Introducing the Next-Generation InfluxDB 2.0 Platform
By
Russ Savage
updated December 14, 2025
Product
Company
Navigate to:
Today, we are proud to give you alpha access to the next generation of InfluxDB. We’ve taken our original mantra of Fastest Time to Awesome to a whole new level, and we can’t wait to share it with you. You can find links to download the latest build on our website. I’m going to walk you through what you can do in the Alpha. For a broader vision of InfluxDB 2.0 Platform, check out this post from our CTO, Paul Dix.
Everything you need in one binary
The first thing you’ll notice about InfluxDB 2.0 is that there’s only one thing to download and install. Users who have installed the TICK Stack in the past might be wondering how to get data into the system, visualize that data, and process it.
InfluxDB 2.0 contains everything you need in a monitoring platform in a single binary. This allows us to provide a simplified setup experience while maintaining the power and flexibility of individual components.
Users, organizations, and buckets
When you start up InfluxDB 2.0 for the first time, you’ll be asked to set up a few things. Our updated onboarding experience walks you through the process in one easy step. Everything you do in InfluxDB 2.0 requires you to authenticate as a user. This helps ensure a single unified access control across all components of the platform including querying data and building dashboards.
You’ll also need an organization, which acts as a workspace for you and your colleagues to share things like dashboards and queries, as well as a bucket, which is where you store your time series data with a retention policy.
Your data, fully loaded
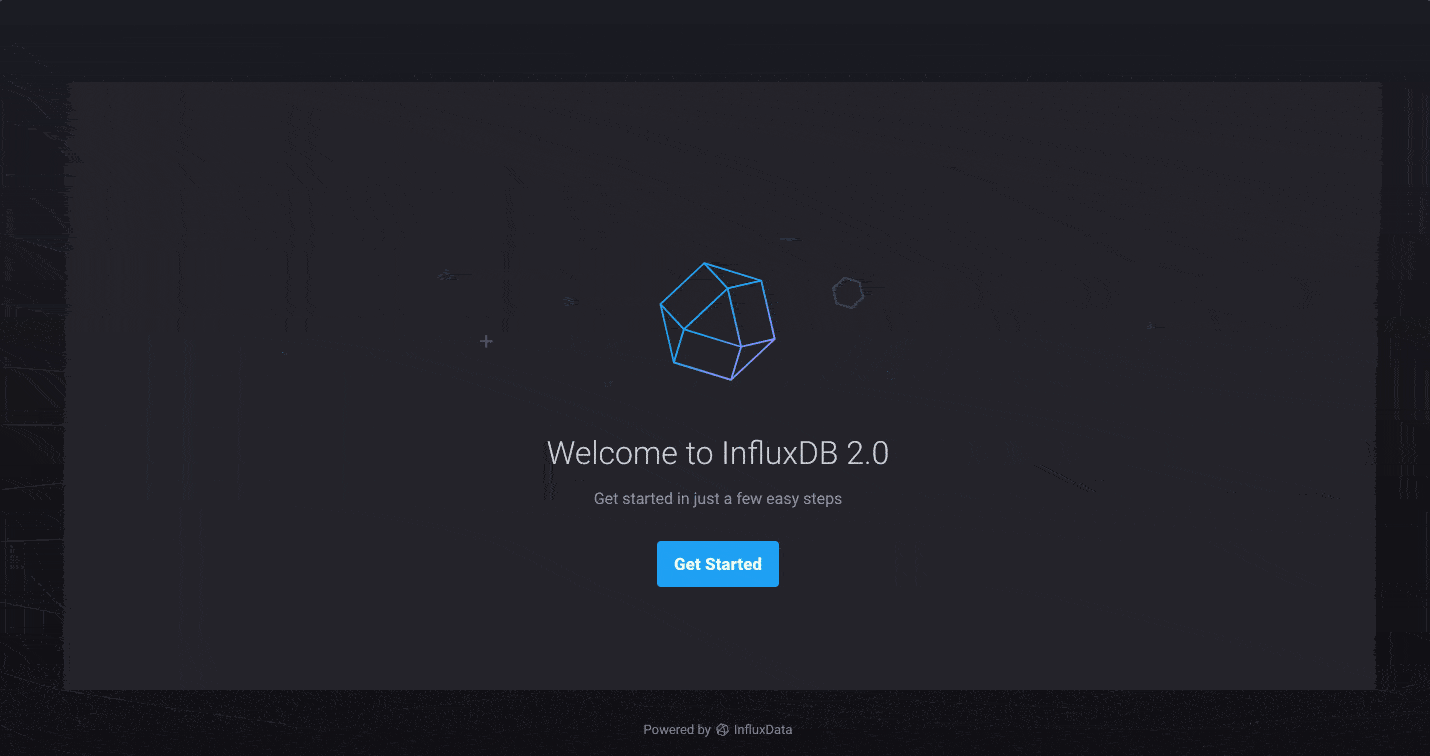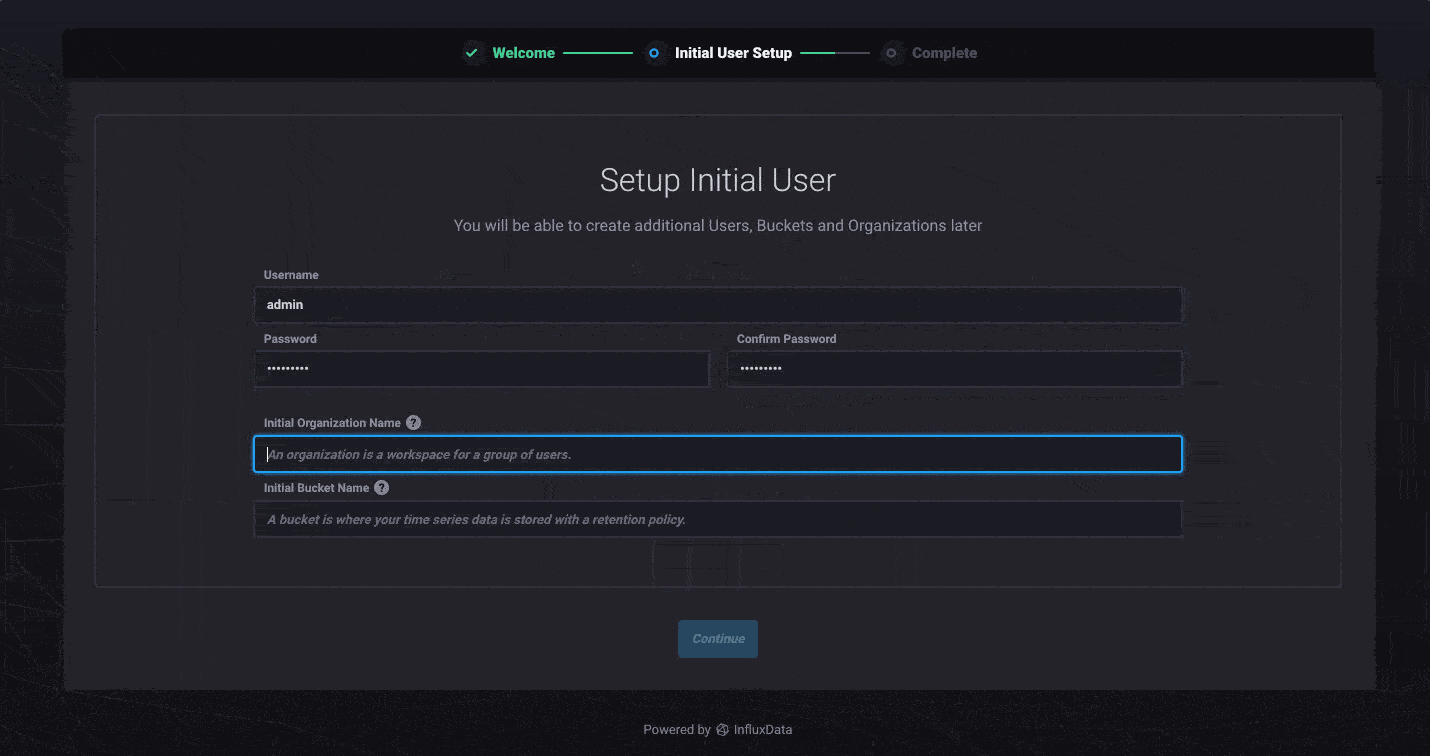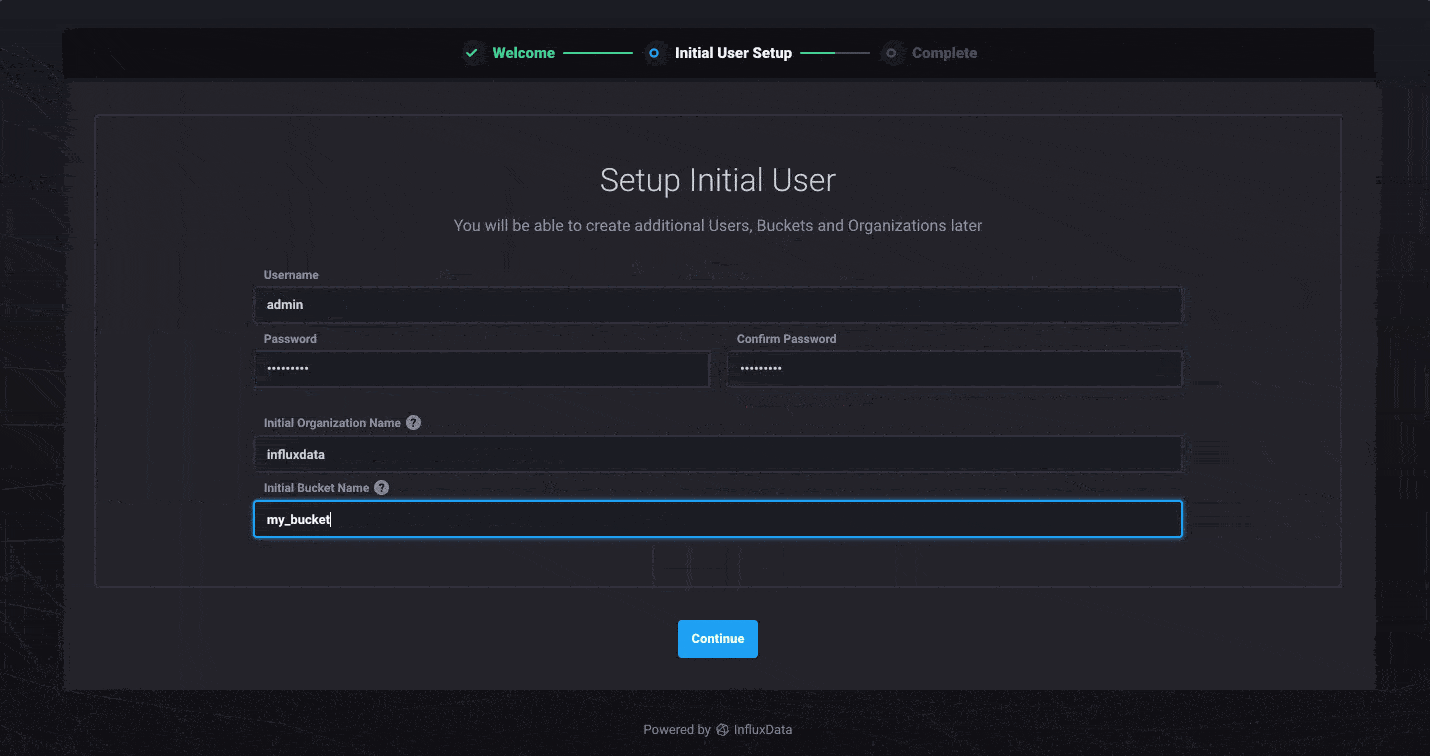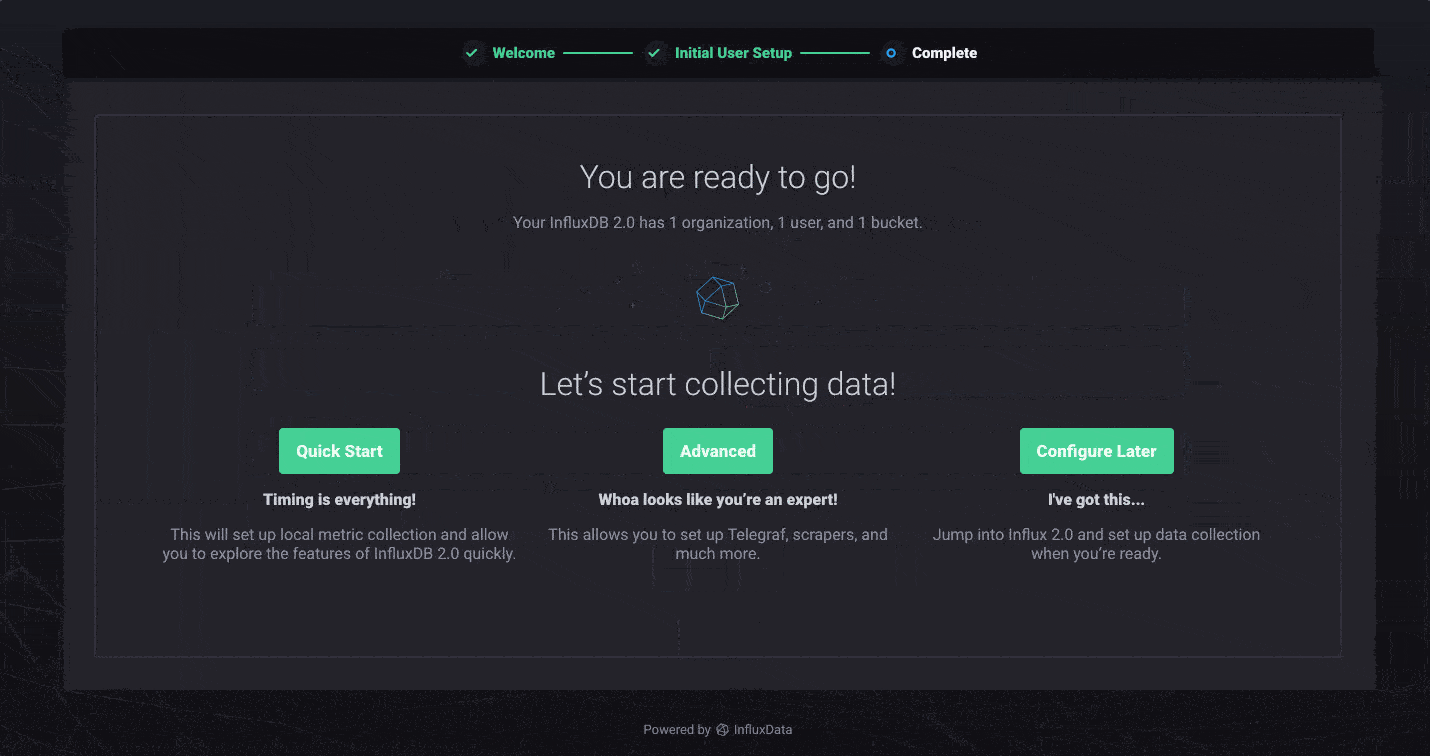
InfluxDB 2.0 comes with a few ways to quickly load data into the platform. First, we’ve added native Prometheus metric scraping directly into the platform, so you can pull data from anywhere without additional software. Simply add a new Prometheus scrape target through the browser and watch as your metrics start flowing into the system. The “Quick Start” path from onboarding automatically configures the InfluxDB 2.0 scrape target and populates your instance with metrics about itself. If you are just looking to explore the Alpha, this is the quickest path to ingest data and get started.
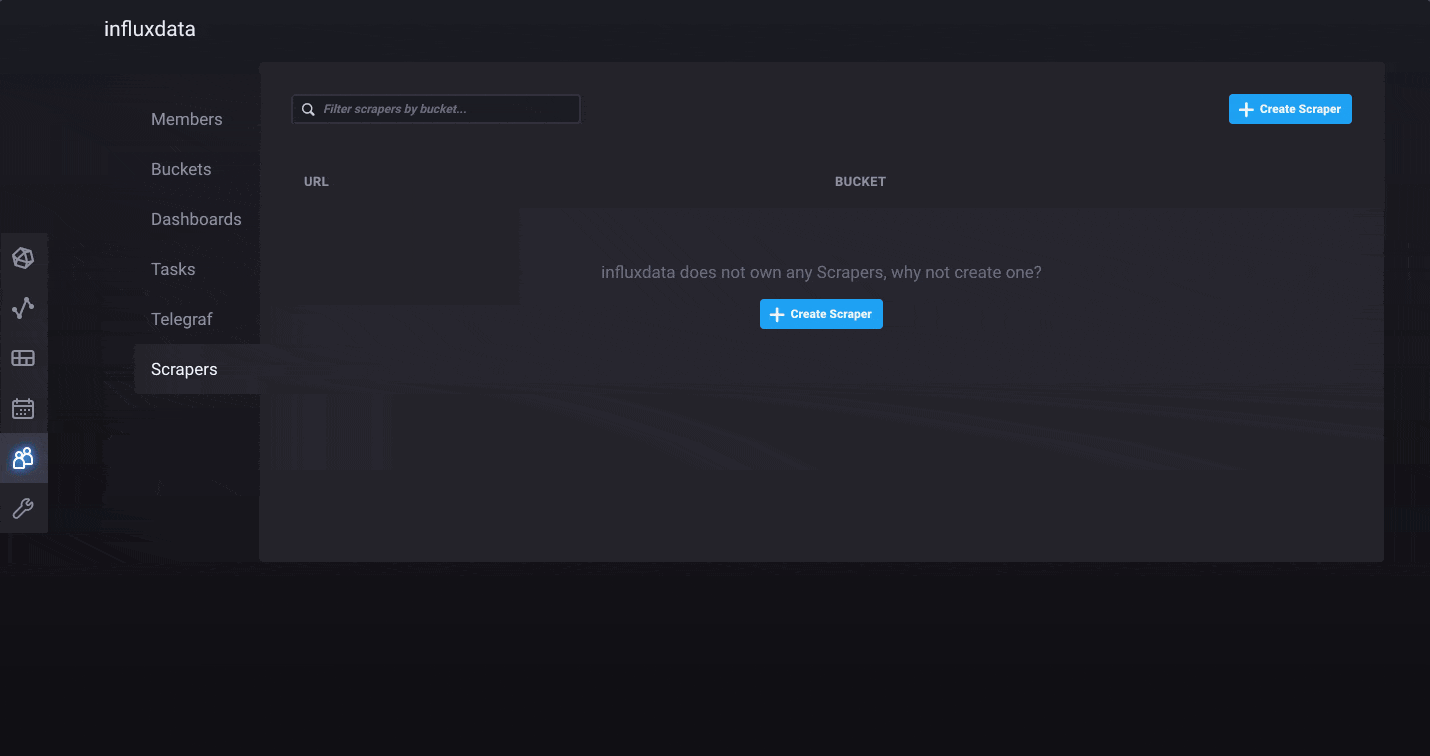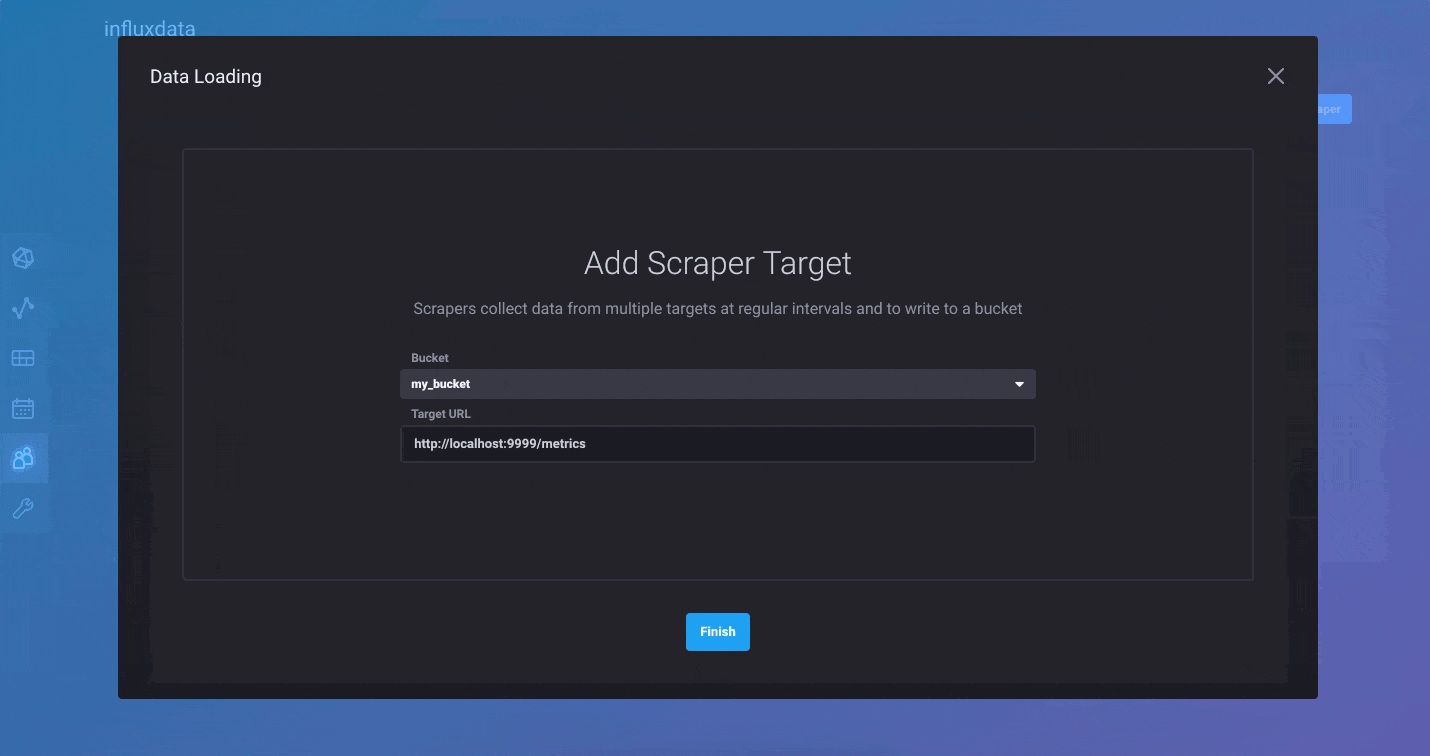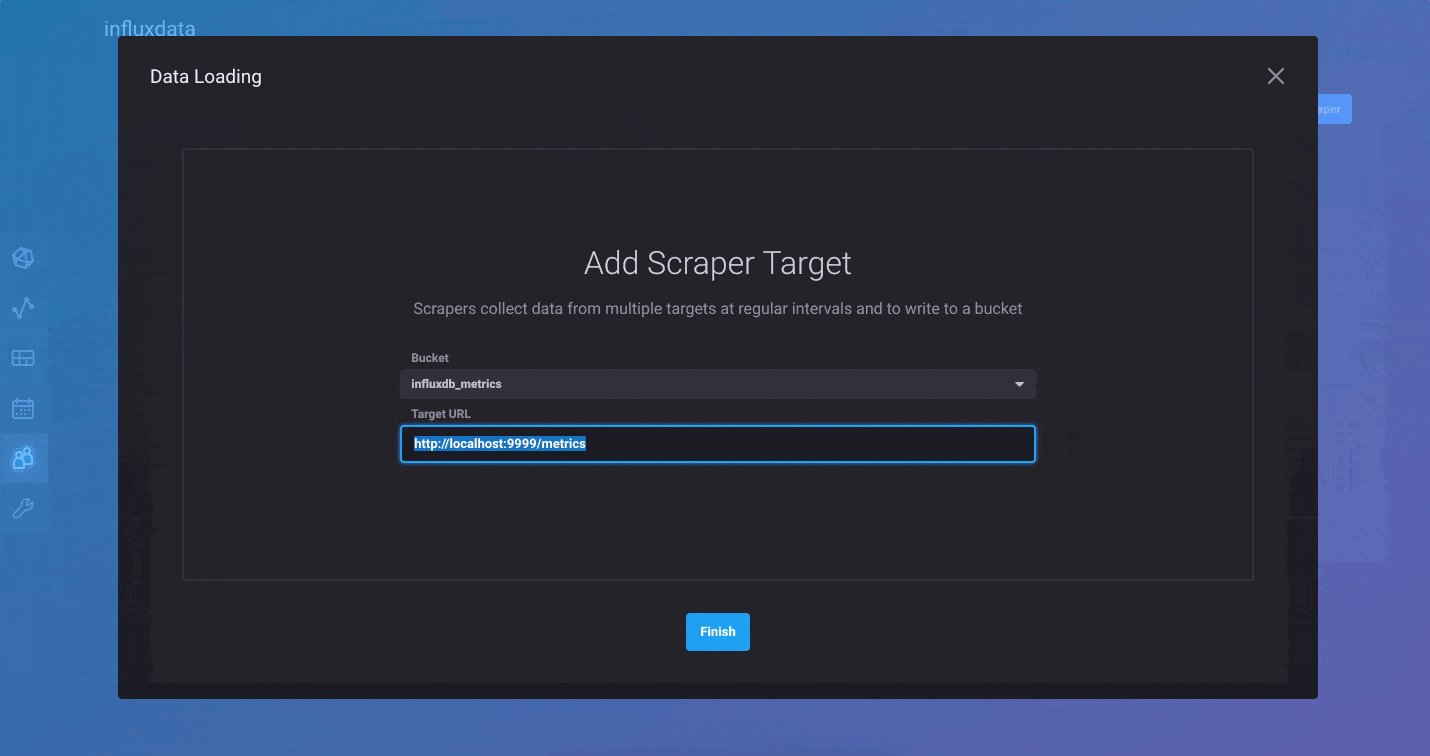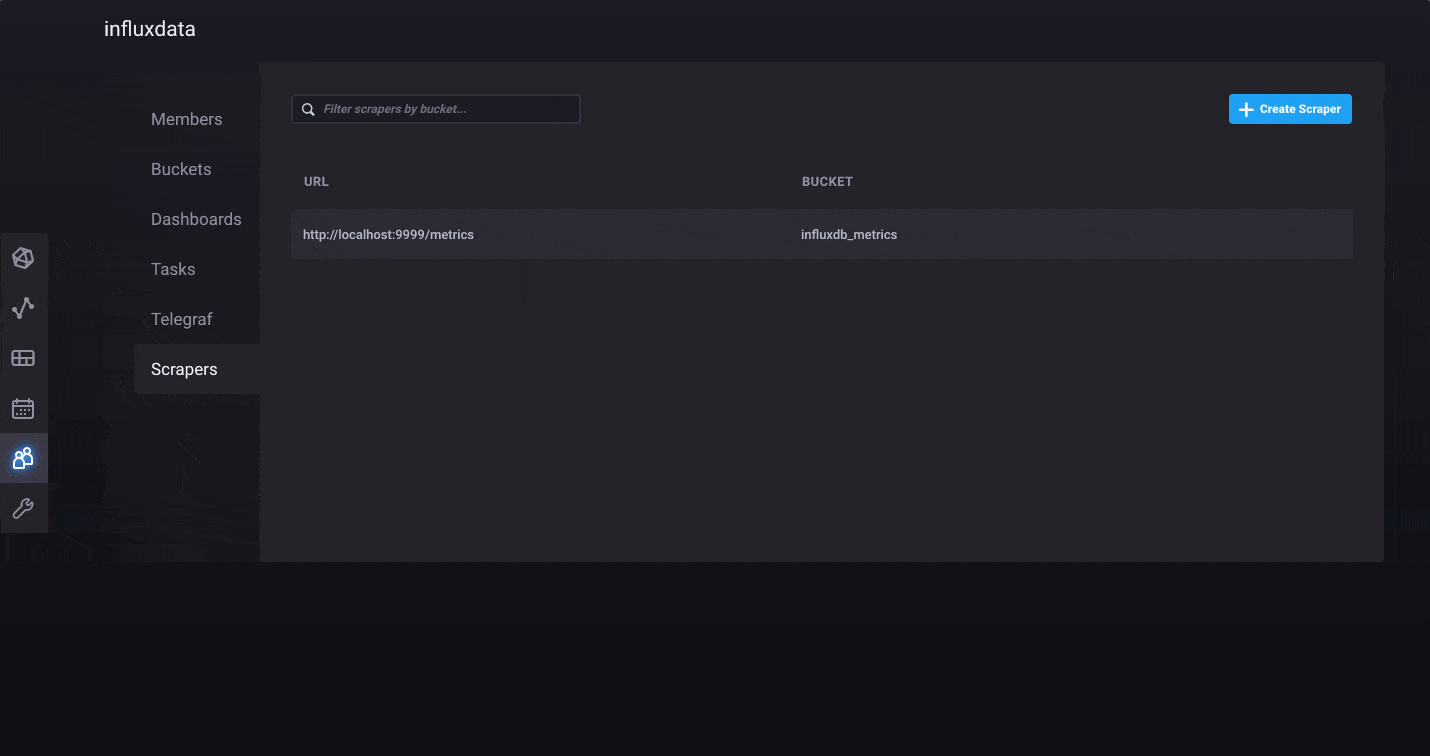
For those of you who prefer to push your metrics into InfluxDB, you can continue to use the Telegraf collection agent. We’ve made it easier than ever to create Telegraf configurations and distribute the agents wherever they are needed. We’ve added a Telegraf agent configuration option in the InfluxDB 2.0 user interface. This allows you to quickly build a Telegraf configuration file and best of all, InfluxDB 2.0 stores the configuration so Telegraf 1.9 (or above) can pull it remotely. It’s the fastest and easiest way to build a Telegraf agent configuration.
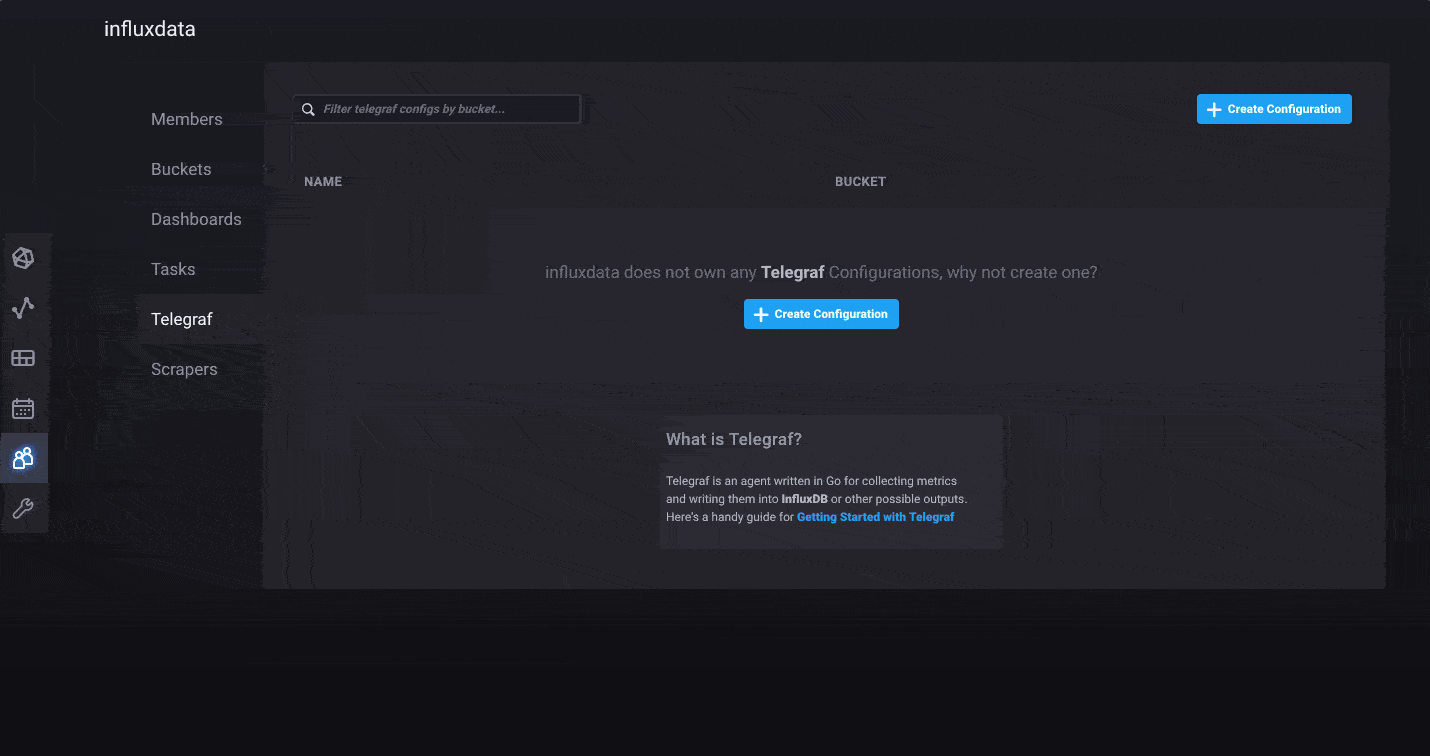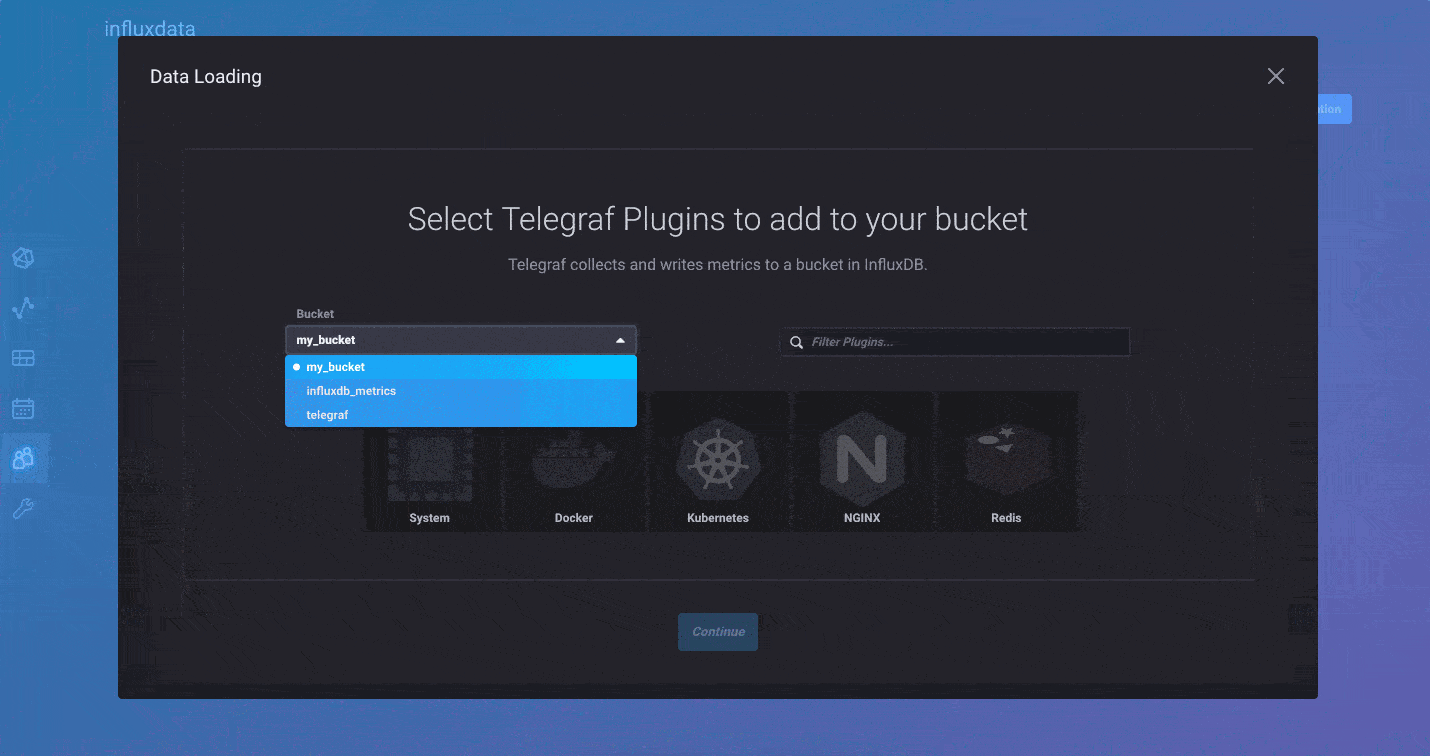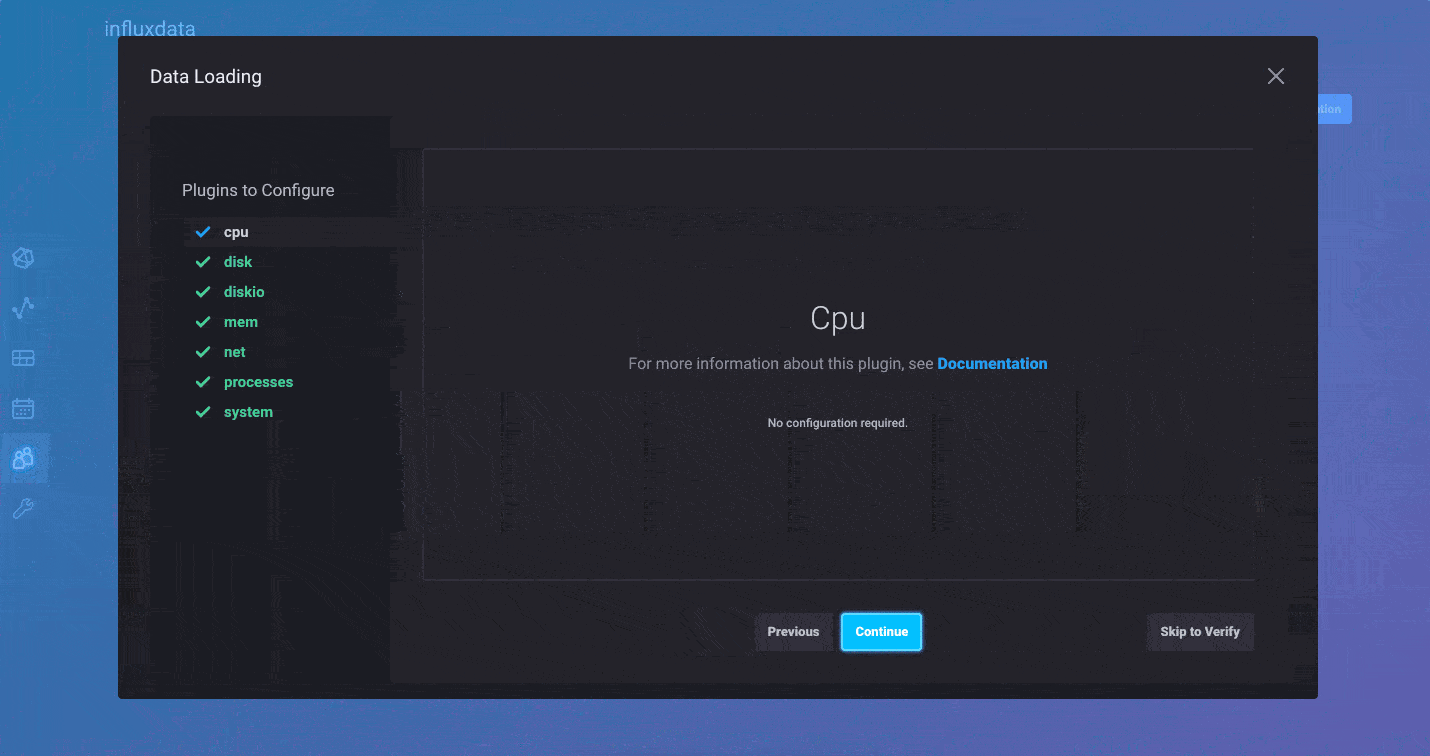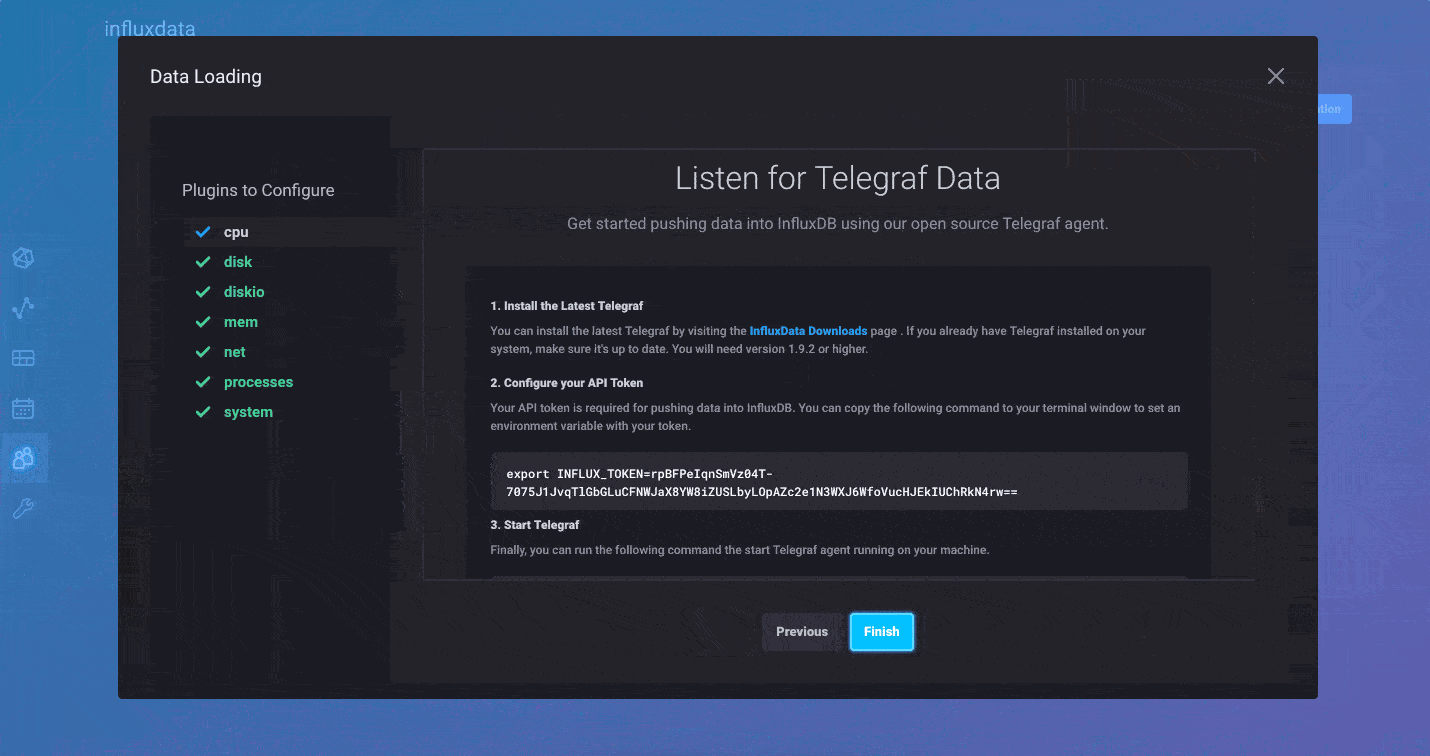
And finally, for users that already have data in Line Protocol, you can upload those files directly via the browser as well. Just select the Line Protocol option when you add data to your bucket, and you’ll be able to upload raw line protocol files from your local machine into the designated bucket.
Never stop exploring (your data)
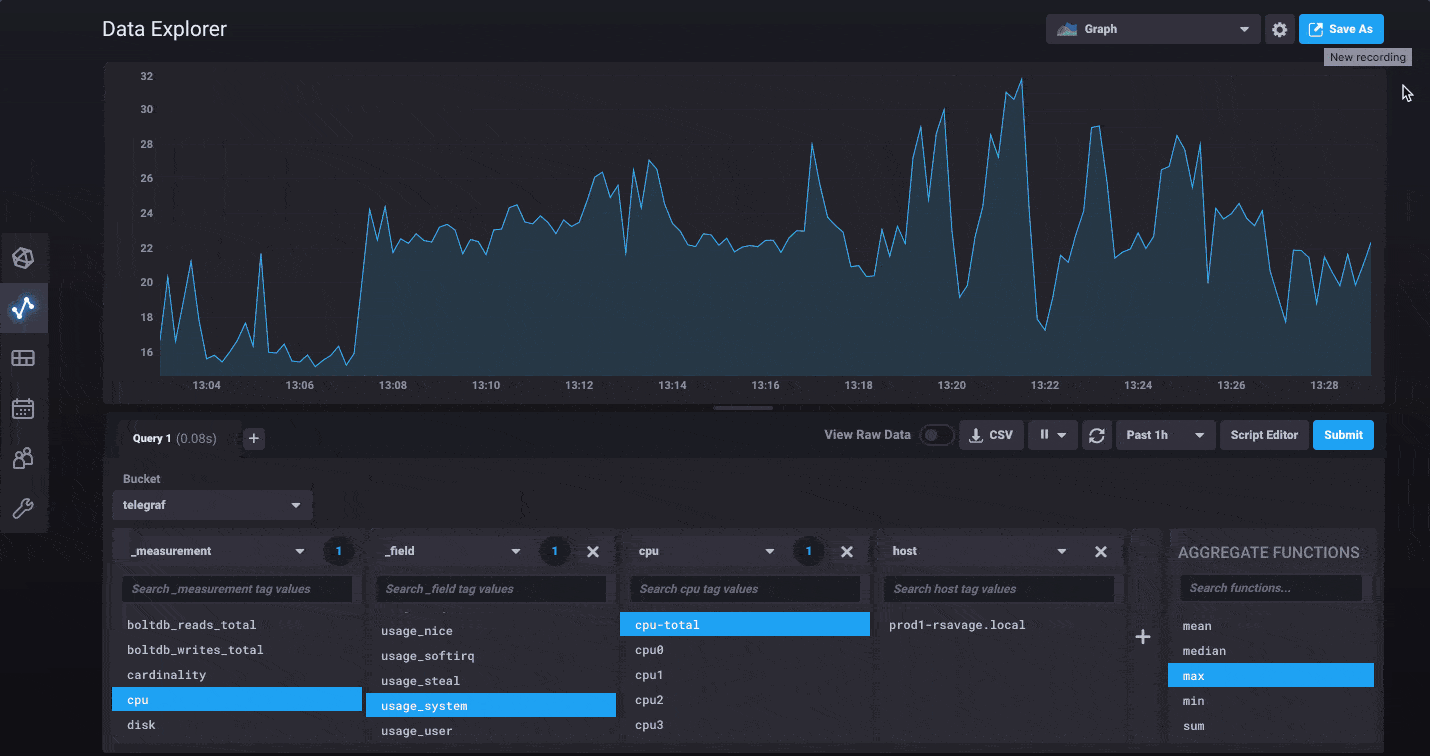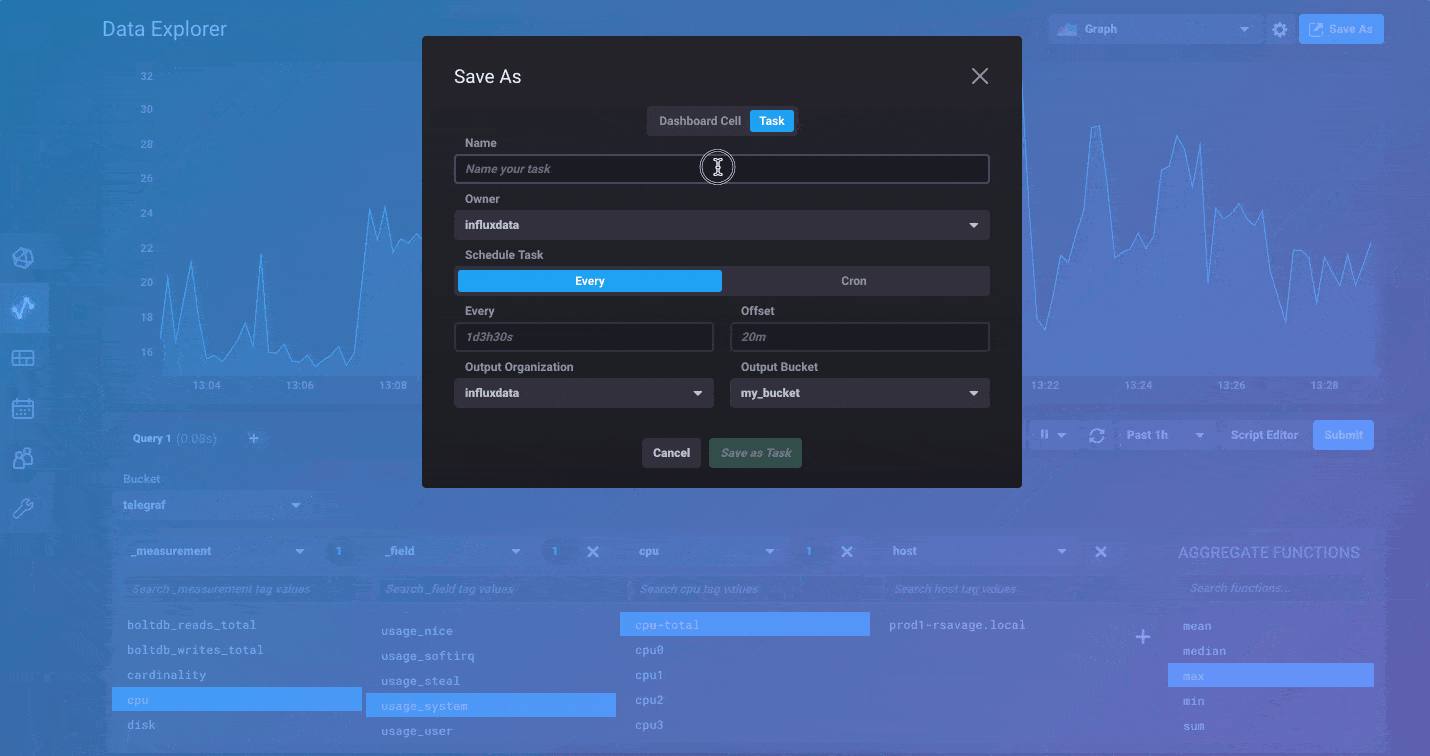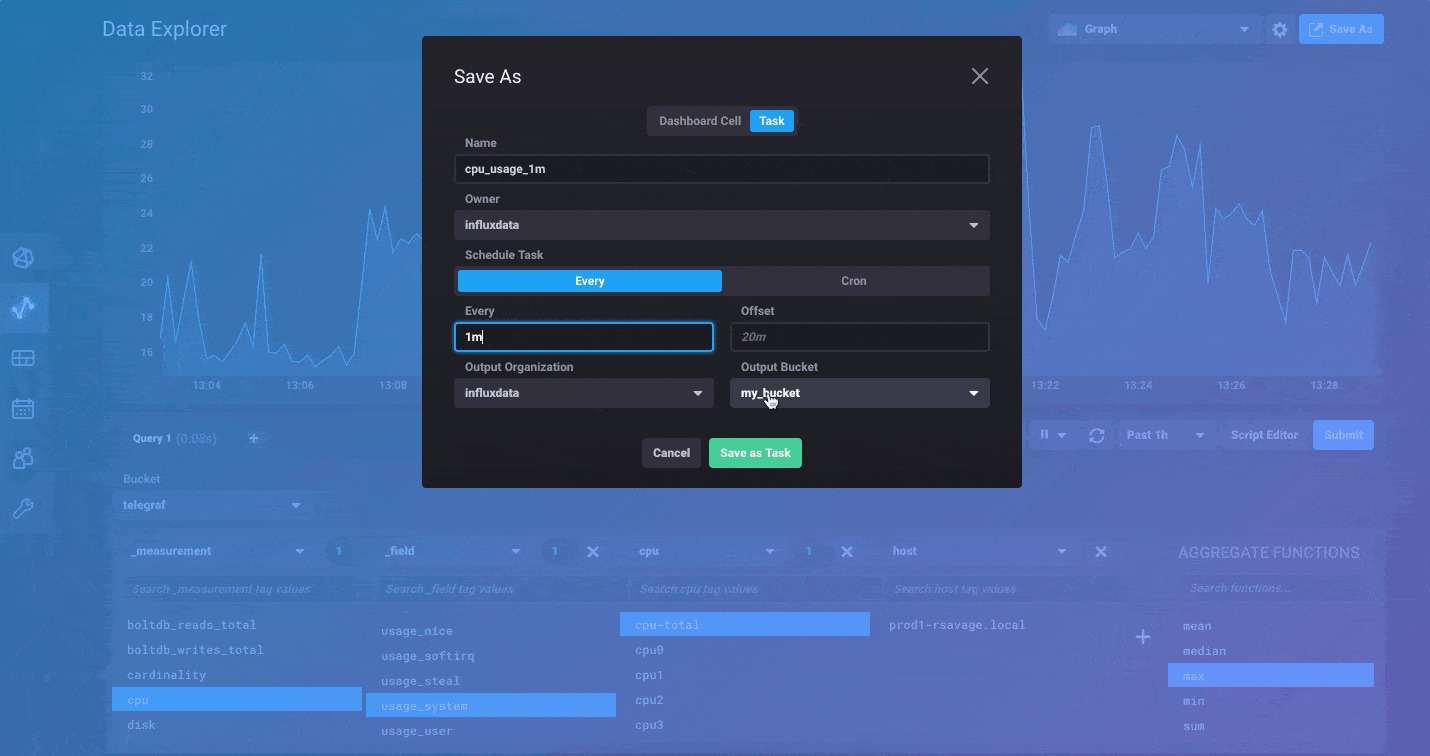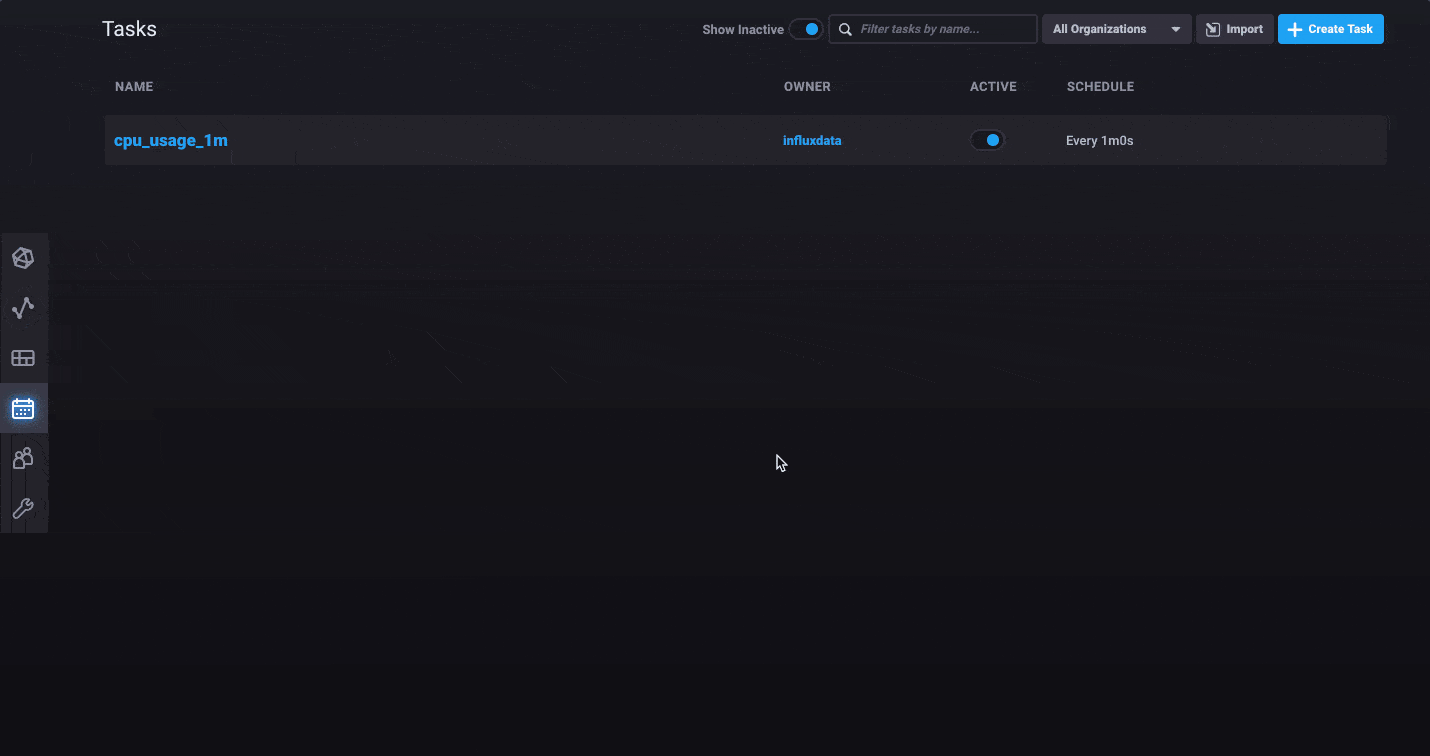
InfluxDB 2.0 has a whole new Data Explorer that makes it easier than ever to quickly visualize your data. The new explorer allows you to harness the flexibility of Flux by allowing you to select any measurement, tag or field you’d like to filter with and going from there. Would you like to see what tags and fields are being collected from a specific host? Simply filter by that host first, then continue refining using additional tags and fields specific only to that host.
For power users, we’ve made it easy to switch to edit the raw Flux query powering your visualization behind the scenes. You can dive in and start customizing to your heart’s content. We’ve also updated the documentation for all the functions available in Flux today.
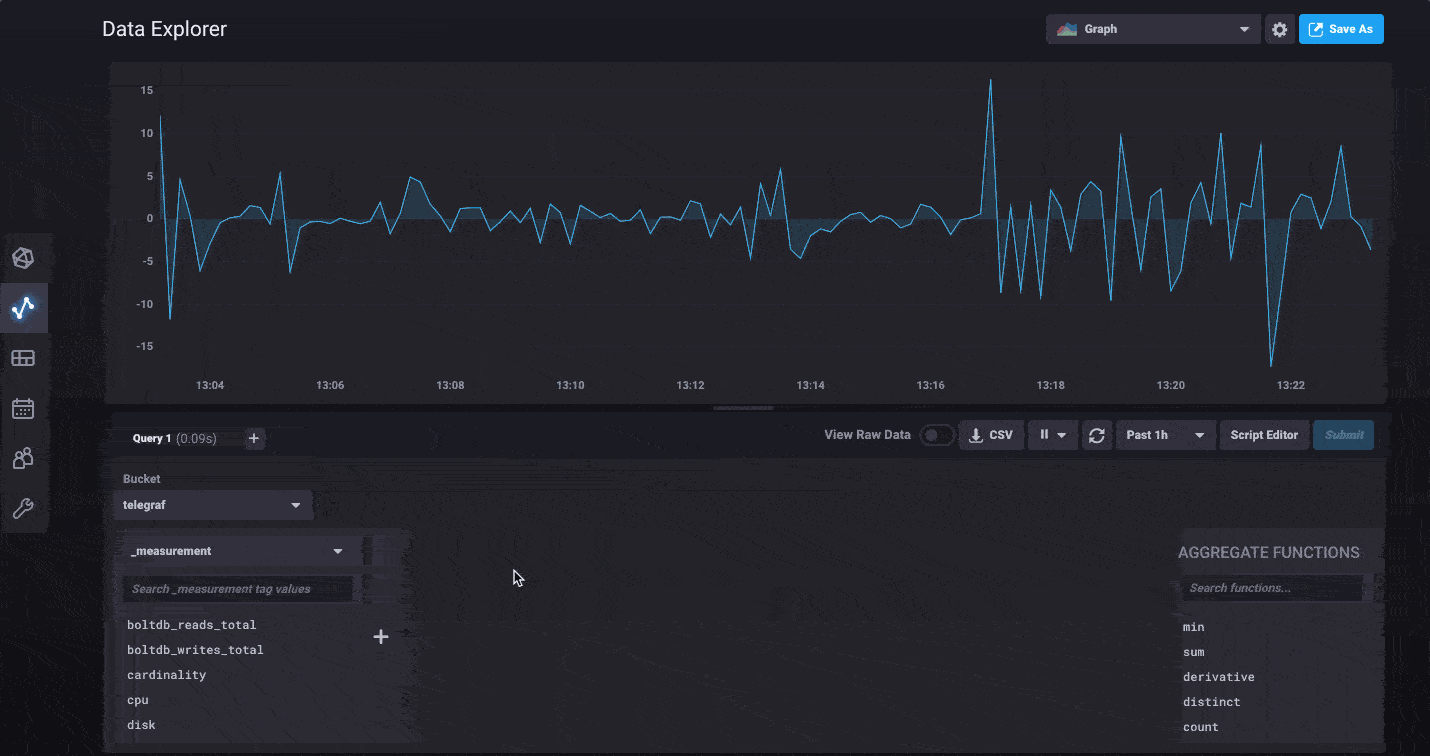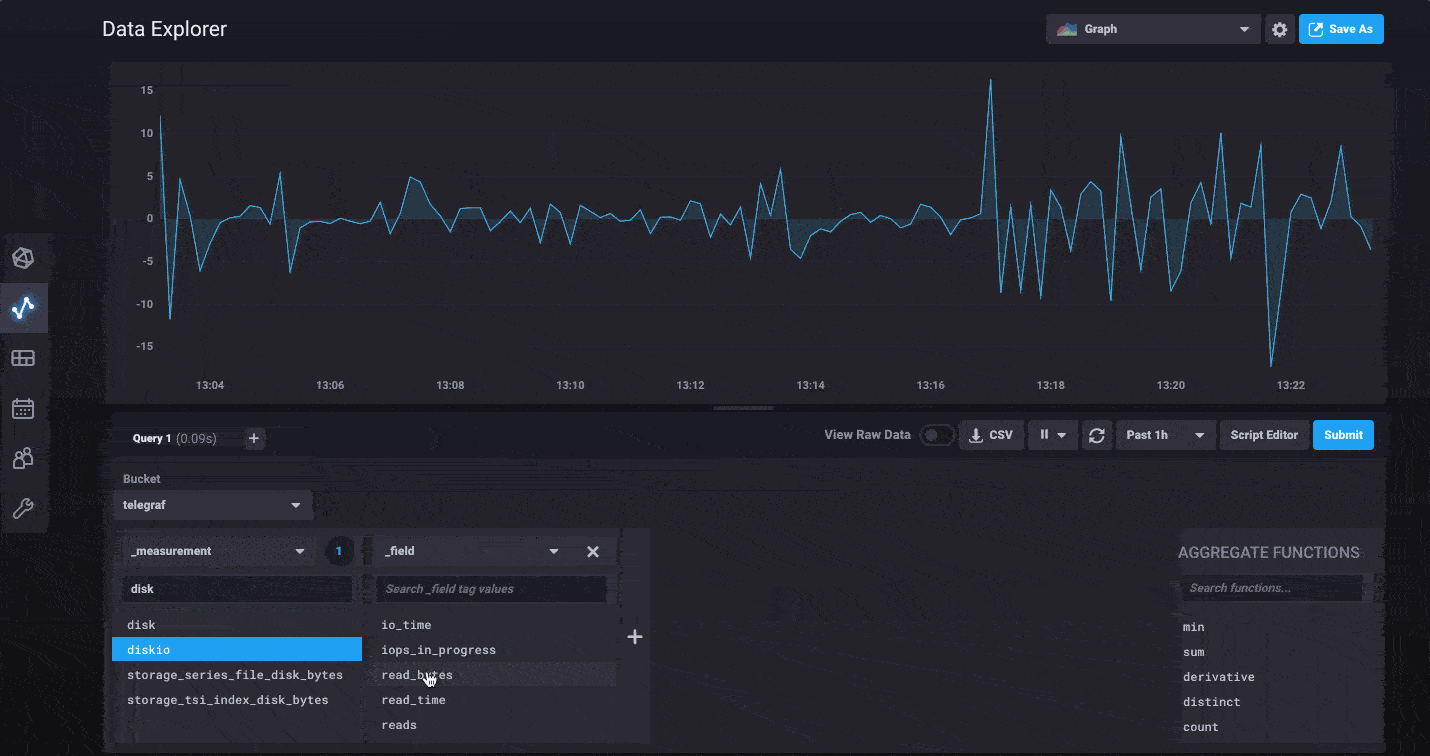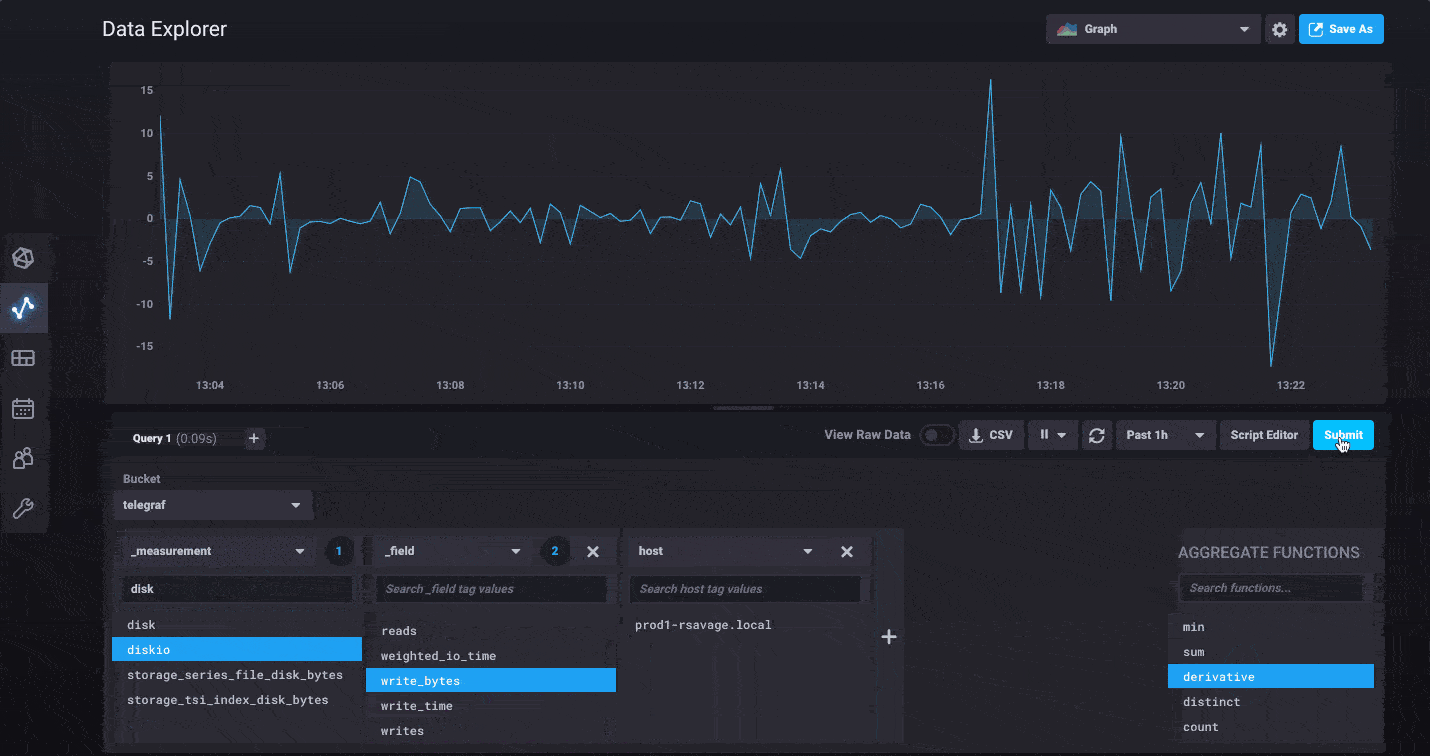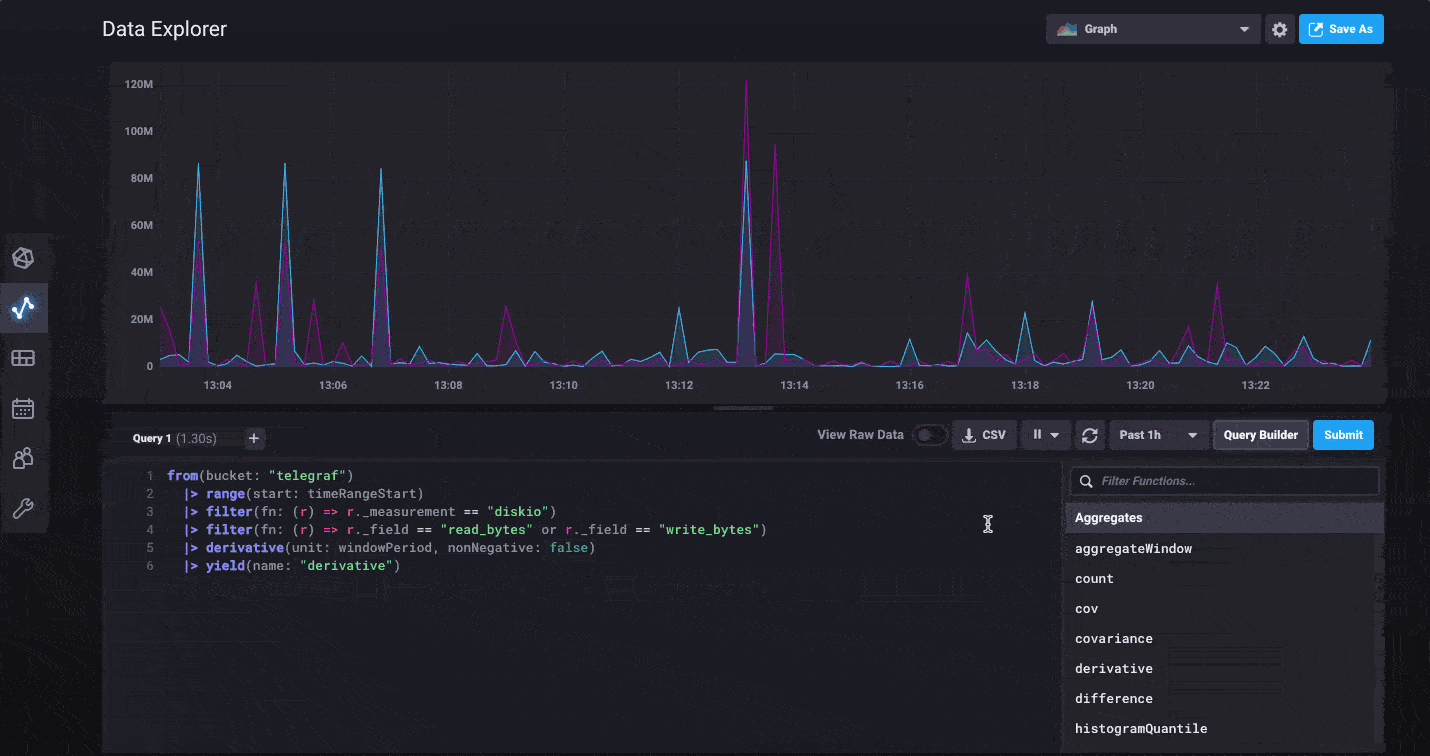
Finally, once you’ve got your query and graph absolutely perfect, use the Save As feature to quickly save it to a dashboard or create a new task for scheduling it to run.
Tasks: schedulable Flux queries for aggregations and more
Tasks are the brand new way to execute queries on a schedule and store the results. You could use tasks to build advanced aggregation scripts for analyzing time series data over a longer period of time, similar to how you might use continuous queries within InfluxDB 1.x. Soon we’ll have integrations in Flux to send data and alerts to third party systems, making Tasks useful for monitoring and alerting in addition to aggregation. This is similar to the anomaly detection and alerting functionality from Kapacitor via TICKscripts, but instead of a separate language for queries and tasks, we’ve unified these concepts with Flux.
Tasks can be completely managed through the Tasks page in the UI, but the easiest way to create a task is to start from the Data Explorer, verify the shape of the data you’d like to save, then use the Save As option to create a task from that query. You’ll be able to set the bucket you want to store the results in when you create the Task. Of course, you can also create new Tasks from scratch using the Add Task option.
The power of the command line
I’ve been highlighting the features and capabilities of the browser, but we also have a fully featured command line interface for interacting with InfluxDB 2.0. From the command line, you can do everything you can in the browser. The command line also contains an interactive shell for writing Flux queries, and the ability to script queries easily. Give it a spin and let us know what additional capabilities or enhancements you’d like to see.
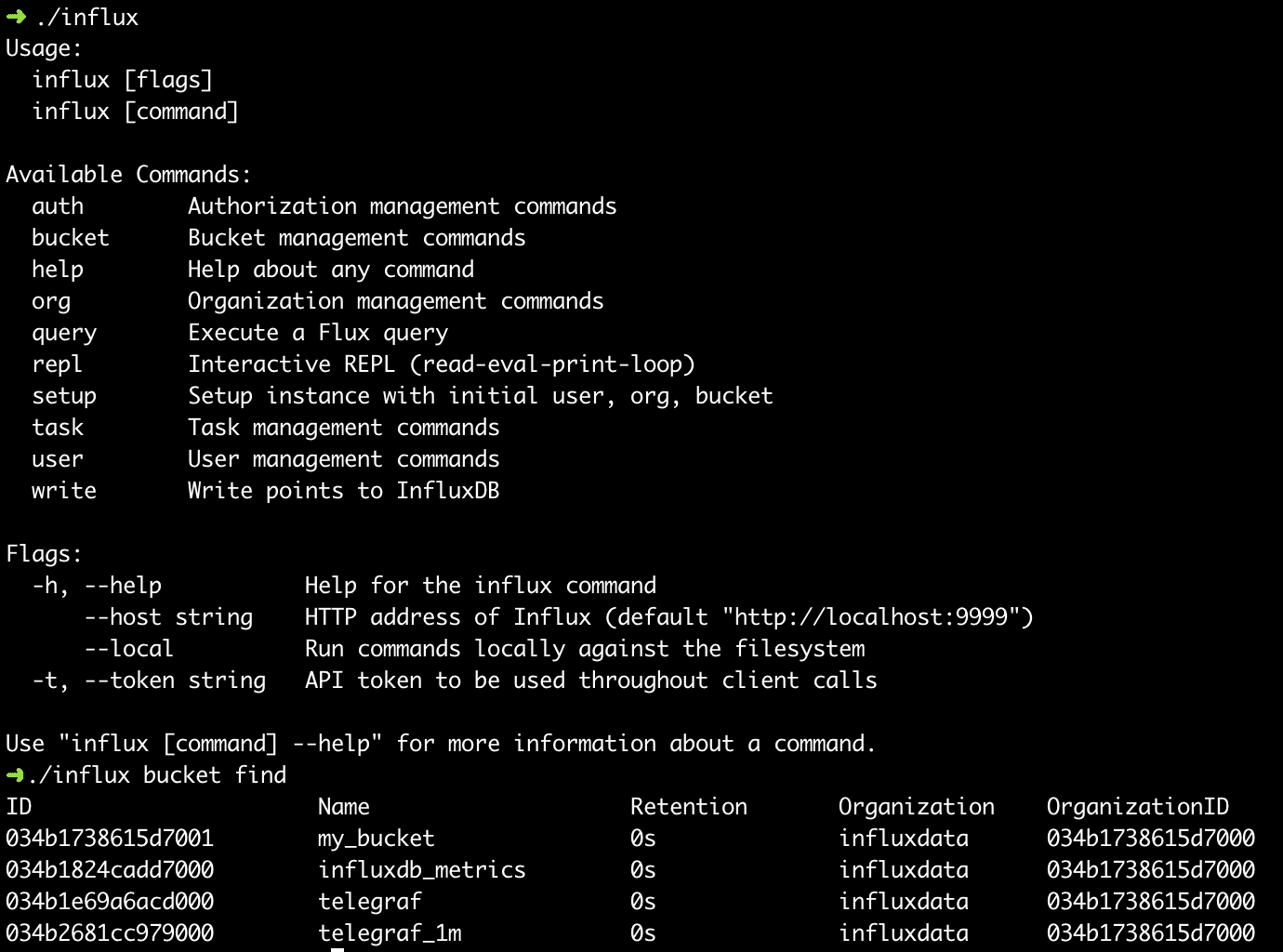
Unified API
Everything you see in the browser and the command line is backed by a unified API that’s documented in this Swagger file. This allows us (and community members) to quickly create their own applications on top of this new platform. We are going to start with libraries in Go and Javascript and then move onto other languages (Java, Ruby, C#, Python, Kotlin, PHP, C are all planned) as we see what our users are building with. With the API you should be able to automate and manage everything from the creation of users and access tokens to dashboards to tasks all through your own code.
This is only the beginning
This is our first release of the new vision for InfluxDB, and we plan to keep iterating on it until we are satisfied that it meets our and more importantly our community’s standards for software. But we can’t do it alone.
We need your help. We are asking for your feedback on all aspects of the alpha to make it amazing for developers to use. If you find yourself having trouble figuring out how to do something, or see behavior that doesn’t quite make sense, we want to hear about it. Please open issues for anything you would like to see improved, so we can take a look. Anticipate running into bugs as with any new software. In weekly updates, we plan to tackle the most serious ones and continue to iterate based on the feedback we receive.
Thank you to all the developers and community members who help make this software. Great open source communities make the best open source software. Together, let’s build the next-generation time series platform!
