InfluxDB Java Client Performance and Functionality Improvements
By
Hoan Le Xuan
updated December 14, 2025
Product
Use Cases
Developer
Navigate to:
We made some significant improvements in the performance and functionality of the latest Influxdb-java client. In this blog post, let’s take a closer look at these improvements.
Performance
Performance is a key feature of any mission-critical system (a Time Series Database among them), and one of the most significant improvements we achieved with the latest InfluxDB Java Client (influxdb-java version 2.10) was an increase in ingest rate. The following is a summary from a profiling report on benchmarking the ingest rate between version 2.9 and 2.10.
CPU Profiling
Profiling environment: Intel Core I7 6700HQ, 16GB RAM, Windows 10 Enterprise
| Config id | Stress tool | Params | Influxdb-java | Elapsed time (sec) |
| 1 | inch-java | -t 10,10,10,10 | 2.9 | 15 |
| 2 | inch-java | -t 10,10,10,10 | 2.10 | 7 |
The elapsed time difference between Config id (1) and (2) shows that the querying time drops by more than half. But it also means that the gain is a 2x the ingest rate in 2.10.
To examine what happened, we used YourKit to profile (1) and (2) and saw that:
- in Config id (1), an excess use of
String.replace(CharSequence, CharSequence)fromPoint.concatenatedTags(StringBuilder)andPoint.concatenatedFields(StringBuilder)was the cause of the performance issue - as compared to Config id (2),
no String.replace(CharSequence, CharSequence)
YourKit Screenshot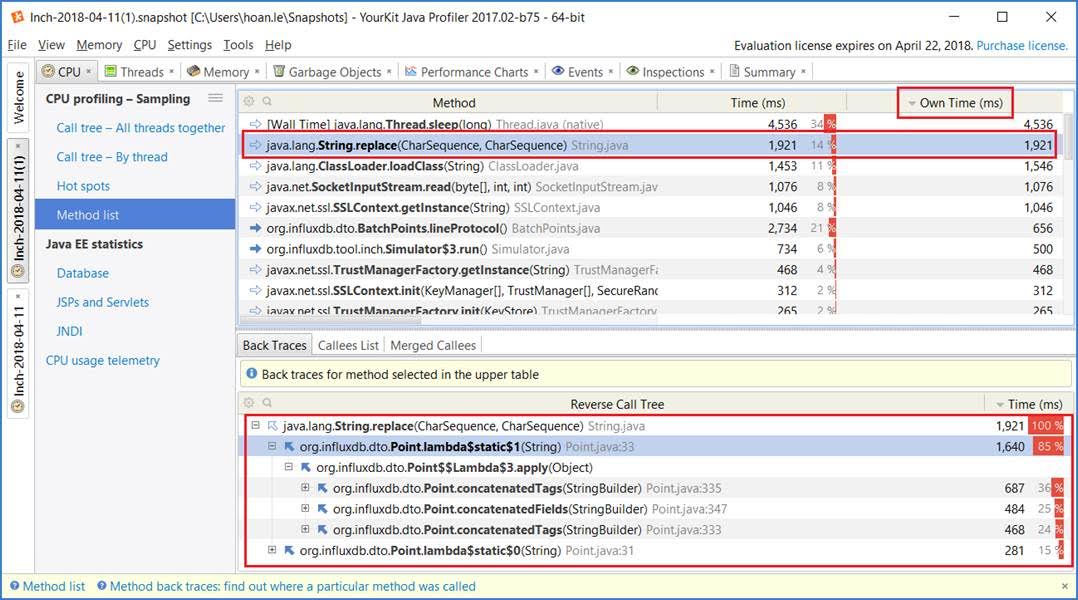
The following commit does not change the behavior but rather addressed the execution speed of it: Performance: Escape fields and keys more efficiently #424. Furthermore, the corresponding pull request specifically describes the Write performance improvements.
Heap Profiling
The version 2.10 overhead is roughly around 40% - 50% less than 2.9 as seen in the following two figures.
Figure 1: Version 2.9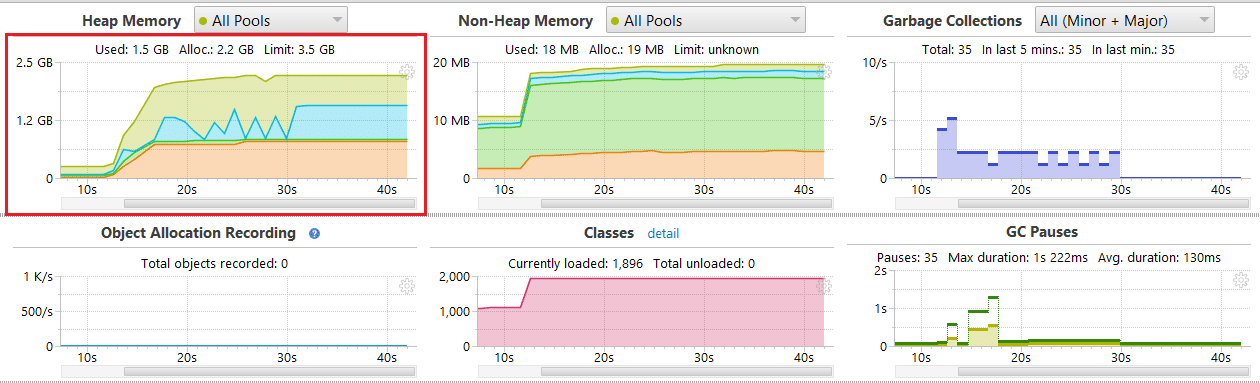
Figure 2: Version 2.10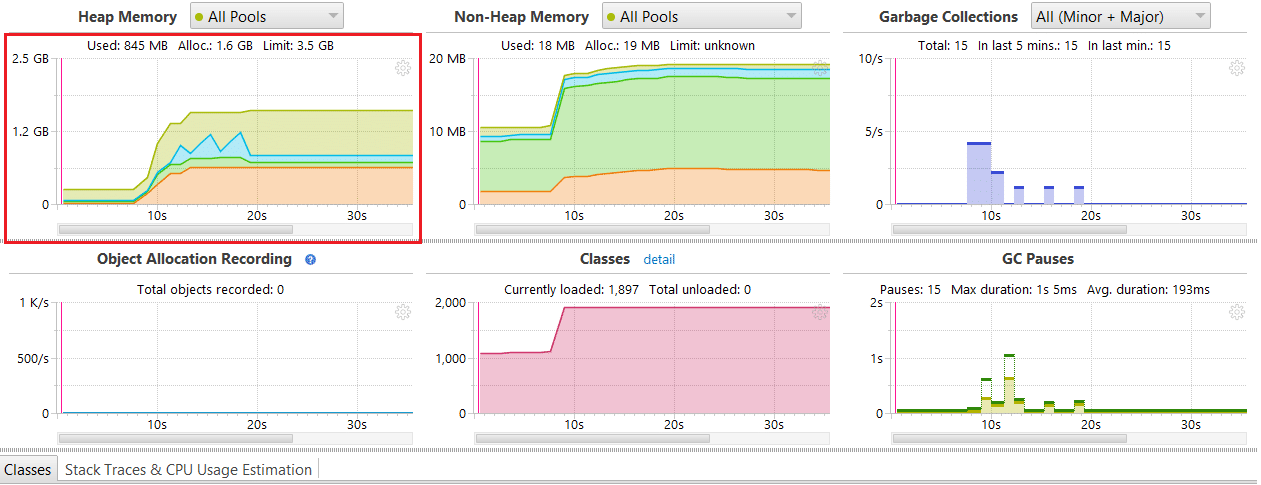
Object Allocation
Object Allocation Recording is a heavy process, so the scaled-down scenario -t 10,10 was used. In the latest build, object allocation overhead is roughly 40% less than 2.9.
Version 2.9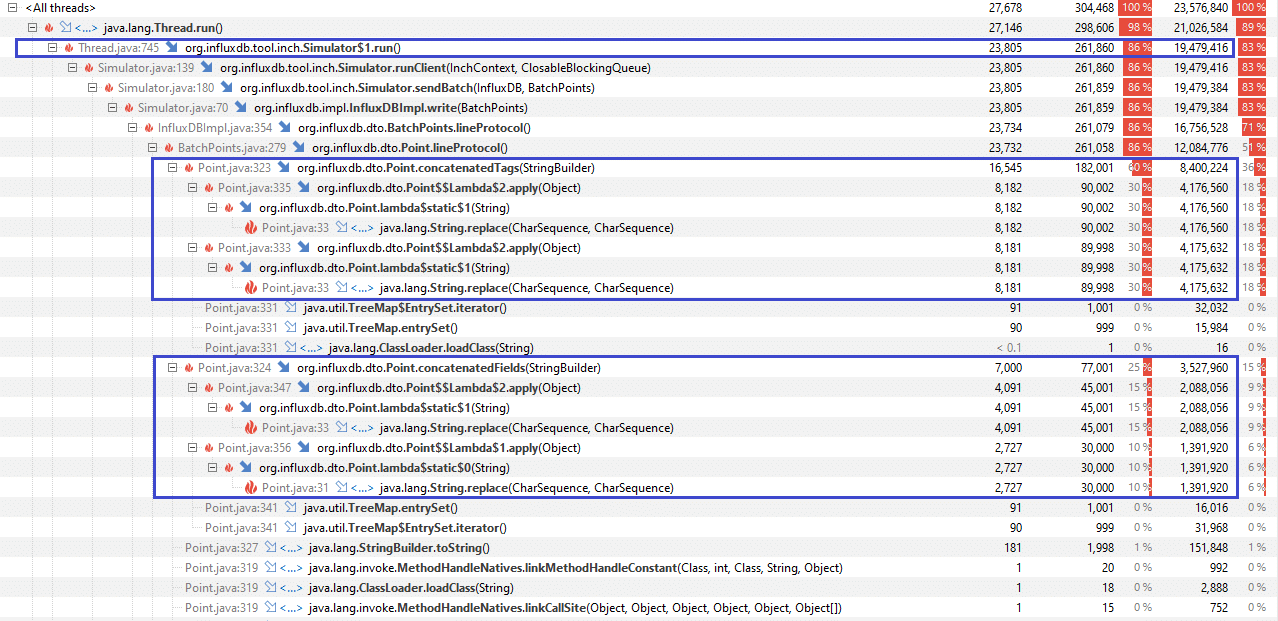
Version 2.10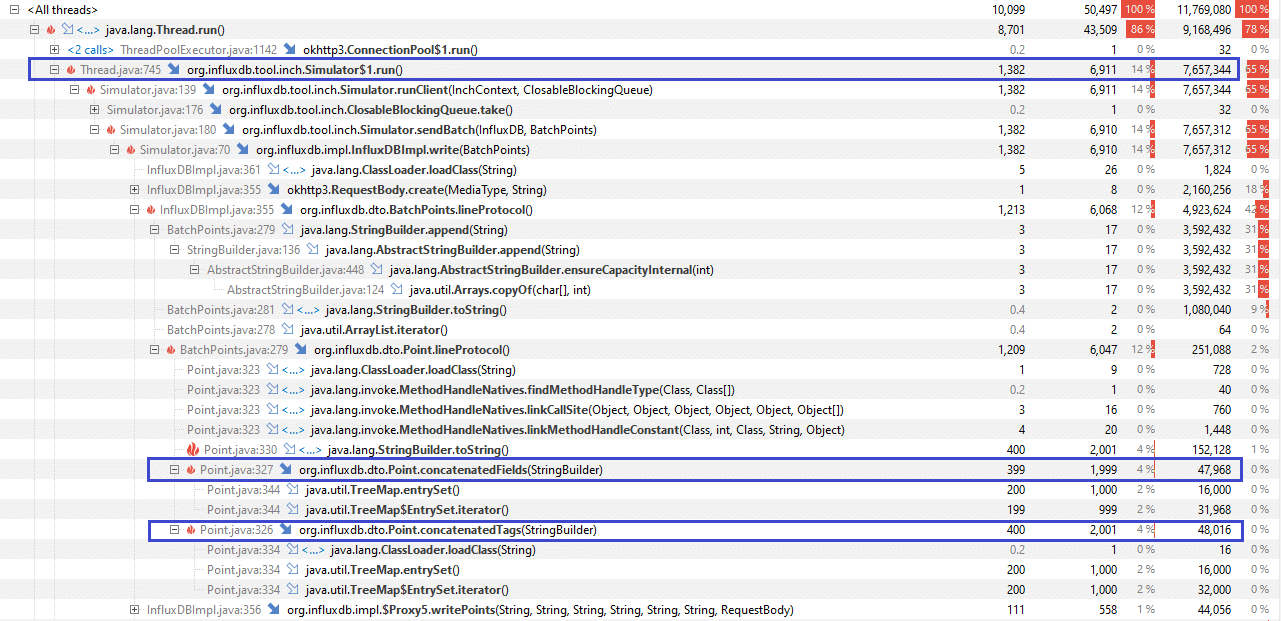
MessagePack Support
"MessagePack is an efficient binary serialization format. It lets you exchange data among multiple languages like JSON and it's faster and more compressed. Small integers are encoded into a single byte, and typical short strings require only one extra byte in addition to the strings themselves." (Source)
InfluxDB adopted MessagePack as the standard response format starting with version 1.4. Querying data in this lightway interchange format delivers significantly better performance. MessagePack was added in InfluxDB not only to improve query performance but also to address a limitation of JSON representing an Integer number. For more details, please refer to the original proposal.
MessagePack support is available in the InfluxDB Java Client beginning with version 2.12. Here is a quick comparison between JSON and MessagePack. We collected some performance measurements (in terms of querying time) for both MessagePack and JSON. The measurement was carried out on the following configurations: Intel Core I7 6700HQ, 16 GB RAM, Windows 10 Enterprise, InfluxDB OSS 1.6, influxdb-java client 2.12.
Test scenario:
The java-inch tool to create the benchmarking data. Run the java-inch tool with param -t 2,20,10 -p 10000 -> 400 series * 10000 points = 4 mil points
- Restart server
- Run
QueryComparatorfor JSON - Restart server
- Run
QueryComparatorfor MessagePack - The following table summarizes the metrics collected at Steps 3 and 5.
| Statement | JSON query time (ms) | MSGPACK query time (ms) | Difference |
| select * from m0 where tag0='value0' | 13647 | 10134 | 25.74% |
| select * from m0 | 29519 | 19191 | 34.99% |
A relative improvement of around 25.74% was observed and 34.99% for the query that returns the full dataset of 4M points. We used the Eclipse Memory Analyzer to analyze the heap dump of QueryComparator process and show the difference in the retained size of the QueryResult objects. The following table shows the results of the memory heap analysis:
| JSON | MessagePack |
| 791,736,832 bytes | 650,940,032 bytes |
Figure 1: JSON Case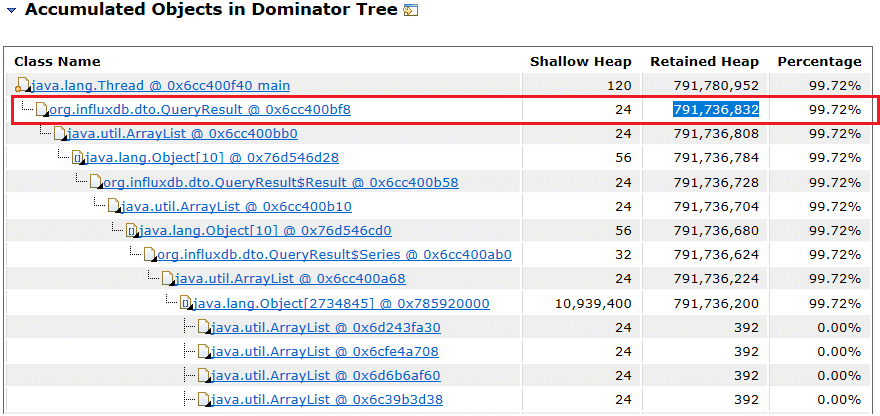
Figure 2: MessagePack Case
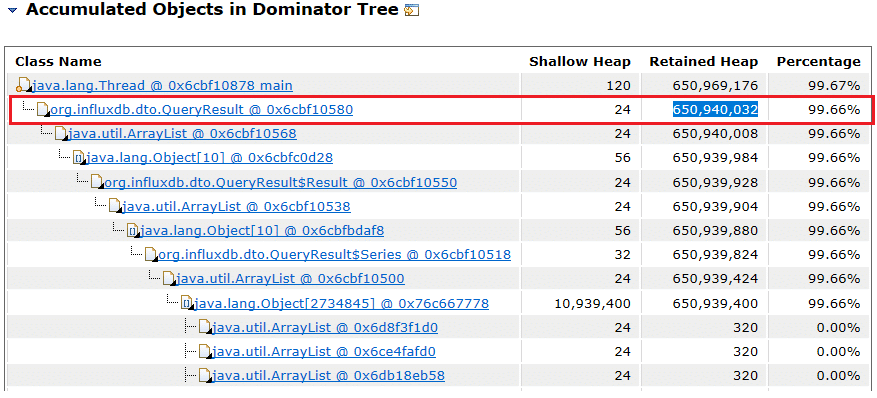
In this rather generic case, MessagePack used 17.7% less heap. The reason is MessagePack encodes the time value as a Long value, and it uses less memory in general. JSON formats time as a String and therefore becomes more resource-intensive as the strings are transformed than MessagePack.
Functionality
We also added some functionality improvements that enhance the enterprise readiness of the influxdb-java client. The following focuses on the behavioral aspects of the client such as reliability, resilience and robustness.
Reliability and Resiliency
When an InfluxDB server exceeds its limits, it starts spitting out various error states. Eventually the clients may hang without a response until they time out. If there are many clients connecting to an unresponsive influxdb server, then the system can consume all critical resources and will cascade into a failure across the entire system. A common pattern to address this situation is for the clients to back off and retry after the server returns to normal. This pattern is currently applied in Telegraf to guarantee reliabilitytogether with the other techniques described below.
Batch Writing
Database access normally consists of sending certain query language statements to the database. Each database access consumes a certain amount of overhead at both the client and server side. Sending these language statements separately causes the database server to repeat overheads wastefully. So in general, batch writing is the method used to tackle database optimization (since most modern databases support this). Both InfluxDB and influxdb-java support batch writing. For a InfluxDBImpl instance, we can enable batch writing by a BatchOptions instance.
BatchOptions options = BatchOptions.DEFAULTS.actions(100).flushDuration(100);
influxDB.enableBatch(options);In the snippet above, we enable batch writing with the following options:
actions= 100 (Theactionsparameter means size of batch. The influxdb-java will flush the batch to database server if batch size reaches 100there are 100 data points in the batch)flushDuration= 100 (influxdb-java will periodically flush the batch to database server each 100 ms)
The actions and flushDuration are the two most basic options of batch writing support in influxdb-java.
For more details, refer to org.influxdb.BatchOptions Javadocs.
Write Interval Jitter
Telegraf implements a variable flush interval on internal buffers so that a load of multiple nodes can be spread over time with no repeated spikes when multiple clients get synchronized and write batches to InfluxDB at the same time. This feature was implemented in influxdb-java 2.9.
In general, the flush interval will fluctuate randomly between flushDuration - jitterDuration and flushDuration + jitterDuration.
For example, with the following options, the next real flushDuration will stay somewhere from 80 ms to 120 ms.
BatchOptions options = BatchOptions.DEFAULTS.actions(100).flushDuration(100).jitterDuration(20);
influxDB.enableBatch(options);Write-Retries on Errors
Telegraf retries writing on certain types of failures, such as cache-max-memory-size. While InfluxDB maintains a cache on input (configured by cache-max-memory-siz CMD option). When the limit is reached, InfluxDB rejects any further writes with the following message: ("cache-max-memory-size exceeded: (%d/%d)", n, limit)
This is how the response looks - InfluxDB configuration parameter cache-max-memory-size = 104:
HTTP/1.1 500 Internal Server Error
Content-Encoding: gzip
Content-Type: application/json
Request-Id: 582b0222-f064-11e7-801f-000000000000
X-Influxdb-Version: 1.2.2
Date: Wed, 03 Jan 2018 08:59:02 GMT
Content-Length: 87
{"error":"engine: cache-max-memory-size exceeded: (1440/104)"}It makes sense to retry the request when the cache gets emptied. Here is a list of errors returned by InfluxDB to help indicate that it does not make sense to retry the write. This is due to the points having already been written or the repeated write would fail again.
| Server Error | Description |
| field type conflict | Conflicting types will get stuck in the buffer forever. |
| points beyond retention policy | This error indicates that the point is older than the retention policy permits, and is not a cause for concern. Retrying will not help unless the retention policy is modified. |
| unable to parse | This error indicates a bug in the client or with InfluxDB parsing line protocol. Retries will not be successful. |
| hinted handoff queue not empty | This is just an informational message. |
| database not found | Database was not found. |
Telegraf keeps writing failed measurements until these are written. There is no limit on the number of retries, as seen in Line 126. Telegraf checks specific errors from InfluxDB so that measurement writes that can’t be fixed by retrying aren’t written over and over.
There is a limit on the buffer of failed writes: 10000 entries by default. Additional failed writes replace the oldest entries in it when it gets filled. This feature has been implemented in influxdb-java 2.9. The client maintains a buffer for failed writes so that the writes will later be retried, which helps to overcome temporary network problems or InfluxDB load spikes.
When the buffer is full and new data points are written, the oldest entries in the buffer are evicted. In practice, we enable this feature by setting bufferLimit in BatchOptions to a value greater than actions, as shown in the snippet example below:
BiConsumer<Iterable<Point>, Throwable> exceptionHandler = (batch, exception) -> {
//do something
};
BatchOptions options = BatchOptions.DEFAULTS.bufferLimit(500).actions(100).flushDuration(100).jitterDuration(20).exceptionHandler(exceptionHandler);
spy.enableBatch(options);
writeSomePoints();We have set a retry bufferLimit at 500 data points. Then assume writeSomePoints() fails on some recoverable error (such as cache-max-memory-size), the client will later retry to write the failed points until they are successfully written. Failed points will be evicted from a retry buffer if the buffer becomes full and new points keep arriving.
Conclusion
These changes have made the InfluxDB Java Client better, more enterprise-ready, and consistent with the behavior of the Telegraf client.
