InfluxDB Cloud Now Available on Google Cloud
By
Al Sargent
updated December 14, 2025
Use Cases
Product
Developer
Company
Navigate to:
Today we’re excited to announce the general availability of InfluxDB Cloud for Google Cloud. With this new service, GCP users can now use our leading time series data platform on Google infrastructure. This lets you address a wide range of use cases: observability, server monitoring, IoT sensor data tracking, real-time customer analytics, application performance metrics, network monitoring, security threat detection, and financial market analysis. Whatever data you might want to examine, monitor, and act on over time, InfluxDB Cloud provides you with a reliable foundation that requires minimal effort to set up.

What is InfluxDB Cloud for Google Cloud?
InfluxDB for Google Cloud 2.0 is a serverless cloud platform that’s purpose-built for time series data. That’s a lot of buzzwords, but we’re trying to pack in a number of points. Let’s break them down.
By serverless, I don’t mean that InfluxDB Cloud doesn’t run on servers. (Obviously it does!) Instead, I mean that you don’t need to worry about sizing your database servers to match your workloads. You don’t have to worry if you bought too much capacity or too little, or about having to migrate off of one server size to the other. InfluxDB Cloud automatically handles the elastic scaling required at the backend, so you don’t have to. This way, migration from one size database server to another is never required. Our pricing isn’t based on the size of the machines you choose; it’s based on the size of your data.
By cloud, I mean that enhancements to InfluxDB Cloud 2.0 come within days, if not hours, of when they’ve been committed in our open source database, InfluxDB. This lets you take advantage of new innovations as soon as they’ve been tested and publicly deployed by our team. It also frees up time from your sysadmins and SREs to focus on other parts of your data infrastructure.
By platform, I mean that InfluxDB for Google Cloud today has all the core capabilities of InfluxDB 2.0 database: time-series data storage and querying, processing in the background, numerous integrations with third-party services (including those from Google Cloud), collection agent configuration, and highly configurable dashboards and alert processing.
By purpose-built, we mean a database that handles the relentless scale of time-stamped data generated by modern microservices, devices, and sensors something that general-purpose databases can’t do. Think of other types of use cases, such as order entry or CRM. For any single customer, writes might come once every few minutes, when someone enters an order or updates a customer record. In contrast, for time series data, you might have dozens of writes every second coming from different monitoring agents or sensors. The shape of the data is simpler than relational data, but it’s a firehose of information.
How does InfluxDB Cloud integrate with Google Cloud?
 <figcaption> Credit: @jngabo on unsplash</figcaption>
<figcaption> Credit: @jngabo on unsplash</figcaption>
InfluxDB Cloud for Google Cloud runs in Google Cloud’s central region, us-central1, in Iowa. InfluxDB Cloud now integrates with a wide range of Google services, bringing observability to your entire Google Cloud stack:
- Stackdriver: Telegraf, the data collector for InfluxDB, can use its Stackdriver Input Plugin to grab metrics from 40 different Google Cloud services and store them in InfluxDB for dashboarding with Chronograf and analysis with Flux, the new data scripting and query language for InfluxDB. There's also a Telegraf plugin to output data to Stackdriver.
- Google Kubernetes Engine: You can use Telegraf for GKE monitoring, thanks to Telegraf's Kubernetes plugin, which lets you talk to the Kubelet API and gathers metrics about the running pods and containers for a single host. You can also use the Telegraf Kube Inventory plugin, which generates metrics derived from the state of Kubernetes resources such as daemonsets, deployments, nodes, and more. And there's the Telegraf Prometheus plugin, which gathers metrics from HTTP servers exposing metrics in Prometheus format.
- PubSub: Telegraf can ingest messages from PubSub into InfluxDB, and send data out of InfluxDB to Google Cloud PubSub using its Cloud PubSub output plugin. From there, you can send data from PubSub to BigQuery, and from there to Google AI platform for further analysis.
- Cloud Build: Telegraf can monitor containers used by Google Cloud Build, thanks to its Docker plugin and Docker Log plugin.
- Compute Engine: Telegraf can monitor virtual machines spun up by Google Compute Engine, using its monitoring plugins to capture metrics for server CPU, disk, memory, network, processes, swap, and system uptime.
- IoT Core: Telegraf integrates with Google IoT Core, to help you collect metrics from devices and sensors.
- MQTT: Your devices can use an MQTT bridge to communicate with Cloud IoT Core. Telegraf can consume MQTT topics, using its MQTT input plugin. Telegraf can also output data to MQTT as well.
- BigTable: Flux can import data from BigTable, and do joins between BigTable, InfluxDB, and other data sources. (If you're not familiar, Flux is our new open-source data scripting language, designed for working with time series data.)
Notice that InfluxDB and Telegraf can be used not only to ingest data from Google Cloud, but to send data to Google Cloud as well, via the Telegraf output plugins for PubSub, MQTT, and Stackdriver. This is an important thing to look for in monitoring solutions you don’t want your monitoring data to get trapped in a “roach motel” that limits your options.
Why use InfluxDB Cloud on Google Cloud?
Real-time observability: Telegraf can collect metrics as frequently as once per second. InfluxDB dashboards update every five seconds. InfluxDB checks run every five seconds. InfluxDB also has deadman checks, which fire when a group of agents stop reporting. All these capabilities mean that once something goes wrong, your SREs will know about it sooner, which makes it easier to achieve your service level objectives (SLOs).
Flexible monitoring: Every dashboard chart in InfluxDB, and every InfluxDB check, has a Flux script behind it and can have multiple queries, joins across datasources (including Stackdriver, BigTable, and PubSub), variables, comparisons, regular expressions, and statistical functions. This gives you practically unlimited flexibility to fine-tune your monitoring to meet your needs.
Time series AI: Google Cloud AI Platform has some incredible AI and machine learning services, such as TensorFlow, TPUs, and TFX, which are ideal for analyzing the vast amounts of time series data produced by sensors, devices, and app infrastructure. Once you send your time series data from InfluxDB to BigTable, BigQuery, or PubSub, it can feed Google AI platform to generate insights.
How to sign up for InfluxDB Cloud on Google Cloud?
You can sign up for InfluxDB on Google Cloud through InfluxData’s website. When prompted for your cloud provider, just pick Google Cloud Platform as shown below.

What's the pricing of InfluxDB Cloud on Google Cloud?
InfluxDB for Google Cloud features a free tier with rate and data retention limitations, as well as a paid usage-based pricing model. The paid usage model is based on the storage, compute, and network resources that you consume and has the ability to scale up without any reconfiguration or contact with sales. That means you no longer need to spend time guessing at what size InfluxDB server or cluster you need ahead of your actual project. It also means you never have to worry about the added costs of overprovisioning or the risks of unavailability due to underprovisioning.
Speaking of pricing, we have some good news there
Passing on cloud cost savings to our customers
One great thing about cloud computing is that costs are continually dropping. Google Cloud has dropped prices numerous times, as has AWS and Azure. Because we’ve increased both the usage and efficiency of InfluxDB Cloud since we first launched last year, we too are able to pass on cost savings to our customers. These changes come in two forms: higher usage limits on our free tier and lower prices for our usage-based pricing tier. They apply to customers in all our regions: Google Iowa, AWS Oregon, and AWS Frankfurt.
Higher Free Tier Limits
Thanks to our cost-efficiency, free users now get:
- 67% more data ingest volume, from 3 MB to 5 MB in a five-minute period.
- 10x more query volume, from 30 MB to 300 MB in a five-minute period.
- 10x more data retention, from three days to 30.
Here are the details of our new higher limits for our free plan users; changes are in the first three rows:
| Old limits | New Limits | |
|---|---|---|
| Writes | 3 MB per 5 minute period | 5 MB per 5 minute period |
| Queries | 30 MB per 5 minute period | 300 MB per 5 minute period |
| Data retention | 3 days (72 hours) | 30 days |
| Dashboards | 5 | 5 |
| Tasks | 5 | 5 |
| Buckets | 2 | 2 |
| Alert Handler | Slack | Slack |
| Alert Checks & Notification Rules | 2 | 2 |
| Cardinality | 10,000 | 10,0000 |
Lower Usage-Based Pricing
Since we’re passing on our cost savings to customers on our usage-based plans, they now have the following lower prices:
- 80% price drop on writes, from $7.50/GB, down to $1.50/GB.
- 82% price drop on queries, from $0.495 per minute, down to $0.09/minute.
- 28% price drop on storage, from $1.50 per GB per month, down to $1.08 per GB-month.
Here are the details on our lower pricing for our usage-based customers; only the first three rows have changed.
| Old pricing | New pricing | |
|---|---|---|
| Writes |
$7.50/GB ($0.0075/MB) |
$1.50/GB ($0.0015/MB) |
| Queries | $0.495/minute ($0.00825/second) | $0.09/minute ($0.0015/second) |
| Storage | $1.50/GB-month ($0.0020875/GB-hour) | $1.08/GB-month ($0.0015/GB-hour) |
| Dashboards | Unlimited | Unlimited |
| Tasks | Unlimited | Unlimited |
| Buckets | Unlimited | Unlimited |
| Data Retention | Unlimited days | Unlimited days |
| Alert Handler | Slack, PagerDuty, HTTP webhooks | Slack, PagerDuty, HTTP webhooks |
| Alert Checks & Notification Rules | Unlimited | Unlimited |
| Cardinality | 1,000,000 | 1,000,000 |
You can see these changes on our pricing page for InfluxDB Cloud.
What's the timing of these changes?
If you’re already a free user, your account already has these new higher limits built-in for writes and queries.
If you’re already a customer on our usage-based plan, these new lower prices are effective as of February 1st. You’ll see them appear in the product itself in the coming days. And your February bill will have these new, lower rates for the entire month.
If you sign up for InfluxDB Cloud in the future, you’ll automatically have these new higher limits. And if you convert to our usage-based plan, it will automatically have this new pricing.
How to take advantage of the new higher free tier limits?
Again, your free account already has higher limits for writes and queries. So, you don’t need to do anything there. The one thing you might want to do is edit your buckets to keep your data for 30 days, rather than 72 hours (three days). To do that, choose Buckets from the side menu:
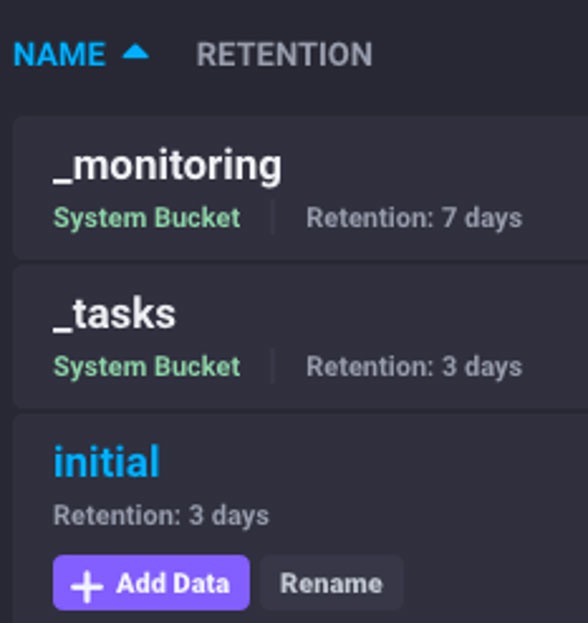
Click on the name of the bucket you want to change. In this case, we’ll click on initial:
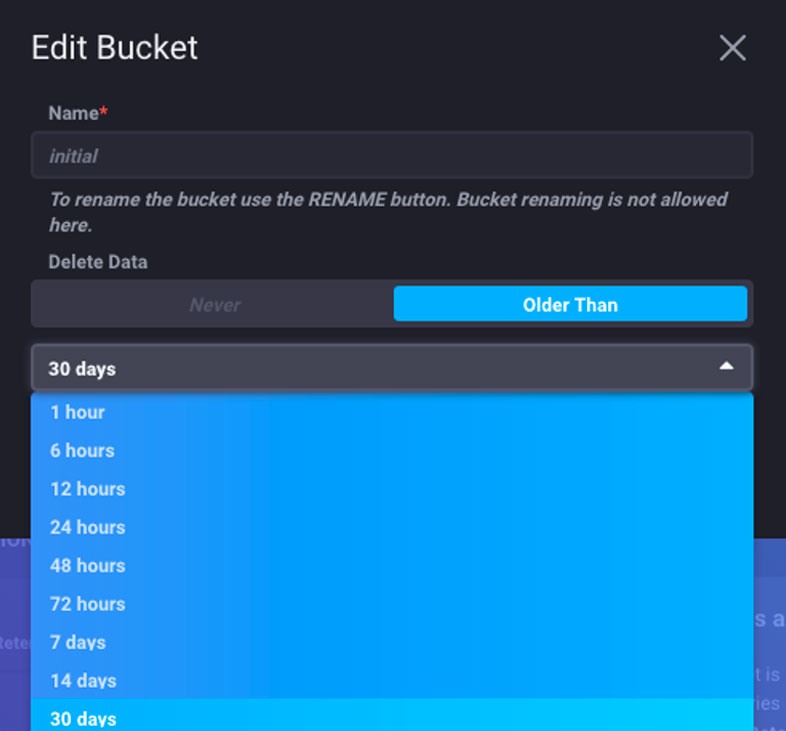
In the Edit Bucket window, choose how to keep your data. Below we change it to 30 days because why not!
What's next?
If you’re already using InfluxDB Cloud enjoy these new changes. If you’re not sign up! Then be sure to check our quick start guide and ask the InfluxDB community and Slack for help.
