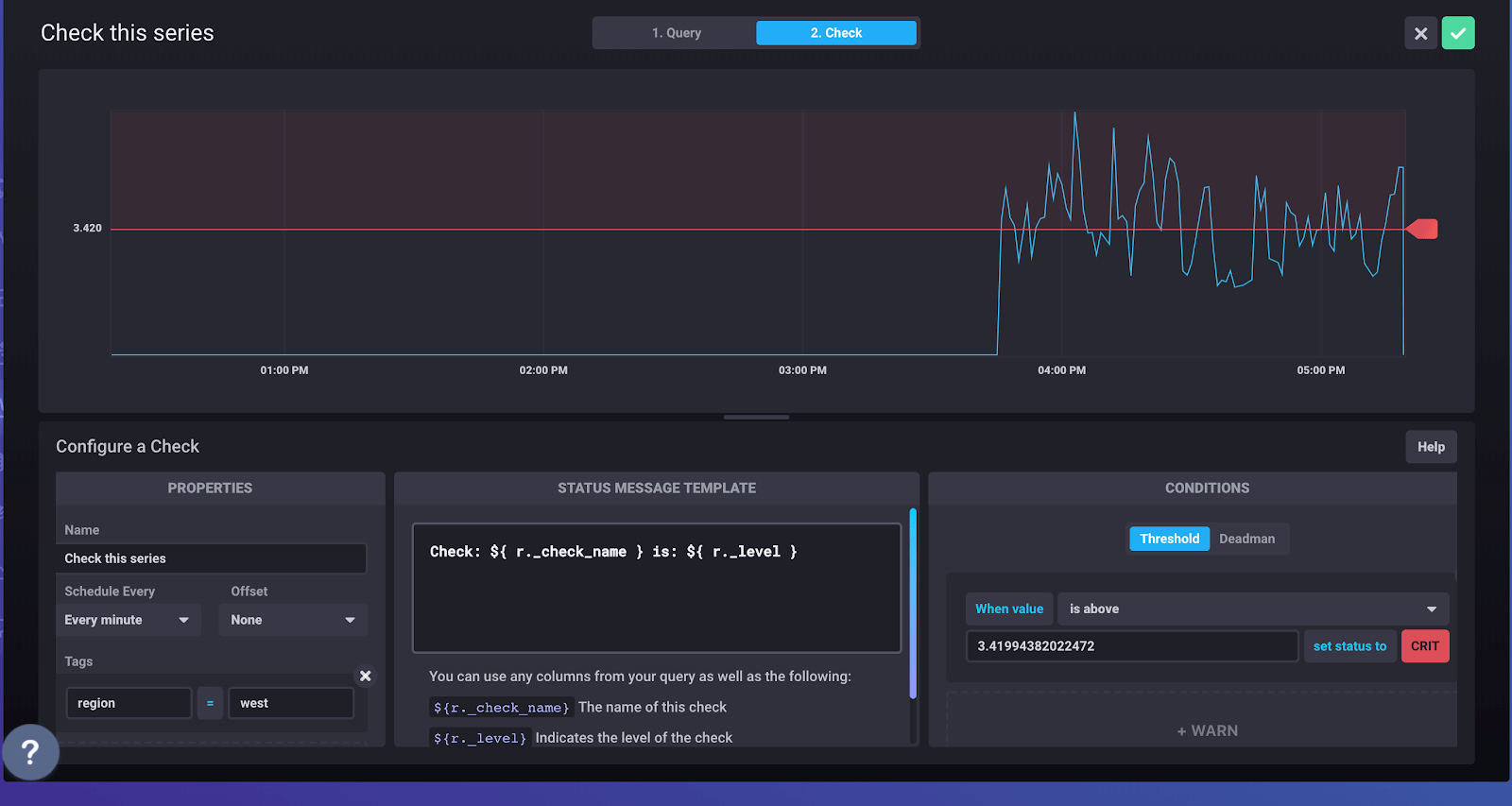 <figcaption> Building a Check</figcaption>
<figcaption> Building a Check</figcaption>
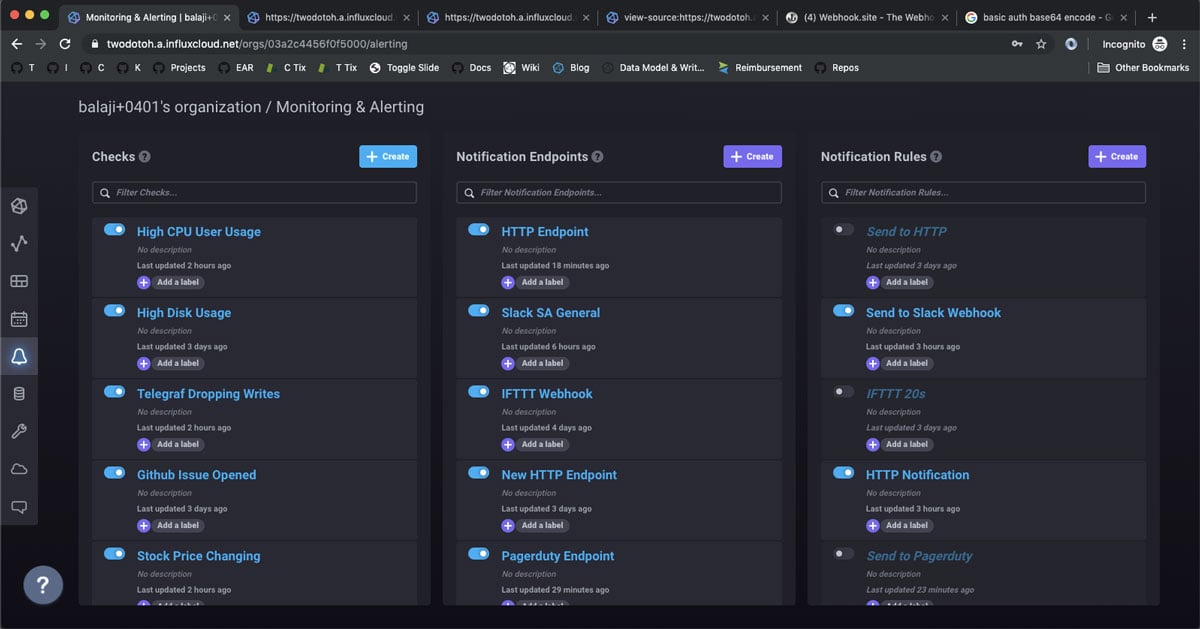 <figcaption> View of Checks, Notification Endpoints, and Notification Rules</figcaption>
<figcaption> View of Checks, Notification Endpoints, and Notification Rules</figcaption>
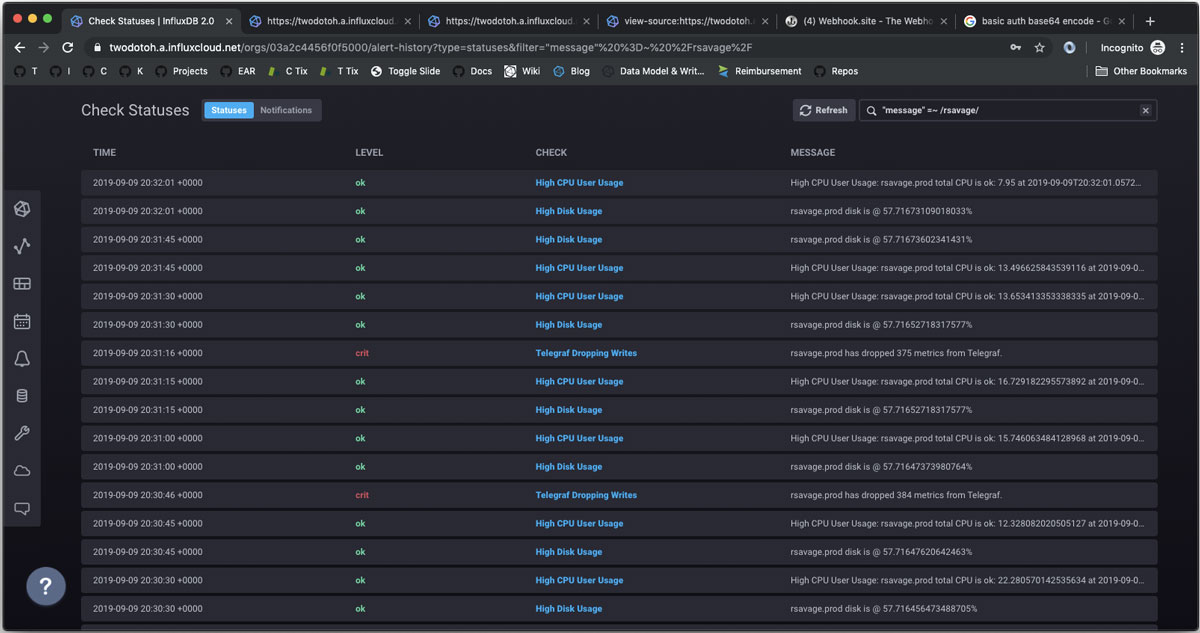 <figcaption> View of Status History</figcaption>
<figcaption> View of Status History</figcaption>
Advanced monitoring and custom code
Even though users of the basic monitoring and alerting features don’t need to know about Flux, Tasks, and the Status time series data, they can leverage these concepts to expand on our monitoring and alerting system to create much more complex monitoring. For example, here’s a Flux script that uses the check function from the monitor package:
from(bucket: "foo")
|> range(start: -1m)
|> filter(fn: (r) => r._measurement == "cpu" AND r._field == "usage_idle" AND r.cpu == "cpu-total")
|> v1.fieldsAsCols() // pivot data so there is a "usage_idle" column
|> mean(column: "usage_idle")
|> monitor.check(
data: additional_status_data,
messageFn: (r) => "${r._check_name} is at level ${r._level} with ${r.usage_idle}",
warn: (r) => r.usage_idle < 10.0,
crit: (r) => r.usage_idle < 5.0,
)The logic for what we’re querying is basic, but you can see the parts where you can do more complex selectors or transformations on the data before passing it the check function. The check function is responsible for transforming the data and writing it into a well-known bucket with a schema that conforms to what we expect statuses to be. The monitor.check function is itself written in pure Flux, which you can see here:
// Check performs a check against its input using the given ok, info, warn and crit functions
// and writes the result to a system bucket.
check = (
tables=<-,
data={},
messageFn,
crit=(r) => false,
warn=(r) => false,
info=(r) => false,
ok=(r) => true
) =>
tables
|> experimental.set(o: data.tags)
|> experimental.group(mode: "extend", columns: experimental.objectKeys(o: data.tags))
|> map(fn: (r) => ({r with
_measurement: "statuses",
_source_measurement: r._measurement,
_type: data._type,
_check_id: data._check_id,
_check_name: data._check_name,
_level:
if crit(r: r) then levelCrit
else if warn(r: r) then levelWarn
else if info(r: r) then levelInfo
else if ok(r: r) then levelOK
else levelUnknown,
_source_timestamp: int(v:r._time),
_time: now(),
}))
|> map(fn: (r) => ({r with
_message: messageFn(r: r),
}))
|> experimental.group(mode: "extend", columns: ["_source_measurement", "_type", "_check_id", "_check_name", "_level"])
|> experimental.to(bucket: "_monitoring")In the above definition you can see some use of an “experimental” namespace. Since we already have users running Flux in production, we needed an area to test out new functionality that wouldn’t break previous function definitions. The development of monitoring and alerting on top of Tasks and Flux has driven new requirements for Flux functionality. We’ll be bringing these changes into the language outside of the experimental namespace over time, without breaking current users.
The _monitoring bucket is where all statuses generated by checks are stored. They’re also where any logs of notifications sent out to third party services are kept. Since all of these are just more time series data in another bucket, they can be visualized on a dashboard or with other data.
An advanced user could define their own custom Tasks that connect to third party systems, perform complex queries on data in InfluxDB and write that data out as statuses. Those would then be picked up by the notification rules they’ve previously defined in the UI. But users could also create their own custom notification logic using the tasks system and querying the _monitoring bucket.
As we add more Flux functionality like user defined packages and more connectors to third-party systems, it’ll open up monitoring, alerting, and ETL capabilities driven entirely by our users. In the meantime, we’ve tried to get our users most of the way there with a simple to use UI built using our platform primitives so that advanced users can go farther than we could have driven through a point-and-click UI.
Still committed to open source
Even though this release announcement is about our InfluxDB Cloud 2.0 product, we’re still firmly committed to open source. InfluxDB 2.0 is currently open source and in alpha. Our philosophy is to put as much as we can into the open under an unrestricted MIT license. For things that are commercial, you’ll never have to guess at it as it won’t be intermingled with our open source code. For the code that’s in the open, it’s unrestricted. It’s a gift with no requirement of reciprocity or limitations on what you can do with it. As developers, nothing makes us happier than when someone uses our code to work on their project, improve their lives, or create new things in the world.
To that end, we continue to develop much of the platform out in the open. For example, our UI is built using the same technologies behind Chronograf and we’ve open sourced them under an MIT license as Giraffe, a React-based visualization library and Clockface, a React + Typescript UI Toolkit. This is in addition to InfluxDB 2.0, its user interface, and its API, which are all out in the open.
Telegraf, our data collector, continues to be our most popular open source project. It has hundreds of plugins contributed by a vibrant open source community with connectors not just to InfluxDB, but to other open source data stores and even competitive SaaS providers. Our model was to build a collector with the highest chance of having contributions so we intentionally made it interchangeable with other data stores.
Flux our new programming language, query planner, engine and optimizer is developed entirely in the open. InfluxDB is one way to run it, but we also have a CLI and we’ve designed the library so that it can be imported into other Go based projects. Our aim with Flux is to model it after Telegraf in terms of contribution and integration with other systems. That is, we don’t expect it to be used exclusively with InfluxDB and we’re actively supporting integrating with other data sources and sinks.
InfluxDB 2.0 open source will continue to have feature development. We’ll be updating Flux, the user interface, and adding to the API. We’ll also be adding a compatibility layer so that InfluxDB 2.0 can be written to and queried as though it’s an InfluxDB 1.x server. That means support for InfluxQL, which will be part of what we offer in 2.0 and will signal our transition from alpha to beta. We’ll also be building migration tooling to convert from the InfluxDB 1.x time series storage to InfluxDB 2.0. During the beta phase, we will return to our roots and focus on best-in-class performance and continuing to refine the user interface based on community feedback.
Get started today
While monitoring and alerting were the primary focus of this release, we’ll be continuously shipping our Cloud 2.0 product and improving it all the time. We’d love to hear feedback from you about InfluxDB 2.0, Flux, or our Cloud product. Sign up for free access to InfluxDB Cloud 2.0, or jump in on our community form.
