Mage.ai for Tasks with InfluxDB
By
Anais Dotis-Georgiou
Sep 22, 2023
Product
Navigate to:
Any existing InfluxDB user will notice that InfluxDB underwent a transformation with the release of InfluxDB 3.0. InfluxDB v3 provides 45x better write throughput and has 5-25x faster queries compared to previous versions of InfluxDB (see this post for more performance benchmarks).
We also deprioritized several features that existed in 2.x to focus on interoperability with existing tools. One of the deprioritized features that existed in InfluxDB v2 is the task engine. While the task engine supported an extensive collection of Flux functions, it can’t compete with the vast amount of ETL tooling that already exists, specifically for data preparation, analysis, and transformation. Among those many tools is Mage.ai.
Mage is an open source data pipeline tool for transforming and integrating data. You can think of it as a replacement for Airflow. In this tutorial we’ll scrape the surface of using Mage.ai to build materialized views of our time series data in InfluxDB Cloud v3.
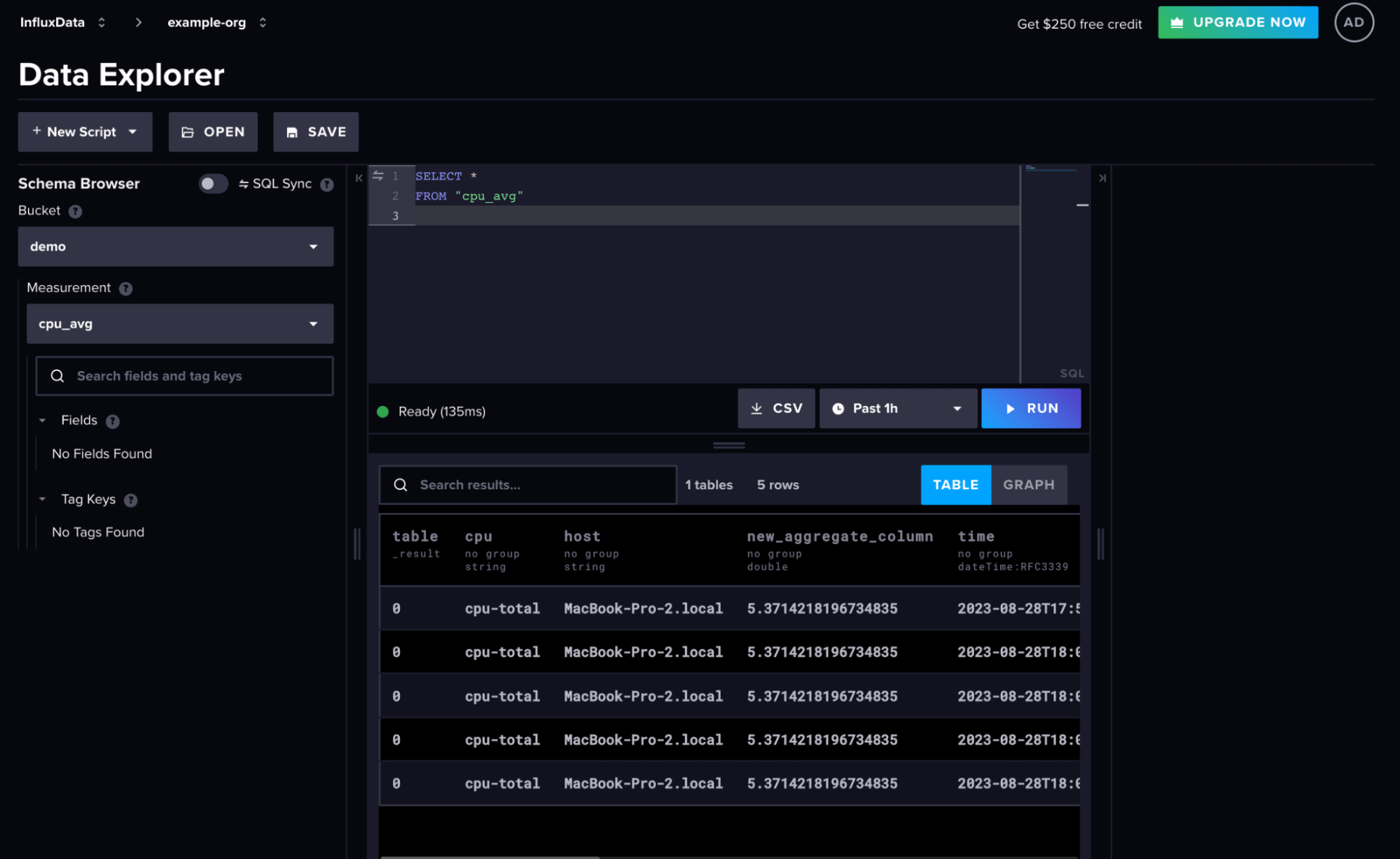
Introduction to Mage.ai
Mage is an OSS ETL tool. It comes with an easy-to-use UI that enables you to build data pipelines for data processing, data transformation, and machine learning. To learn more about Mage’s architecture take a look at the following documentation. My experience with Mage has been brief, and I’ve barely scraped the surface, but this is what I love about it so far:
-
Ease of use. The UX is intuitive and flexible. The prebuilt scripts make it easy to add code elements. Everything appears customizable.
-
Mage uses Polars and Parquet under the hood.
-
It allows you to create templates out of your pipelines, so you can easily share, duplicate, and manipulate your ETL pipeline.
-
It has an AI feature that will generate a pipeline for you from plain English.
-
There is fantastic community support. I was really impressed with, and grateful for the quality and responsiveness of my interactions with developers at Mage.ai.
-
You can connect to a variety of data sources out of the box.
The screenshot below shows an example of creating a template for a specific pipeline. After you’ve created the template you can simply click +New and load from an existing template to duplicate your pipeline.
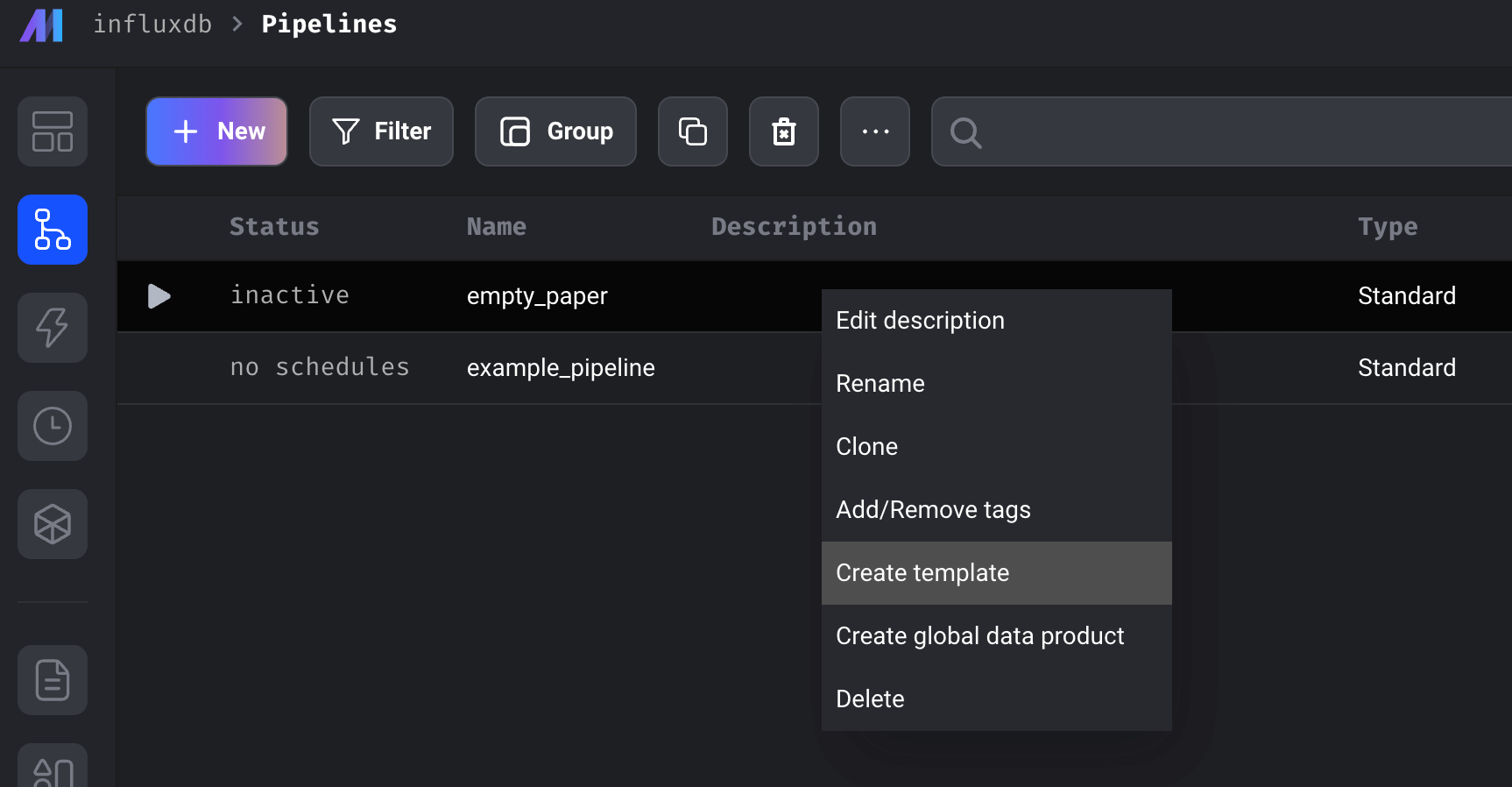
The only disadvantage to using Mage is that you’re responsible for deploying and managing the deployment of Mage yourself. Luckily, their documentation provides detailed instructions for how to do so on AWS, Azure, GCP and Digital Ocean, which ultimately provides users with more control and flexibility. They also have Terraform templates and Helm charts available.
Requirements
To run this tutorial you’ll need the following:
-
An InfluxDB v3 Cloud account.
- A database or bucket (that you’re querying data from and writing data to). For this demo I simply used the Telegraf agent to write local CPU data from my machine.
- An authentication token that allows you to read and write to that database
-
A Docker installation to run InfluxDB in a container.
You can follow this quickstart guide to learn more about how to use Mage. To replicate the example in this tutorial, clone this repo, and change directories into it and run the following command:
docker run -it \
-p 6789:6789 \
-e "TOKEN=<your InfluxDB token>" \
-e "DATABASE=<your InfluxDB database>" \
-e "HOST=<your InfluxDB host URL i.e. us-east-1-1.aws.cloud2.influxdata.com>" \
-v "$(pwd):/home/src" \
mageai/mageai \
/app/run_app.sh mage start testThen you can navigate to http://localhost:6789/ to see your Mage project and pipeline.
For this tutorial, we used environment variables for the Token, Host, and Database. However, you can also take advantage of Mage’s secret store.
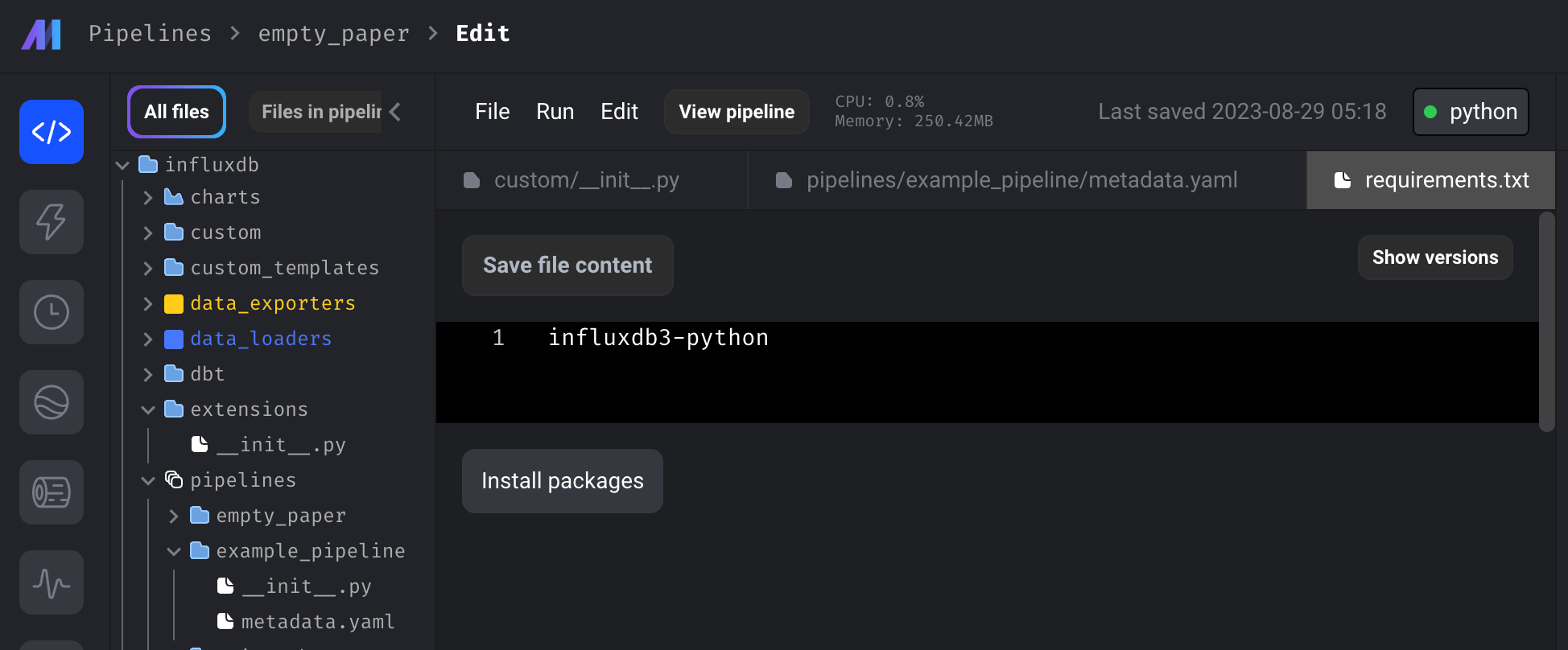
Once you start running the container, navigate to the requirements.txt file in the list of files. Click the Install packages command to install the InfluxDB v3 Python Client Library.
Now, you should be able to run the pipeline and even successfully run the triggers.
Creating materialized views with Mage
In this tutorial, we’ll learn about how to create a task that downsamples our data from InfluxDB. Specifically, we’ll build the following pipeline:
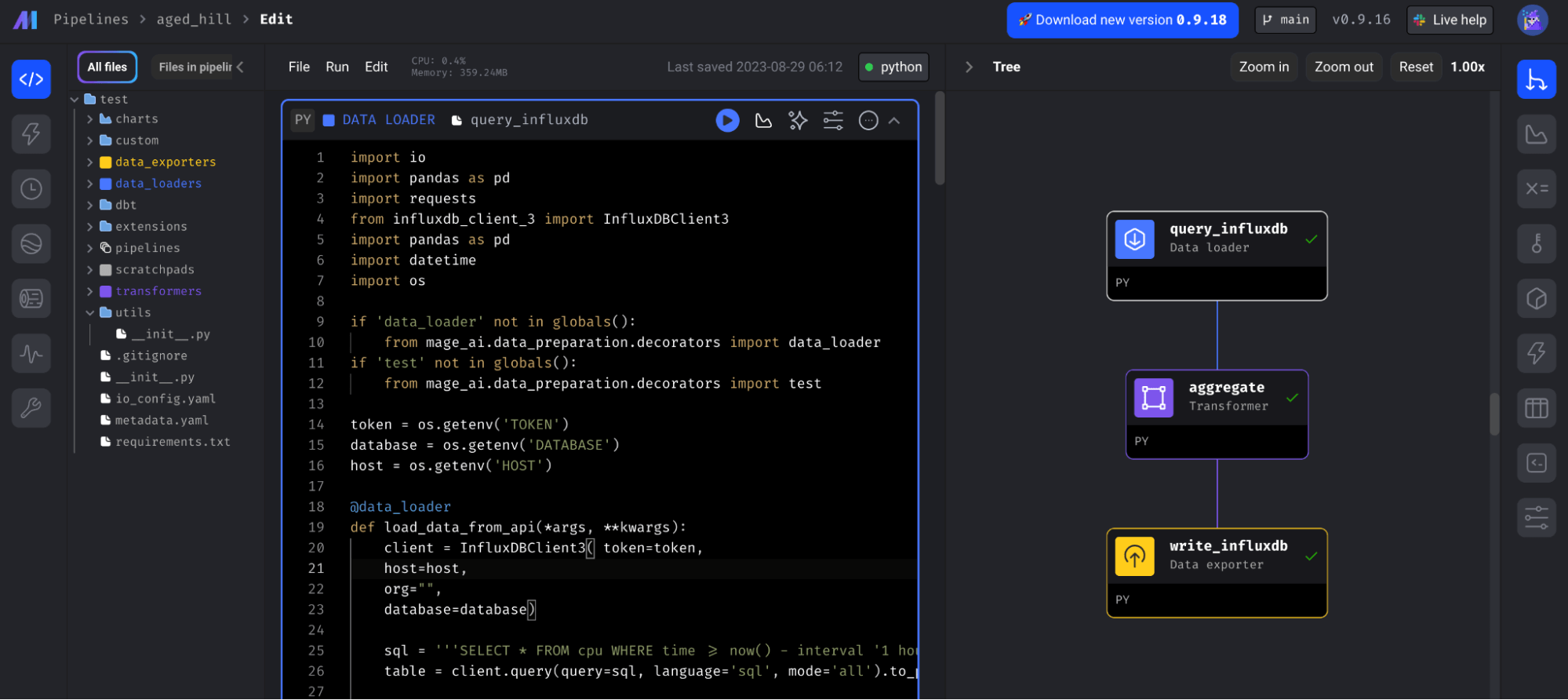
It contains three blocks:
-
query_influxdb: a loader data block that uses the Python InfluxDB v3 Client Library to query InfluxDB and return a Pandas DataFrame.
-
aggregate: a transformation block that creates the downsampled aggregate of the data.
-
write_influxdb: an exporter data block that uses the same client library to write the downsampled data back to InfluxDB.
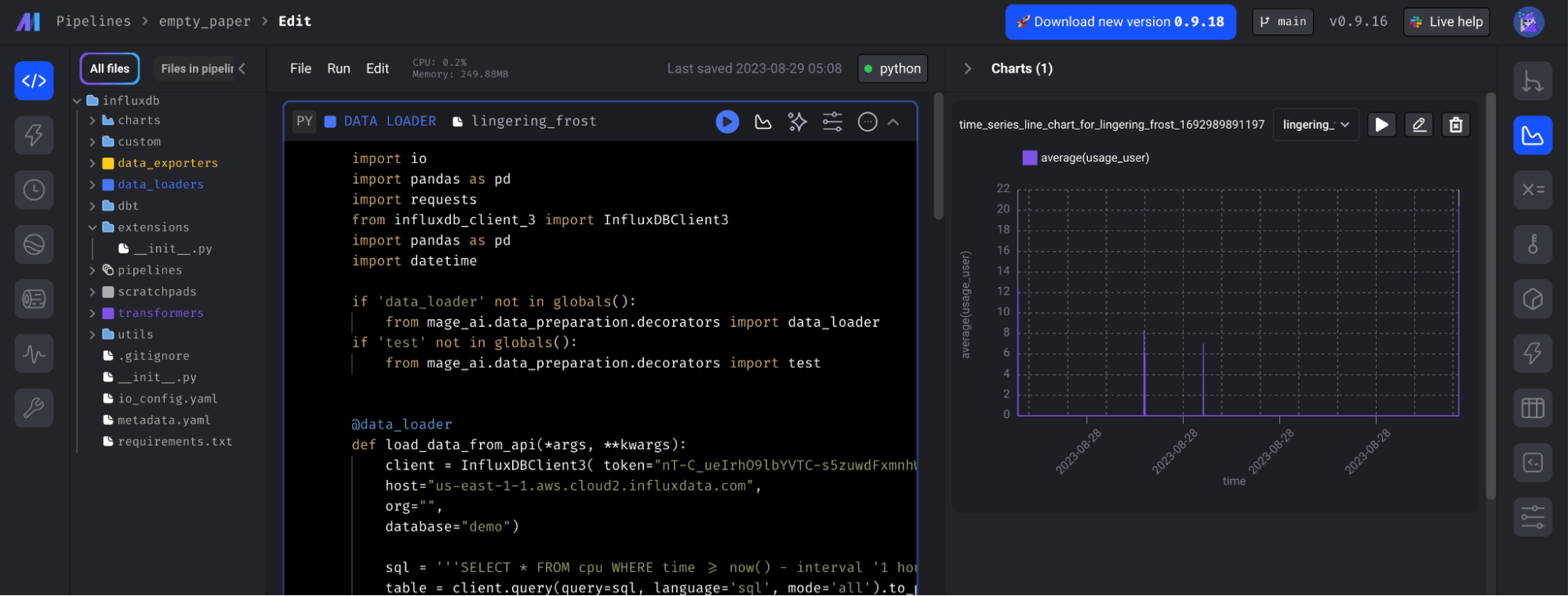
Additionally, notice how you can view the time series visualizations that were created as a part of this project. Simply click on the query_influxdb block and then click on the chart icon in the right-hand navigation panel.
Creating a trigger
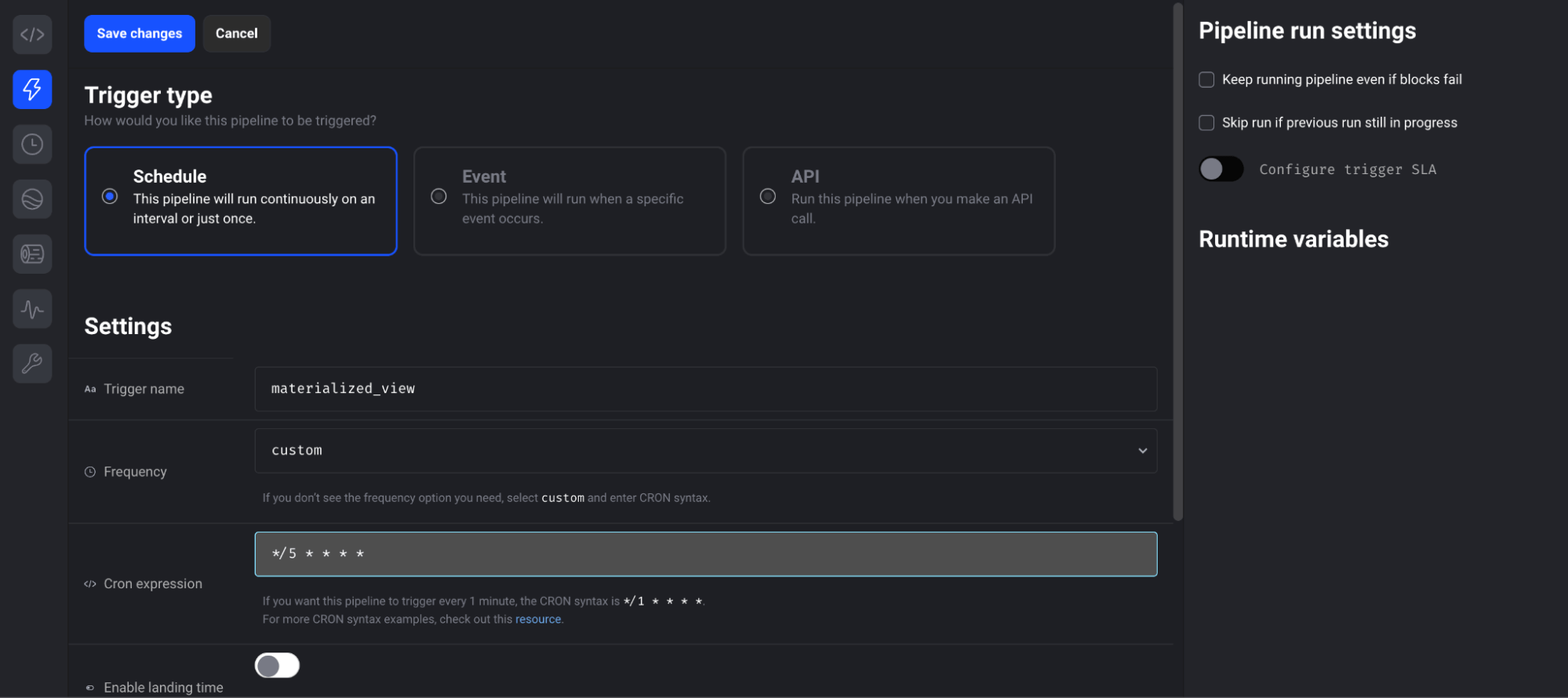
You can create a trigger to schedule this task to run on a regular interval. Navigate to the trigger page from the left-hand navigation bar. Then select Schedule Type and fill out the trigger settings. This pipeline is set to run in 5 min intervals.
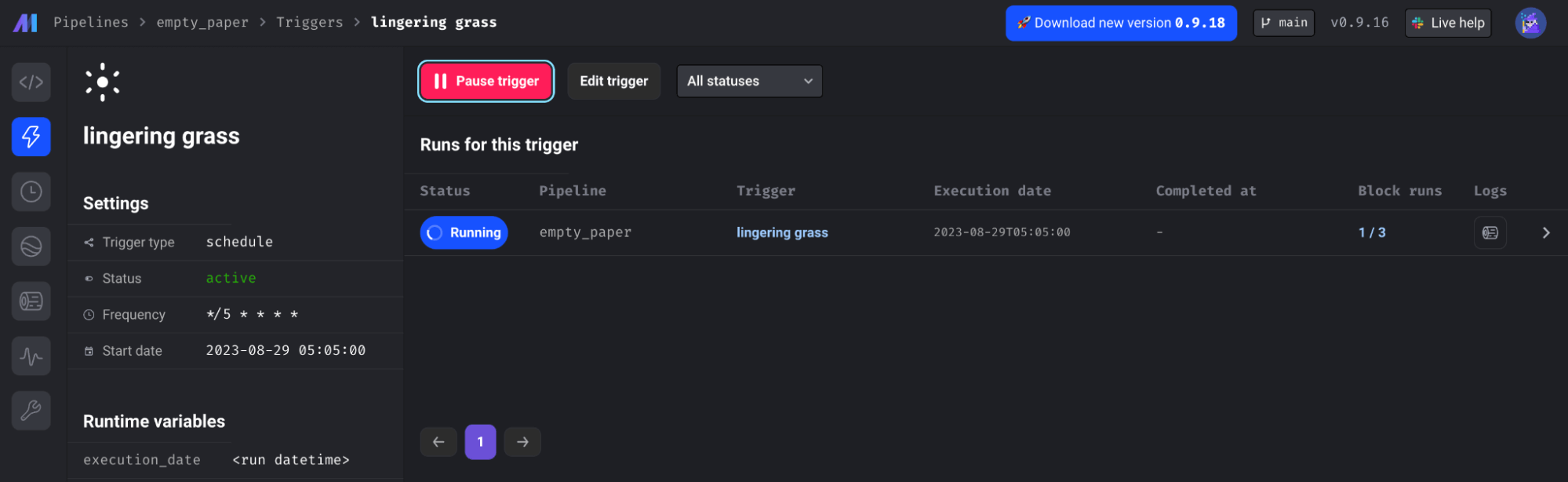
Once you’ve created the trigger you can see the status, logs, and block runs of all of your Pipeline triggers:
Final thoughts
InfluxDB is a great tool for storing all of your time series data. It’s written on top of the Apache Ecosystem and leverages technologies like DataFusion, Arrow, and Parquet to enable efficient writes, storage, and querying. It also offers interoperability with a lot of other tools so you can leverage them for your specific ETL and machine learning needs. Mage also leverages Polars (which is built on Apache Arrow) and Parquet. Together you can perform sophisticated ETL tasks on your time series data.
Get started with InfluxDB Cloud 3.0 here. If you need any help, please reach out using our community site or Slack channel. I’d love to hear about what you’re trying to achieve and what features you’d like InfluxDB to have.
