Mage for Anomaly Detection with InfluxDB and Half-Space Trees
By
Anais Dotis-Georgiou
updated November 05, 2025
Developer
Navigate to:
Any existing InfluxDB user will notice that InfluxDB underwent a transformation with the release of InfluxDB 3. InfluxDB v3 provides 45x better write throughput and has 5-25x faster queries compared to previous versions of InfluxDB (see this post for more performance benchmarks).
ETL with InfluxDB
We also deprioritized several features that existed in 2.x to focus on interoperability with existing tools. The task engine is one of the deprioritized features that existed in InfluxDB v2. While the task engine supports an extensive collection of Flux functions, it can’t compete with the vast amount of extract, transform, load (ETL) tooling that already exists, specifically for data preparation, analysis, and transformation. Among those many tools is Mage.ai. Mage is the open source replacement for Airflow. In a previous post, I described how to use Mage for a simple downsampling task. This tutorial assumes you read that post and/or have a basic understanding of how to use Mage. In this tutorial, we’ll learn how to use Mage for anomaly detection and to send alerts to a Slack webhook. Specifically, we’ll be generating machine data, generating anomalies, and detecting them with half-space trees.
Requirements
To run this tutorial you’ll need the following:
- An InfluxDB v3 Cloud account.
- A database or bucket (that you’re querying data from and writing data to).
- An authentication token that allows you to read and write to that database.
- A Docker installation to run InfluxDB in a container.
- An
.envfile with the following information:
bash
export INFLUX_HOST=
export INFLUX_TOKEN=
export INFLUX_ORG=
export INFLUX_DATABASE=
export MAGE_SLACK_WEBHOOK_URL=https://hooks.slack.com/services/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
export MAGE_PROJECT_NAME=influx-magic
export MAGE_ENV=devYou can follow this quickstart guide to learn more about how to use Mage. To replicate the example in this tutorial, clone this repo, change directories into it, and run the following commands:
- Source the
envfile:bash source .env - Build the images:
bash docker compose build - Start them:
bash docker compose up -d magic
Note: This tutorial uses the InfluxData Slack webhook #notifications-testing channel. Please join to send and receive notifications there or replace the env file with the Slack webhook of your choice.
The dataset
For this example, we’ll be generating machine data. Specifically, load, vibration, power, and temperature data for three machines (machine1, machine2, and machine3). To create anomalies, navigate to localhost:5005 and click on a machine to toggle the anomaly creation. The code that generates the data comes from this project, which showcases how to build a simple task engine using Arrow, Docker, and an analytics library called Anomaly Detection Tool Kit (ADTK). It uses Mosquitto and Telegraf to write MQTT data to InfluxDB Cloud v3.
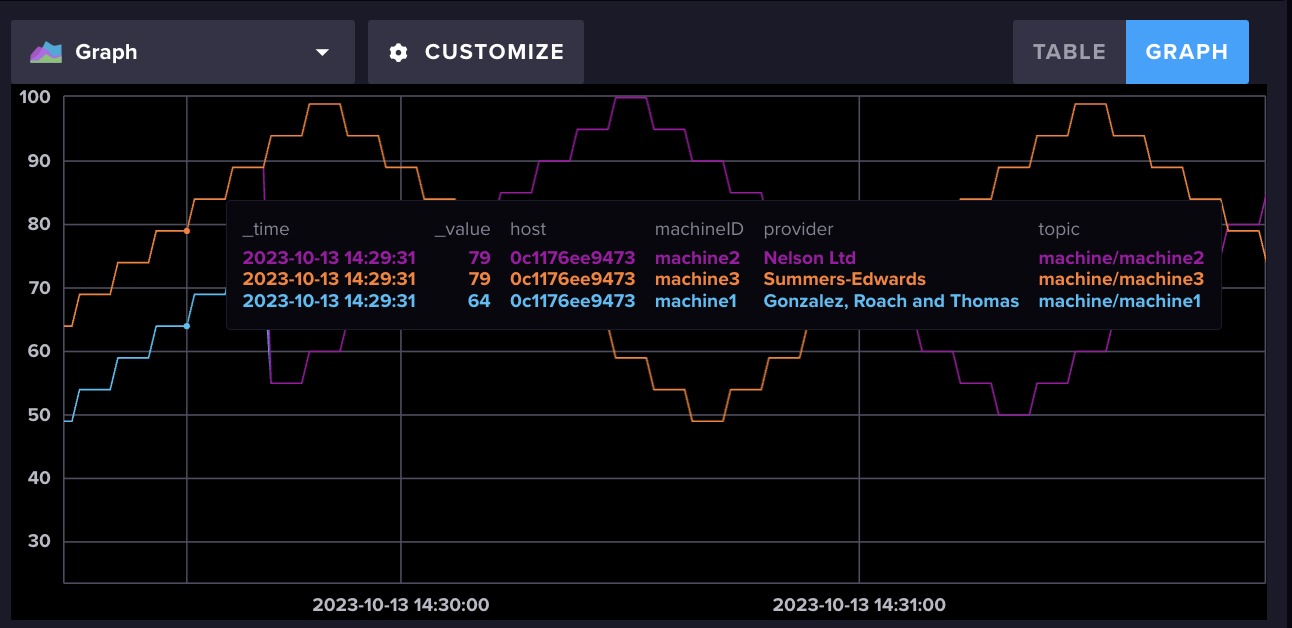 An example of what the normal machine data looks like from the Data Explorer in the InfluxDB v3 Cloud UI.
An example of what the normal machine data looks like from the Data Explorer in the InfluxDB v3 Cloud UI.
The Mage pipeline
The pipeline contains four blocks:
- Load_influx_data:
- Uses the InfluxDB v3 Python Client to query machine data and return a Pandas DataFrame.
- Transform_data:
- Creates a new column
unique_idin the DataFrame. For each row in the DataFrame, it constructs a unique ID by slugifying the provider and then appending the machineID after a hyphen. - Changes the timestamp datetime format.
- Creates a new column
- Detect_anomalies:
- Initializes a new DataFrame.
- Loops through unique IDs: For each unique ID (uid) present in the input DataFrame’s
unique_idcolumn, the function proceeds with anomaly detection. - Model creation: This model employs the HalfSpaceTrees method, which is an online anomaly detection method.
- Prepare data.
- Iterate through rows and detect anomalies.
- Combine results.
- Return results.
- Check_anomalies:
- Iterate through unique IDs.
- Filter data by unique ID.
- Check for anomalies.
- Prepare data for plotting.
- Plot data.
Model selection: half-space trees
This example uses half-space trees to detect anomalies. A half-space tree (HST) is a machine learning algorithm used for anomaly detection in high-dimensional data. It is particularly useful when dealing with data that expects anomalies to occupy specific regions or subspaces within the high-dimensional space. HSTs are a type of isolation forest-based method, and they work by partitioning the feature space into regions and isolating anomalies into smaller partitions.
Here’s how a half-space tree works to detect anomalies:
- Data is partitioned with a hyperplane in the feature space. Hyperplanes are randomly generated.
- Additional planes are added to recursively split the dataset and partition it until the number of points in a partition reaches a minimum threshold. Each additional plane creates a node in the tree.
- The point’s depth in the tree defines anomalies. Or whether they exist in smaller partitions.
Final thoughts
For this tutorial, we import all the clients and models each time we run the pipeline. However, if you’re looking to load heavy models you don’t want to do that each time you run the pipeline. I encourage you to take advantage of conditional blocks. Conditional blocks or “Add-on Block” are blocks associated with another block. The pipeline evaluates the condition before executing the parent block, which determines if the parent block gets executed. You can use them to instantiate part of a transformation block (where you’d perform your anomaly detection) but not run it each time.
InfluxDB stands out as an excellent solution for efficiently managing your time series data. It is built on top of the Apache Ecosystem and harnesses technologies such as DataFusion, Arrow, and Parquet to optimize data writes, storage, and queries. Moreover, it boasts compatibility with various other tools, allowing you to harness them for your specific ETL and machine learning requirements. Additionally, Mage takes advantage of Polars, which is based on Apache Arrow, and Parquet. By combining these technologies, you can execute advanced ETL operations on your time series data.
Get started with InfluxDB Cloud 3 here. If you need any help, please reach out using our community site or Slack channel. I’d love to hear about what you’re trying to achieve and what features you’d like InfluxDB to have.
