Optimizing InfluxDB Performance for High Velocity Data
By
Sam Dillard
updated December 14, 2025
Product
Use Cases
Developer
Navigate to:
Whether you’re tracking neuron behavior in the brain at nanosecond resolution, monitoring large and ever-changing infrastructure that supports business-critical applications, tracking real-time behavior of autonomous vehicles, or monitoring high frequency changes in stock prices across stocks and their exchanges, the business need for data at a high resolution becomes paramount. To meet this need, a high velocity datastore and query engine are required.
InfluxDB was designed to be both. The objective of this post will be to help understand how to get the most out of it.
A few notes to preface this:
- A prerequisite to benefiting from this article is having a basic understanding of the InfluxDB data model (database, retention policies, measurements, tags, fields) – reference, tutorial, and primer below.
- For purposes of structure, the optimizations presented below will be written in order of a typical time series data pipeline. By that, I mean the first optimizations will be all the way upstream (data sources/clients) and the last will be about using the data once it's written (queries).
- Lastly, for the scope of this post, I am assuming the use of the TSI index.
Optimizing writes
First, you’ll want to establish how you’re instrumenting the assets you’re monitoring. InfluxData is the creator and maintainer of a very popular open source collection agent, Telegraf. However, many users still make use of other methods of instrumentation like client libraries.
If possible, use Telegraf. Not only does Telegraf offer plugin-driven integrations with well over 200 services directly out of the box, it is designed by the same engineering team as InfluxDB, making it a framework for InfluxDB best practices.
Telegraf handles the following for you:
- Ordering tags and timestamps – For purposes of faster file block scanning, InfluxDB orders keys lexicographically and then timestamps in descending order. In the interest of letting InfluxDB not worry about that, order tags lexicographically upstream and write your batches in ascending time order (oldest first).
- Retries – If the write destination (InfluxDB, load balancer, message queue, etc.) is backed up or down, clients (in this case, Telegraf) can fail to write. It is important that – assuming you require per-write data integrity – your client can retry failed writes until they succeed.
- Modifiable batch sizes
- Jittering
- Helps to spread the workload and, therefore, resource utilization on your data nodes.
- If you have many writers writing directly to InfluxDB, this can reduce your chances of hitting open connection limits.
- Pre-processing
- Aggregations (mean, min, max, count, etc.)
- Conversions – i.e., Fields to Tags; Tags to Fields (this is important when you need to make this kind of change to your schema moving forward (see Schema section).
Data model, schema and Line Protocol
Given this post’s structure, you might be thinking that the schema section should be first. InfluxDB, however, has a self-defining schema based on the writes it receives. You don’t need to define a schema ahead of time. This makes it very flexible but can also lead to “rogue” users or tags causing performance problems down the road. The way InfluxDB organizes data is defined by how records (or “lines”) of Line Protocol are written.
Brief primer on Line Protocol
Data model:
- Database – Top-level data structure; can be multiple in a single Influx instance
- Retention Policy – How long the data contained in this policy will stick around before eviction.
- Measurement – A logical grouping of like metrics. Example: cpu usage can be measured in many ways. The Telegraf plugin for measuring cpu writes metrics like
usage_user,usage_system,usage_idle, etc. all into one Measurement calledcpu. Measurements can be thought of as functionally similar to tables in relational databases. - Tag set (metadata)
- Combination of one or more key-value pairs that act as metadata for the Measurement and associated Fields (actual metrics) you are writing.
- Tag keys are used to describe an "asset" being monitored, i.e., hostname, ip, region, ticker, exchange.
- Tags are for
GROUP'ing; data by which you want to distinguish your assets in a single query.
- Field set (metrics)
- Combination of one or more key-value pairs that describe the actual measure-ables of your assets, i.e.,
cpu_usage_user,memory_free,disk_available,water_pressure,turbine_rpm,open_price, etc.
- Combination of one or more key-value pairs that describe the actual measure-ables of your assets, i.e.,
Formatting Line Protocol
In many data formats – including those of other TSDBs – records of data are structured so that there is only one value (or scalar) written along with its descriptor metadata (key that defines the “asset” that the value is being sampled from). This is required because the metric key information is encoded in the metadata. Line protocol avoids this problem and allows you to write multiple (many) values per record – in this case, per “Line”. Let’s take a look at some comparisons:
Graphite format:
host.metadata1.metadata2.<measureable>.<specific field> value=<value>Or, more specifically:
Metric 1: 0001.us-west-1.a.cpu.usage_system value=45.0
Metric 2: 0001.us-west-2.a.cpu.usage_user value=35.0
In the above example, everything before value is the key describing where the value comes from and what it actually is. This means, in order to know what each value represents, you must write most of the metadata a second time to simply write another cpu metric about the same asset.
Prometheus format:
measureable_metric,metadata1,metadata2, gauge=<value>Or, more specifically:
cpu_usage_system,region=us-west-1,host=0001,az=a gauge=1.5
cpu_usage_user,region=us-west-1,host=0001,az=a gauge=4.5While this format separates the pieces of metadata (helps in InfluxDB – discussed later), it suffers from the same problem as the Graphite format.
Influx Line Protocol format:
measureable,metadata1,metadata2 <specific_field>=<value>In Influx terminology:
measurement,tag,tag field,field,field,field,fieldMore specifically:
cpu,region=us-west-1,host=0001,az=a usage_user=35.0,usage_system=45.0,usage_guest=0.0,usage_guest_nice=0.0,usage_nice=10.0,usage_steal=5.0Notice the punctuation; a space separates tags and fields.
A couple of advantages with this:
- Payloads over the wire get much smaller. This helps efficiency...and budget.
- Data is more explorable, as shown below.
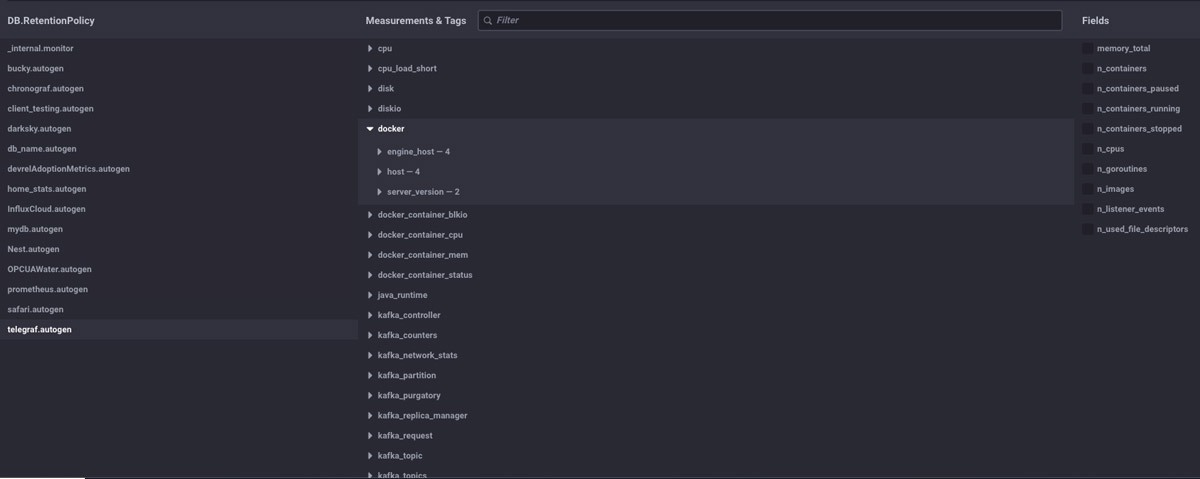 Note: Having multiple instances of Databases, Measurements, Tags, and Fields makes it easier to see your data in the Chronograf Data Explorer and often makes the meta queries that run this exploration more efficient.
Note: Having multiple instances of Databases, Measurements, Tags, and Fields makes it easier to see your data in the Chronograf Data Explorer and often makes the meta queries that run this exploration more efficient. - Writes to disk are slightly faster.
How can you get your data into this format?
- Telegraf has many different parsers to help with this.
- Telegraf also has a pivot plugin that one can combine with an upcoming aggregator plugin that will be available in v1.13.
- The client libraries mentioned earlier, designed for creating and batching series.
Optimizing reads
It’s important to understand that InfluxDB’s underlying file format (Time Structured Merge Tree, created by InfluxData) is columnar, as opposed to the row-oriented file format used by relational databases you might be more familiar with (i.e., Postgres).
- Caching repeat response data:
- Meta queries (
SHOW MEASUREMENTS,SHOW TAG KEYS,SHOW SHARDS, etc.) often return unchanging or infrequently changing data but can be somewhat expensive in certain use cases. Some customers have implemented caching layers to reduce load on Influx and reduce "hangtime" of said queries. We've seen the use of Varnish and EVCache from Netflix...but I'm sure there are others.
- Meta queries (
- A time series database is not only optimized for time series writes but also time series queries. Time-bounding, selecting specific fields, and WHERE filtering by series if possible:
- Columnar storage expects to be hit with columnar style queries; queries that
SELECT(or filter) for specific columns. This contrasts with the common [SQL](https://www.influxdata.com/glossary/sql/) query,SELECT * FROM. - Filtering
- Filtering by time is the most obvious form of filtering a query but is overlooked by a lot of users that are new to the time series database world. As I've stated before, two design assumptions TSDBs make is a) that data is high velocity and b) that the older data is, the less critical it is. Given this, there is an assumption that queries will be dealing with snippets of time and usually those snippets are more recent.
- Filtering by metric/asset/series is similarly important. Time series databases (columnar stores) aren't optimized for reading out data from every single "column" like a relational database might be. This means it's important to – if possible –
SELECTonly the fields you want data from and toWHEREfilter your Tags so that only the series keys that contain the information you want are scanned by the query engine.
- Columnar storage expects to be hit with columnar style queries; queries that
- Aggregates are much faster to compute than queries that return raw, unprocessed data.
- Batch functions require reading all data into memory before processing whereas streaming functions do not:
- Batch:
percentile(),holt_winters(),median(),mode(),spread(),stddev() - Stream:
mean(),min(),max(),first(),last(),top(),sum(),elapsed(),moving_average()
- Batch:
- Increase shard duration (comes with write performance and storage/compaction trade-offs)
- When a query is searching through storage to retrieve data, it must allocate new memory for each shard. Many shards means more memory usage.
- A cursor is created to reference each series per shard.
- If you run a query evaluating a single field for 1,000 series across 3 shards, 3,000 cursors will be generated at a minimum...which has cpu and memory implications.
- For the most part, "high query load" is defined by number of shards accessed, whether it's one query that accesses many or many queries that each access one unique shard.
- When a query is searching through storage to retrieve data, it must allocate new memory for each shard. Many shards means more memory usage.

- If you are using a UI tool like Grafana or Chronograf, you can take advantage of dashboard template variables. When appropriate, this is a good tool for enabling filtering and preventing over-fetching of data.
Shard durations:
- Longer:
- Better overall read and write performance due to active/"hot" shards (the longer a shard duration, the longer a shard will be "hot" or uncompressed and more optimal for query)
- More efficient compactions
- Fewer compactions
- Shorter:
- Less expensive compactions
- More manageable
EXPLAIN ANALYZE:
This is a tool you can use to analyze queries that you have deemed non-performant.
Running it:
EXPLAIN ANALYZE <query>Its output is explained below:
Cursor:
- A pointer that traverses shards for single series
- A cursor is created per shard per series (a query searching for 1 field in 1,000 series across 3 shards will yield at least 3,000 cursors)
Iterator:
- The primary interface between storage and query
- Iterator nodes (and nested iterators) are the workhorse of the query engine that perform operations like sorting, merging, aggregation/reduction, expression evaluation and more.
Execution time:
- Time for cursors to read data
- Time for performing transformations as query flows through each iterator and is drained by the query executor
- Query executor serializes results to JSON, CSV, or other specified.
- When analyzed, the output data is thrown away.
Planning time:
- Under "select node", represents total query planning time
- Under "create_iterator", represents planning time for a specific iterator
Steps taken in planning:
- Determine type of query (raw or one with an expression)
- Determine and separate time range and condition expression for filtering
- Determine effective time range of query and select appropriate shards based on that time frame and the indexed list of measurements (may include remote nodes in a cluster)
- For each shard and each measurement therein:
- Select all matching series keys from index, filtered by any tag predicates in
WHEREclause - Collate filtered series into sets of tags based on
GROUP BYdimensions - Enumerate each set and create: cursor and iterator per series to read TSM data and set of iterators for each group to perform required transformations
- Merge all iterators and return merged result to query executor
- Select all matching series keys from index, filtered by any tag predicates in
The # of series keys determines how quickly queries can be planned and how much memory is required.
Outside of the listed tactics for performance optimization in this guide, you can always contact us for more specific things you can do given your use case. If you’re an Enterprise customer, our Support team, Sales Engineering, and Customer Success teams are here to help. For community users, we have a community site and a community Slack.
Any platform that is designed for flexibility means there are lots of ways to improve one’s use of said platform. While this guide’s tuning knobs are numerous, not all may be relevant to each user. I hope that each reader comes away with at least a few things they can to improve their overall performance.
