InfluxDB vs. Splunk for Time Series Data, Metrics & Management
By
Chris Churilo
updated December 14, 2025
Product
Use Cases
Navigate to:
At InfluxData, one of the questions we regularly get asked by developers and architects alike is: “How does InfluxDB compare to Splunk for time series workloads?” This question might be prompted for a couple of reasons. First, if they’re starting a brand new project and doing the due diligence of evaluating a few solutions head-to-head, it can be helpful in creating their comparison grid. Second, they may already use Splunk for ingesting logs in an existing monitoring setup but would like to now see how they can integrate metrics collection into their system and figure out if there might be a better solution than Splunk for this task.
Over the last few weeks, we set out to compare the performance and features of InfluxDB and Splunk for time series workloads, specifically looking at the rates of data ingestion, on-disk data compression and query performance. The benchmarking tests and resulting data demonstrated that InfluxDB outperformed Splunk in data ingestion, on-disk storage, and query performance by a significant margin. Specifically, InfluxDB demonstrated 17x greater average throughput, while using nearly 17x less disk space when compared against Splunk’s required storage for the same data set and delivered 25x faster response times for tested queries, compared to the response time of queries from Splunk
We felt that this data would prove valuable to engineers evaluating the suitability of both these technologies for their use cases; specifically, time series use cases involving custom monitoring and metrics collection, real-time analytics, Internet of Things (IoT) and sensor data, plus container or virtualization infrastructure metrics. The benchmarking exercise did not look at the suitability of InfluxDB for workloads other than those that are time series based. InfluxDB is not designed to satisfy full-text search or log management use cases and therefore would be out of scope. Similarly, we recognize that Splunk was originally developed as a log management solution, with Metrics being introduced in Splunk version 7.0. We highly encourage developers and architects to run these benchmarks themselves to independently verify the results on their hardware and data sets of choice.
To read the complete details of the benchmarks and methodology, download the “Benchmarking InfluxDB vs. Splunk for Time Series Data, Metrics & Management” technical paper.
Our overriding goal was to create a consistent, up-to-date comparison that reflects the latest developments in both InfluxDB and Splunk with later coverage of other databases and time series solutions. We will periodically re-run these benchmarks and update our detailed technical paper with our findings. All of the code for these benchmarks is available on Github. Feel free to open up issues or pull requests on that repository if you have any questions, comments, or suggestions.
Now, let’s take a look at the results
Versions tested
InfluxDB v1.7.7 InfluxDB is an open source time series database written in Go. At its core is a custom-built storage engine called the Time-Structured Merge (TSM) Tree, which is optimized for time series data. Controlled by a custom SQL-like query language named InfluxQL, InfluxDB provides out-of-the-box support for mathematical and statistical functions across time ranges and is perfect for custom monitoring and metrics collection, real-time analytics, plus IoT and sensor data workloads.
Splunk version tested: v7.3.0 Splunk is a log management solution used for application management, security and compliance, as well as business and web analytics. Its core offering collects and analyzes high volumes of machine-generated data (also known as logs). It uses a standard API to connect directly to applications and devices and can be used for searching, analyzing and visualizing machine-generated data including events, metrics and logs gathered from websites, applications, sensors and devices, etc.
As of Splunk version 7.0, support for metric storage and retrieval was introduced. It is important to note that these benchmark tests are only against Splunk’s metric storage and retrieval capabilities. As stated above, in building a representative benchmark suite, we identified the most commonly evaluated characteristics for working with time series data. We looked at performance across three vectors:
- Data ingest performance – measured in values per second
- On-disk storage requirements – measured in Bytes
- Mean query response time – measured in milliseconds
About the data set
For this benchmark, we focused on a data set that models a common DevOps monitoring and metrics use case, where a fleet of servers are periodically reporting system and application metrics at a regular time interval. We sampled 100 values across nine subsystems (CPU, memory, disk, disk I/O, kernel, network, Redis, PostgreSQL, and Nginx) every 10 seconds. For the key comparisons, we looked at a data set that represents 100 servers over a 24-hour period, which represents a relatively modest deployment.
- Number of Servers: 100
- Values measured per Server: 100
- Measurement Interval: 10s
- Data set duration(s): 24h
- Total values in data set: 87M per day
This is only a subset of the entire benchmark suite, but it’s a representative example. If you’re interested in additional details, you can read more about the testing methodology on GitHub.
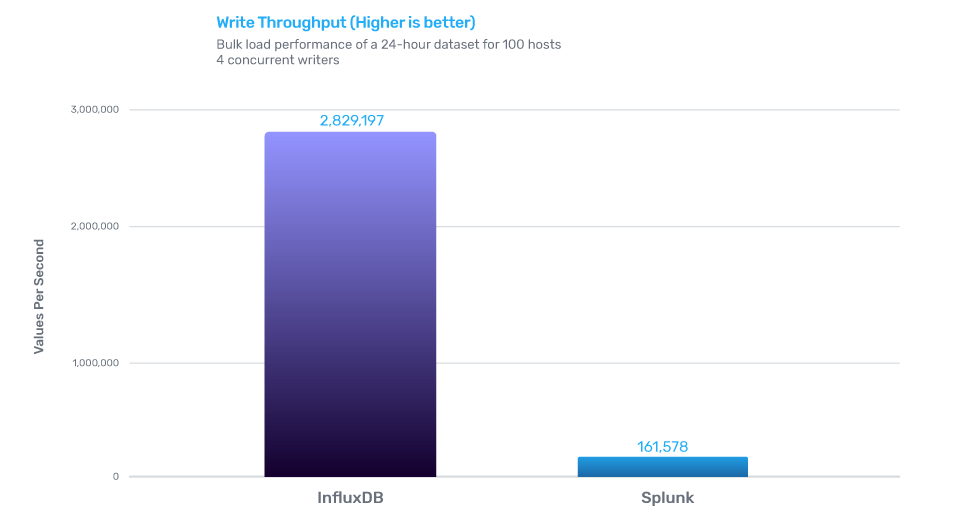
Write performance
InfluxDB outperformed Splunk by 17x when it came to data ingestion.
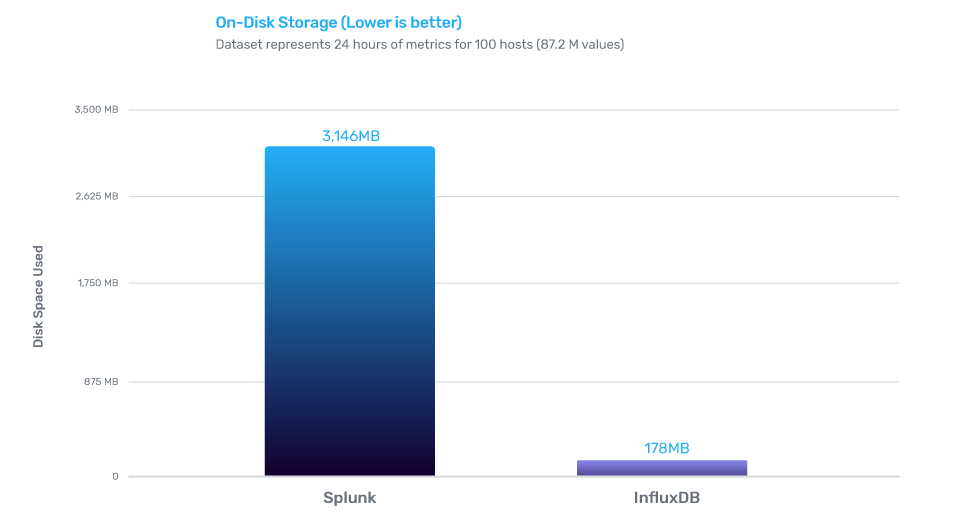
On-disk compression
InfluxDB outperformed Splunk for time series by delivering 17x better compression.
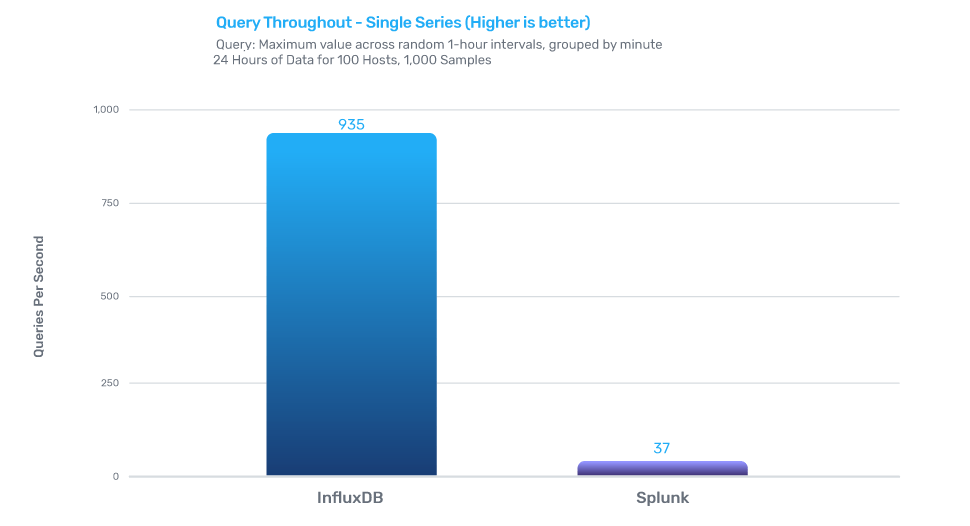
Query performance
InfluxDB for time series delivers up to 25x faster query performance.
Summary
Ultimately, many of you were probably not surprised that a purpose-built time series database designed to handle metrics would significantly outperform a search database for these types of workloads. Especially glaring is that when the workloads require scalability, as is the common characteristic of real-time analytics and sensor data systems, a purpose-built time series database like InfluxDB makes all the difference.
In conclusion, we highly encourage developers and architects to run these benchmarks for themselves to independently verify the results on their hardware and data sets of choice. However, for those looking for a valid starting point on which technology will give better time series data ingestion, compression and query performance “out-of-the-box.” InfluxDB is the clear winner across all of these dimensions, especially when the data sets become larger and the system runs over a longer period of time.
What's next?
- Download the detailed technical paper: "Benchmarking InfluxDB vs. Splunk for Time Series Data, Metrics & Management".
- Download and get started with InfluxDB.
- Join the Community!
