Intro to InfluxDB IOx
By
Susannah Brodnitz
updated October 20, 2023
Use Cases
Product
Navigate to:
Last week InfluxData announced IOx, the new time series engine for InfluxDB. We’ve revisited the core of our database to achieve big things with the underlying technology. Users can expect higher performance and more options for querying data. Here’s a quick intro to some of the most exciting things coming with InfluxDB IOx.
Unbounded cardinality
At InfluxDB when we say cardinality we mean the number of unique measurement, tag set, and field key combinations in a bucket. In the past, we discouraged using large numbers of tags or tags that contained unbounded data in InfluxDB because it would slow down performance. This limited use cases, like observability and tracing, that relied on high-cardinality data like logs and traces. InfluxDB IOx removes cardinality limits. Now users can write in data with infinite cardinality and monitor and query their time series data along any dimension they want without impacting performance.
Real-time analytics
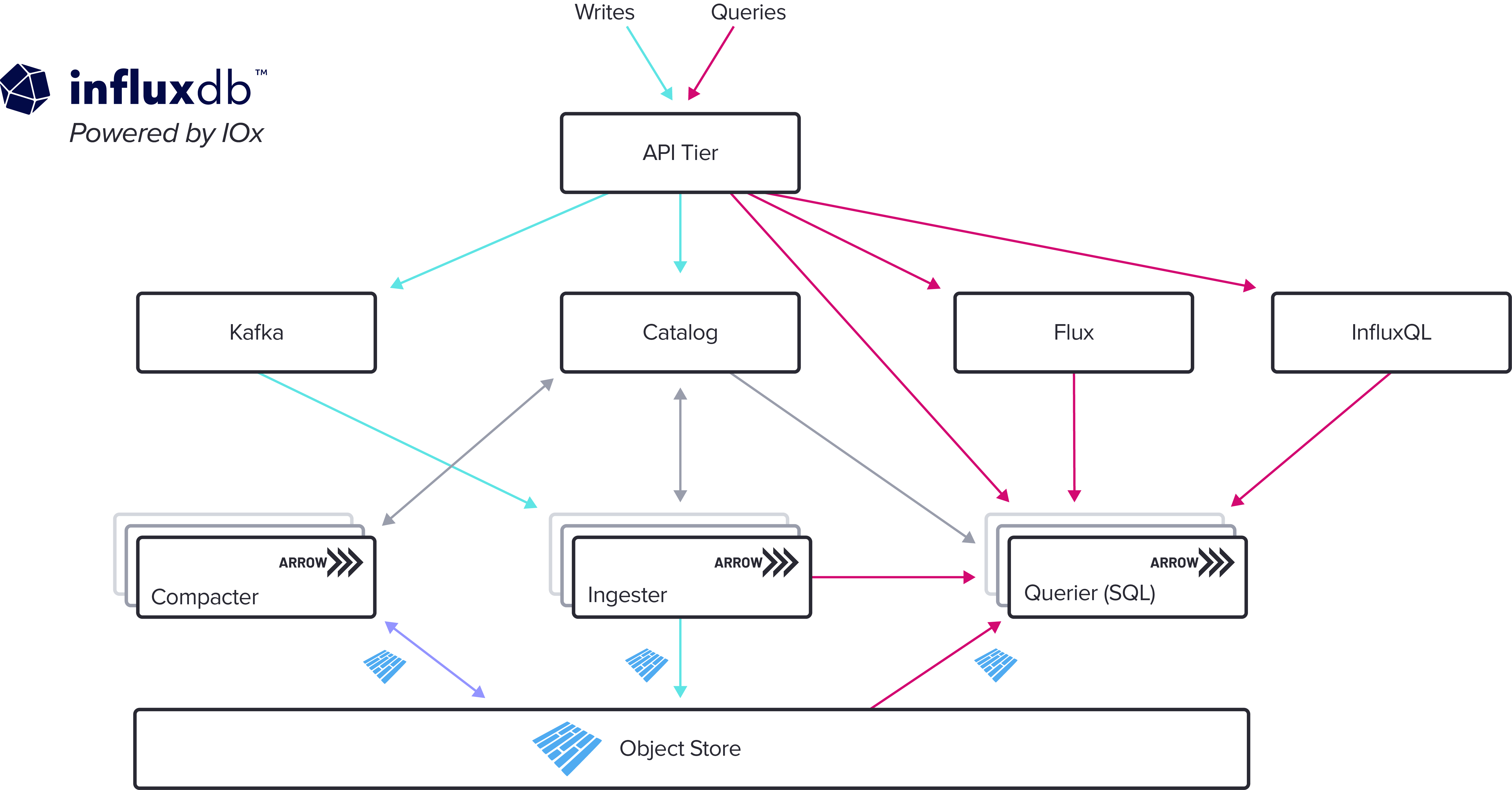
InfluxDB IOx is a columnar time series database. Columnar databases represent their data as tables and let you execute queries very quickly and at scale. Basing our new engine on a columnar database solves performance problems in several ways. Per-column compression helps with space on disk. Dictionaries make sure you’re not repeatedly storing strings when you have tag values that apply to many timestamps and run length encoding helps with efficient storage for legitimate repeated values. Vectorized execution lets you organize data so that the CPU can run through it very quickly. And queries are parallelized to run faster.
One of the most important parts of the new engine is partitioning. With IOx, time series data is broken into partitions based on time (such as by days) and also by tags (such as regions). This lets you easily filter out sections of data that don’t fall into a query’s time range or other specification. Queries operate on all rows from included partitions one-by-one, and because of vectorized execution, IOx lets you query around 1 billion rows per second per core. This partitioning and incredibly fast query response means you can have large numbers of tags and still get real-time results to build dashboards and monitoring and alerting systems.
SQL support
InfluxDB IOx was written in the Rust programming language and uses Apache Parquet files for on-disk storage and Apache Arrow for operations between components. Apache Arrow is an in-memory specification for columnar data that makes analytical queries very fast. IOx also uses the DataFusion library, a native SQL query engine, as its parser, planner, optimizer, and execution engine. This means that for the first time InfluxDB supports the PostgreSQL dialect and wire protocol allowing you to connect to third-party libraries and BI tools like PSQL, Grafana, Tableau and Apache Superset. Compatibility is a key focus at InfluxData and this new engine supports many querying options. In addition to the new SQL support, InfluxDB IOx continues to support versions of the API and our own query and scripting languages. In the API layer you can communicate with the new engine using the 1.x or the 2.0 API, and you can query the database using Flux, InfluxQL, SQL, or any of the 12+ client libraries we offer.
Sign up for the InfluxDB IOx Beta program
You can sign up to be a part of the InfluxDB IOx Beta program here. You’ll get the SQL compatibility, unbounded cardinality, and faster performance within InfluxDB Cloud. If you use OSS or InfluxDB Enterprise you can expect builds next year with the new engine, these compatibility layers, and migration tooling.
