Scaling Kubernetes Monitoring without Blind Spots or Operations Burden
By
Daniella Pontes
updated December 14, 2025
Product
Use Cases
Developer
Navigate to:
This article was written by Daniella Pontes and Chris Goller.
Kubernetes has seized center stage in the DevOps world when building and migrating applications to a cloud-native environment. In reality, Kubernetes is a means to an end to scale operations of containerized microservice architecture. Managing deployment, scaling, upgrading and updating of the various microservices of fragmented applications running on containers is not a trivial task, certainly already beyond manual processes. So automation is the only way to go. Kubernetes came to take the role of orchestrating containerized workloads.
InfluxDB Cloud 2.0 Kubernetes monitoring
At InfluxData, we embraced microservices and Kubernetes when building our InfluxDB Cloud 2.0. But we also know that what makes automation reliable is monitoring. Therefore, between the metrics exposed by SREs (to fulfill the need to keep resources and microservices healthy) and the metrics exposed by developers (resulting from their inclination to instrument the code to provide as much information as possible for a potential failure diagnosis), is an ever-growing number of endpoints exposed for scraping in our Kubernetes environment. The exact number of metric endpoints and the functional endpoints themselves are in a continuous state of change due to the ephemeral nature of Kubernetes atomic structure, Pods. So the first question is: how scalable is scraping metrics via these exposed endpoints in Kubernetes? The answer is: It depends on how scraping is implemented.
We know, from our own experience dealing with metrics generation from multiple teams in a large cloud deployment, that there is a turning point of a “label too far” and as a result, you get a blind spot, missing metrics. The scraper cannot cope with pulling an increasing number of the metrics exposed within the polling interval. Increasing the polling interval means reducing the frequency for obtaining metrics and that reduces the availability of critical information for troubleshooting. So lengthening the polling interval is no true solution. (For more details on our journey to master Kubernetes monitoring, please check Chris Goller’s session at InfluxDays San Francisco Oct 2019.)
We then realized that we must think beyond centralized scraping, it proved not to be scalable for large environments not even with a federated implementation. Since it presses operations to keep up optimum metrics distribution among federated servers, it burdens Ops with yet another monitoring and balancing act. In other words, it is not easily implemented and maintained.
As a principle, a good strategy for scraping shall neither increase the burden on operations nor impose a barrier to democratizing metrics to anyone who needs it. If the larger your system gets, the more complex it becomes to monitor, then fundamentally you don’t have a scalable solution.
The answer to this apparent DevOps dilemma is actually quite simple and is in the heart of Kubernetes’ containerized structure: you just need to contain (isolate) the impact of each exposed metrics. The scraper should be contained inside the pod of the service or workload, that it is going to scrape. The mechanism to implement this approach is called sidecar deployment.
In InfluxDB Cloud 2.0, we have Telegraf, a lightweight, plugin-based, metrics collection agent, deployed as a sidecar in every pod, so all the metrics exposed by the application, service or microservice are handled by that agent and will not impact the scraping of other workloads.
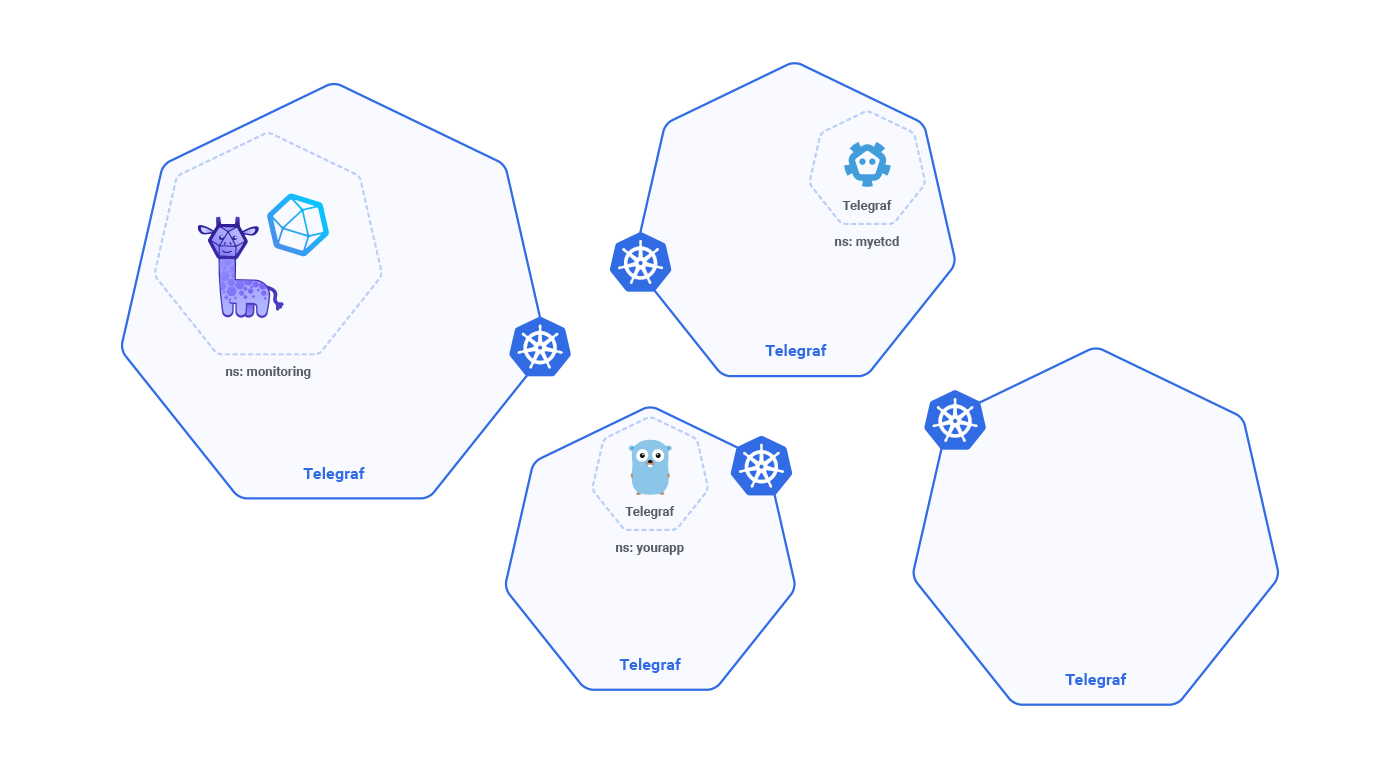
Each Telegraf agent sends its metrics to InfluxDB in the cloud or on-prem, without creating any burden on IT Operations, or a culture of pushing back on developers and data engineers on their needs for metrics.
Watching the watcher
Sidecar deployment addressed the issue of scaling scraping, but our journey to properly monitor our Kubernetes environment did not stop there. A second question still needs to be answered we need to guarantee that we don’t have blind spots, missing metrics. So we need to be able to watch the watcher.
The answer is in Telegraf one more time. It is actually a very good fit as a monitoring agent, because it takes nothing for granted. Telegraf monitors how well it is doing its job. It has an input plugin for its internal metrics, collecting data such as:
- gather_errors
- metrics_dropped
- metrics_gathered
- metrics_written
The screenshot below is from monitored measurements detecting missing metrics. The next step is just to dig into the Telegraf self-watch to find which had metrics dropped and to gather errors.

Other good reasons
Adding capabilities for self-control is also an important feature that a monitoring solution provides. Monitoring metrics is always a balance between cardinality and indexing. The more tags added for description and visualization grouping, the more series are created. This comes at a cost since having more series will take its toll on resources. Telegraf has a very useful feature to keep well-behaving “metrics” citizens behaving well by putting some guard-rails in the agent.
While in Telegraf, this can be easily configured to limit the number of tags taken as preferential ones. Changing a measurement description would not be as straightforward in the case of trying to make this change in a central Prometheus server. For instance, changing the central Prometheus server would require a restart, impacting the metrics gathering of all microservicers being monitored. On the other hand, with a Telegraf sidecar deployment, a restart of a single pod with the single service and telegraf, there would mean no interruption to anyone else.
Configuring Telegraf can be done in runtime with no need to recompile and completely under the developer’s control, freeing ops of additional overhead.
[[processors.tag_limit]]
limit = 3
## List of tags to preferentially preserve
keep = ["handler", "method", "status"]Telegraf has 200+ open-source plugins for full-stack monitoring (infrastructure, network, & application), supporting pull, push and metrics streaming, as well as client libraries (C#, Go, Java, JavaScript/Node.js, Python…) for direct instrumentation. Telegraf also monitors kubelet API for metrics exposed in /summary endpoint and Kubernetes Inventory monitors system resources state as for:
- daemonsets
- deployments
- nodes
- persistentvolumes
- persistentvolumeclaims
- pods (containers)
- Statefulsets
Key lessons learned
Scaling monitoring is not about adding more manual processes and controls. Scaling cannot be coupled with higher complexity, and surely, must embrace empowering developers with observability, predictability and prescriptive means - to ensure that monitoring is doing its job.
Of course, Kubernetes is constantly evolving, and so are we. If you have an idea, we’d love to hear about it!
