Table of Contents
Now that we’ve launched Flux, a combination query and scripting language, you’re probably eager to start playing around with it in your apps. We’re in the process of building libraries for a number of languages, but in the meantime, you can start making Flux queries using a simple raw HTTP request. In this post, we’ll walk through using the sandbox to get the stack up and running and then we’ll query our database using Flux in a Rails app. In a follow-up post, we’ll add GraphQL to our Rails app to enable us to allow the client to have control over the information it wants to retrieve from our Flux query.
First, clone the sandbox repo. Next, install Docker on your machine if you don’t already have it. The fastest way to do this is running homebrew cask install docker using Homebrew. Then you can start Docker using spotlight. Once you’ve got docker running, you can cd to the file path of the cloned down repo and run ./sandbox to see all of the commands available to you in the sandbox.
Running ./sandbox up will get you the latest stable versions of software loaded up within the sandbox and will open two tabs running localhost in your browser. One of the tabs includes tutorials and documentation for the sandbox, and the other tab is where most of the fun is happening in Chronograf, which is InfluxData’s data visualization and querying layer. One of the best parts of using the sandbox is that all four parts of the stack (InfluxDB, Chronograf, Telegraf, and Kapacitor) are automatically wired up to communicate with each other.
You can click around in Chronograf to see what’s already working right out of the box, but you’re here to learn how to query an InfluxDB database using Flux in a Rails app, so let’s get to it!
We can use the InfluxDB CLI to create the database we intend to query. The sandbox makes this easy by allowing us to run ./sandbox influxdb. Once you’re in the CLI, you can create your database by running CREATE <database name>.
We can also use Chronograf to create the database we intend to query. In the left-hand Navigation panel, select the “Admin” icon and then “InfluxDB.”
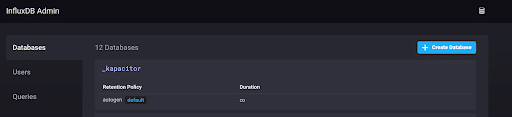
Now you should see the available databases within the InfluxDB sandbox instance. Click the “Create Database” button to create your database.
I recommend you follow the steps in the Getting Started docs to seed some data into it using line protocol (you can also use the InfluxDB API to write multiple points to your database). I followed the docs and created the “mydb” database and seeded it with several cpu load values.
You can now navigate to Chronograf’s Explore tab and actually see the database you created, along with the values you inserted into it. You also have the ability to start querying your database using Flux by selecting the Flux option (as opposed to InfluxQL which is the default).
Note that Flux is enabled by default in the sandbox, so you don’t have to alter the influxdb.conf file to enable it.
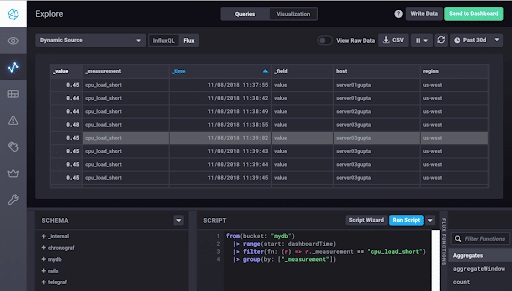
In the screenshot below, I used Flux to query for all of the points in my “cpu_load_short” measurement. In my case, the “cpu_load_short” measurement has two tags, “host” and “region,” and one field, “value.” I only had 31 points in this measurement, so it’s not a big deal, but as a general rule you probably won’t be running a SELECT * in InfluxQL or a |> group(by: ["_measurement"]) in Flux. I added the “group” function to my Flux query so all my entries will visually appear in the same table view in Chronograf, but without the “group” function, you will still get back all of your points and can see them when you toggle “View Raw Data”. I’m using it here merely to illustrate a simple Flux query on a small dataset.
Now for the fun part. Let’s run this same Flux query in a Rails app! The Flux docs give us a good clue of where to start, given that we’re just going to be making a raw HTTP request (until the client libraries are ready, at least).
Per the docs we can simply query InfluxDB’s query endpoint. We will make a POST request to the /api/v2/query endpoint. Our request will set the accept header to application/csv and the content-type header to application/vnd.flux. The response we receive will be in annotated CSV format. The docs give us a curl example that we can paste into curl-to-ruby to convert to Ruby’s net/http. Let’s use the example in the Flux docs to see how this will work:
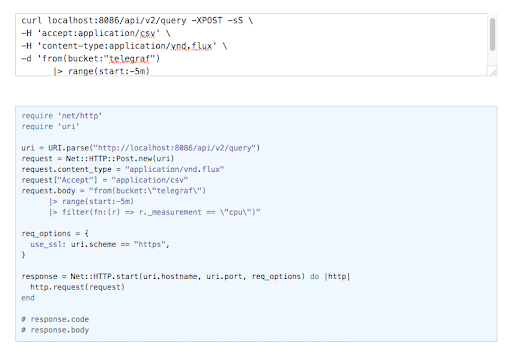
It really is that simple. So to make my query, I need only add the net/http and uri gems to my Rails app and replace the request.body above with my Flux query, properly formatted to account for the multiple strings within a string.
I encapsulated the HTTP request in a method that looks like this, based on the format of the above curl-to-ruby conversion. You can place something like this wherever in your app seems most suitable. Because I’m also building GraphQL into my app, I placed my code in the same file as my query types, but it may make sense for me to refactor this out into a helper later:
def all_cpu_loads
uri = URI.parse("http://localhost:8086/api/v2/query")
request = Net::HTTP::Post.new(uri)
request.content_type = "application/vnd.flux"
request["Accept"] = "application/csv"
request.body = "from(bucket:\"mydb/autogen\")
|> range(start:-30d)
|> filter(fn: (r) => r._measurement == \"cpu_load_short\")
|> group(by: [\"_measurement\"])"
req_options = {
use_ssl: uri.scheme == "https",
}
response = Net::HTTP.start(uri.hostname, uri.port, req_options) do |http|
http.request(request)
end
endSee the body of my request? I literally cut and pasted it from the query I generated above in Chronograf and simply fixed the string format and added an actual time range (since my app obviously doesn’t know about the Chronograf variable dashboardTime).
If we look at the response.body of that request, it’s pretty messy in its annotated CSV format. We can clean that up with a PORO (plain old Ruby object) and a simple parsing method. In my case, I know that each point (each “load,” so to speak) in my “cpu_load_short” measurement has a timestamp, a value, a field, a measurement (“cpu_load_short” for each point), a host, and a region. I want to be able to access each of those attributes in a neat package, so I’ve turned each point into a hash and placed it into a new “Load” object:
def formatted_response(response)
column_names = response.body.split(",0,")[0].split("\r\n")[3]
column_names.slice!(",result,table,_start,_stop,")
arrayed_column_names = column_names.split(",")
entries = response.body.split(",0,").drop(1)
formatted_entries = entries.map do |entry|
entry.gsub(/\r\n?/, "").split(",").drop(2)
end
hashed = formatted_entries.map do |load|
arrayed_column_names.zip(load).to_h
end
hashed.map do |hash|
Load.new(hash)
end
endThis leaves me with a nice array of Load objects that will come in handy when I need to implement GraphQL later. For reference, my Load looks like this:
class Load
attr_reader :time, :value, :field, :measurement, :host, :region
def initialize(load)
@time = load["_time"]
@value = load["_value"]
@field = load["_field"]
@measurement = load["_measurement"]
@host = load["host"]
@region = load["region"]
end
endAnd that’s it! Until our client libraries are ready, this is how you can implement any number of Flux queries in a Rails app and render usable objects from the results of your query. When the libraries are published, we’ll create another post showing you how to replace the raw HTTP request with library functions. And in a follow-up post, we’ll be showing you how to use GraphQL to allow a client to query for the exact information it wants from the results of your Flux queries. Happy Fluxing!
