Table of Contents
Introduction
Disaster Recovery and multi-datacenter replication of InfluxDB and Kapacitor are two frequently asked-about topics. In this post, I cover some of the suggested patterns for accomplishing this. Additionally, I will discuss the pros and cons of each approach and how they can be combined.
In general, there are two patterns that can be used for multi-datacenter replication of data into InfluxDB. The first is to replicate data upon ingest into InfluxDB to the second datacenter cluster. The second pattern is to replicate data from one cluster to another cluster on the backend.
Replication on Ingest
The first set of patterns to discuss is replication of data upon ingest to InfluxDB. This is probably the easiest to setup and the most useful for all new data that is coming into our cluster form external sources. Most of these patterns rely in some form on Telegraf.
Telegraf is the Swiss Army Knife of the TICK stack and can be used as an agent, a data aggregator or to help setup data ingest pipelines. Telegraf uses input and output plugins. There are about 100+ plugins as of the writing of this post. For a full discussion of Telegraf please refer to the Telegraf docs.
In most cases, we recommend the use of Telegraf in almost all deployments of Influx. At the very least Telegraf can be used to batch all write requests to the database; which is something you should always be sure to do.
Telegraf
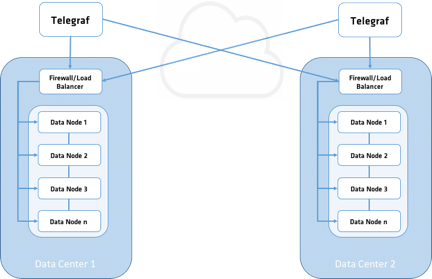
Figure 1. Telegraf Replication
The first pattern to discuss is using Telegraf by itself to replicate all data upon ingest to both clusters. To set this up, we specify the URL of both clusters in the Telegraf config file. We are going to make use of the InfluxDB Telegraf output plugin. In the outputs.influxdb section, we would set the following:
## Cluster 1
[[outputs.influxdb]]
urls = ["http://cluster1:8086"] # URL of the cluster load balancer
database = "telegraf" # Name of the DB you want to write to
retention_policy = "myRetentionPolicy"
## Write consistency (clusters only), can be: "any", "one", "quorum", "all"
write_consistency = "any"
timeout = "5s"
content_encoding = "gzip"
## Cluster 2
[[outputs.influxdb]]
urls = ["http://cluster2:8086"] # URL of the cluster load balancer
database = "telegraf" # Name of the DB you want to write to
retention_policy = "myRetentionPolicy"
## Write consistency (clusters only), can be: "any", "one", "quorum", "all"
write_consistency = "any"
timeout = "5s"
content_encoding = "gzip"This config specifies that we want to write to two separate InfluxDB clusters. One thing to note is that the URL you specify should either be the URL of a load balancer in front of the cluster or a list of the URLS of each datanode in the cluster. In this case, our config would look like this:
## Cluster 1
[[outputs.influxdb]]
urls = ["http://Cluster1DataNode1:8086",
"http://Cluster1DataNode2:8086"] # URLs of the cluster data Nodes
database = "telegraf" # Name of the DB you want to write to
retention_policy = "myRetentionPolicy"
## Write consistency (clusters only), can be: "any", "one", "quorum", "all"
write_consistency = "any"
timeout = "5s"
content_encoding = "gzip"
## Cluster 2
[[outputs.influxdb]]
urls = ["http://Cluster2DataNode1:8086",
"http://Cluster2DataNode2:8086"] # URLs of the cluster data Nodes
database = "telegraf" # Name of the DB you want to write to
retention_policy = "myRetentionPolicy"
## Write consistency (clusters only), can be: "any", "one", "quorum", "all"
write_consistency = "any"
timeout = "5s"
content_encoding = "gzip"With a list of DataNode URLs, Telegraf will write each batch to one of the URLs in the list NOT to all of them. The DB will handle replicating each batch to the requisite datanodes.
## Cluster 1
[agent]
metric_buffer_limit = 123456789 # Buffer size in bytesThis pattern is the easiest to set up. In the case of a network partition between Telegraf and the clusters, Telegraf will attempt to rewrite the failed writes. Additionally, it will store data to be written in an in-memory buffer. The size of this buffer can be configured in Telegraf.
When setting this value, you want to make sure that the buffer is big enough to hold data for a typical outage. A good rule of thumb is to set the buffer to hold an hour worth of data in case of failure. Obviously if you are writing a lot of data, this may not be feasible so set it accordingly. This buffer is not a durable write queue; if Telegraf fails or is shutdown, the buffer is gone since it is in memory. So, what do we do if we need a durable write queue?
Kafka and Telegraf
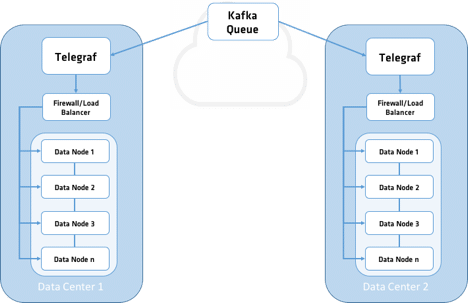
Figure 2. Telegraf Replication with Kafka
In this pattern, I have Kafka in front of our Telegraf Instances. Kafka will provide a durable write queue for all our data as it comes into the cluster. Additionally, this will add some flexibility on what we can do with all our data coming in. For instance, we might also want to send all our data to long term storage in something like S3 or send it to other analytical platforms for other types of analysis. It is assumed you will already have Kafka installed. In this pattern, our Telegraf config will look like the following:
# Read metrics from Kafka topic(s)
[[inputs.kafka_consumer]]
## topic(s) to consume
topics = ["telegraf"]
brokers = ["kafkaBrokerHost:9092"]
## the name of the consumer group
consumer_group = "telegraf_metrics_consumers"
## Offset (must be either "oldest" or "newest")
offset = "oldest"
## Data format to consume.
data_format = "influx"
## Maximum length of a message to consume, in bytes (default 0/unlimited);
## larger messages are dropped
max_message_len = 65536
## Cluster 1
[[outputs.influxdb]]
urls = ["http://clusterLB:8086"] # URL of the cluster load balancer
database = "telegraf" # Name of the DB you want to write to
retention_policy = "myRetentionPolicy"
## Write consistency (clusters only), can be: "any", "one", "quorum", "all"
write_consistency = "any"
timeout = "5s"
content_encoding = "gzip"The above example shows that we are using the Kafka Consumer Input Plugin. The topic should be whatever the correct Kafka topic is for our data. The brokers list can be one or more kafka brokers. On each call to Kafka, Telegraf will send the request to only one of the brokers. The use of a consumer group is optional, but if you have a large volume of data to pull from Kafka, you can setup multiple Telegraf instances each pulling form the same consumer group. This will allow you to pull more data and not have duplicate data form Kafka as the consumer group will keep track of the topic offsets for each consumer client.
Replication After Ingest
The second set of patterns to discuss are those where replication of data occurs after we have ingested data. There are two general buckets that these patterns can fall into. The first bucket is what I call a ‘pass-through’ where we are really just making a copy of the data we have ingested and sending it to another instance or cluster of InfluxDB. The second bucket is for derived data or data that is the output of something like a Kapacitor job, a Continuous Query, or the result set of an InfluxQL query.
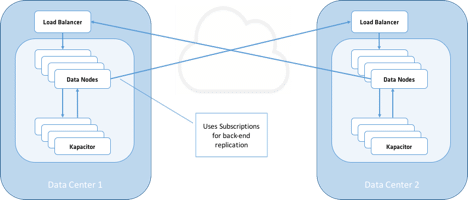
Figure 3. Replication with Subscriptions
Subscriptions were originally built for sending data to Kapacitor for stream-based TICK scripts. But here’s a little-known fact about subscriptions: They can send data anywhere you want over HTTP or UDP. This makes them really handy. When you set a subscription in InfluxDB, all it does is forward all input data that matches the database.retentionpolicy you specified.
One important thing to note is that the subscriptions on each cluster should not have the same combination of database name and retention policy. This will set up an infinite loop that will eventually tear a hole in the space time continuum; or at least crash both your clusters.
The destination for your subscription can be one or more entries. Additionally, you can specify that the subscription send it to ‘ANY’ or ‘ALL’ of those destinations. What this means is that in addition to cross-cluster replication you could also have it send data to another system for other types of analysis or to long-term storage of raw data.
# On Cluster 1
CREATE SUBSCRIPTION 'mySubscription' ON "myDB"."myRetentionPolicy" DESTINATIONS ALL 'http://cluster2LoadBalancer:port'
# On Cluster 2
CREATE SUBSCRIPTION 'mySubscription' ON "myDB"."myOtherRetentionPolicy" DESTINATIONS ALL 'http://cluster1LoadBalancer:port'Kapacitor
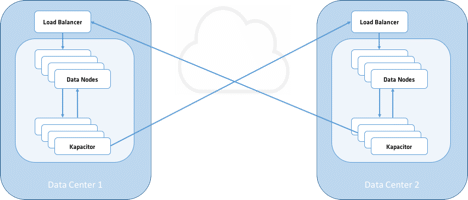
Figure 4: Replication with Kapacitor
Another take on backend replication that is very similar to subscriptions is to use Kapacitor. This pattern would be more applicable for data that is the output of a TICK script where we are either creating new data, decorating or transforming existing data. For example, this is the pattern to use for aggregations or roll-ups of data from one cluster to another. Let’s say I had the following TICK script that was performing a batch rollup of data to a 5 minute resolution:
var data = batch
|query('SELECT median(usage_idle) as usage_idle FROM "telegraf"."autogen"."cpu"')
.period(5m)
.every(5m)
.groupBy(*)We assign this to the variable data in our script. Once that is set, we branch the output to both clusters with the following:
data
|influxDBOut()
.cluster('localCluster')
.database('telegraf')
.retentionPolicy('rollup_5m')
.measurement('median_cpu_idle')
.precision('s')
data
|influxDBOut()
.cluster('remoteCluster')
.database('telegraf')
.retentionPolicy('rollup_5m')
.measurement('median_cpu_idle')
.precision('s')Notice the cluster name? That is not the URL of the cluster; rather it is a named variable from our kapacitor.conf file. More details on the kapacitor.conf file can be found here.
# Multiple InfluxDB configurations can be defined.
# Exactly one must be marked as the default.
# Each one will be given a name and can be referenced
# in batch queries and InfluxDBOut nodes.
[[influxdb]]
# Connect to an InfluxDB cluster
# Kapacitor can subscribe, query and write to this cluster.
# Using InfluxDB is not required and can be disabled.
enabled = true
default = true
name = "localcluster"
urls = ["http://cluster1LoadBalancer:8086"]
username = ""
password = ""
timeout = 0
[[influxdb]]
# Connect to an InfluxDB cluster
# Kapacitor can subscribe, query and write to this cluster.
# Using InfluxDB is not required and can be disabled.
enabled = true
default = true
name = "remoteCluster"
urls = ["http://cluster2LoadBalancer:8086"]
username = ""
password = ""
timeout = 0Backup and Restore
The last pattern to discuss is the good old backup and restore function. It should be thought of as sort of a “sneaker-net” option as it does not operate in near real time. As you may have guessed, this uses the backup and restore commands of InfluxDB Enterprise. Currently InfluxDB Enterprise supports backup of all the data in your cluster, a single database and retention policy or a single shard.
The backup command creates a full copy of both the data and the metastore creating a sort of snapshot of when the backup was taken. There are two types of backups that can be taken: a full backup or an incremental backup. When using this pattern, you should probably automate with a cron job that calls a script, every hour or day, that could perform the backups. That script might look something like this:
#!/bin/bash
BKUPDIR=[path to backup dir]
BKUPFILE= Backup_$( date +"%Y%m%d%H%M").tar.gz
influx-ctl -bind [metahost]:8091 backup –incremental -db [db-name] $BKUPDIR
tar –cvzf $BACKUPDIR ./$BKUPFILE
scp –i credentialFIle $BKUPFILE root@cluster2DataNode:path/to/save/fileThe first time you use the backup command you should probably do a full backup. However, the –incremental flag is the default, but if there is no existing incremental backups, the system will first do a full backup first.
On the destination cluster, you might want to run a script in the background that will watch your drop folder and perform the restore when the backup file is sent over. That script might look something like this:
#!/bin/bash
MONITORDIR="/path/to/the/dir/to/monitor/"
inotifywait -m -r -e create --format '%w%f' "${MONITORDIR}" | while read NEWFILE
do
influx-ctl restore ${NEWFILE}
doneThe Nuclear Option
Although this is not a proper cluster-to-cluster replication pattern, I feel it is still worth some discussion. What is the “nuclear option”? This is the last resort option if the whole world, or rather your clusters and all your data, have gone really bad. I should admit that I am a fan of keeping raw data for as long as possible. Doing this gives us more flexibility in our systems and how we might want to analyze things at a future point in time. Implementing this should be done with one of the replication on ingest patterns, where we would tap off our input stream and store all our raw data in long-term storage like S3 or Glacier. Doing this gives us the ability to rebuild our system from source.
Hence the nuclear option. If we have all our source data and need to rebuild our cluster from scratch, including all derivative data, we can now do this by replaying our source data. Obviously, there are still some considerations around exactly how much source data you have and the time needed to replay it, but hopefully you see the benefits.
Conclusion
In this post, I have discussed several patterns for replicating data between two different clusters of InfluxDB Enterprise. These are only the most basic patterns, and I think there are probably at least 20 more that exist. I wanted to present a few patterns that you could use as a starting point. The point of this post was not to present an exhaustive list or to say that this method or that method is the best one to use. In reality, there is no single best method or pattern. The best pattern for you is the one that meets your business objectives and fits within your organization’s infrastructure, processes and practices. Now go forth and replicate.
