Sync Data from InfluxDB v2 to v3 With the Quix Template
By
Anais Dotis-Georgiou
Apr 08, 2024
Developer
Navigate to:
If you’re an InfluxDB v2 user looking to use InfluxDB v3, you might be wondering how you can migrate data. We are still developing migration tooling. In the meantime, you can use the Quix Template to sync data from InfluxDB v2 to InfluxDB v3.
Quix is a complete solution for building, deploying, and monitoring real-time applications and streaming data pipelines using Python abstracted over Kafka with DataFrames. Quix Streams is an open source Python stream processing library, and Quix Cloud is a fully managed platform for deploying and running Quix Streams applications in data pipelines. It’s quick to get started with the Quix-provided managed Kafka broker, or you can connect to a self-hosted or managed Kafka provider.
The framework is designed with particular consideration for processing time series data and is available in both cloud and on-prem offerings. It eliminates the headache of managing infrastructure, and its UI simplifies the building, operations, and maintenance of event streaming and ETL processes.
The Quix template’s syncing capabilities are similar to those of the Edge Data Replication tool (which still allows you to write data to InfluxDB v3). However, Quix pipelines are built on top of Kafka, so they can scale to accommodate high-throughput use cases and benefit from Kafka’s reliability and durability.
You can also extend any Quix pipeline to incorporate any additional or required ETL tasks. This template creates an InfluxDB v2 source connector that uses Flux to query your InfluxDB v2 instance and sends data to the Influxv2-data topic. Then, the InfluxDB v3 connector pulls the records from the Kafka topic and writes them to InfluxDB v3.
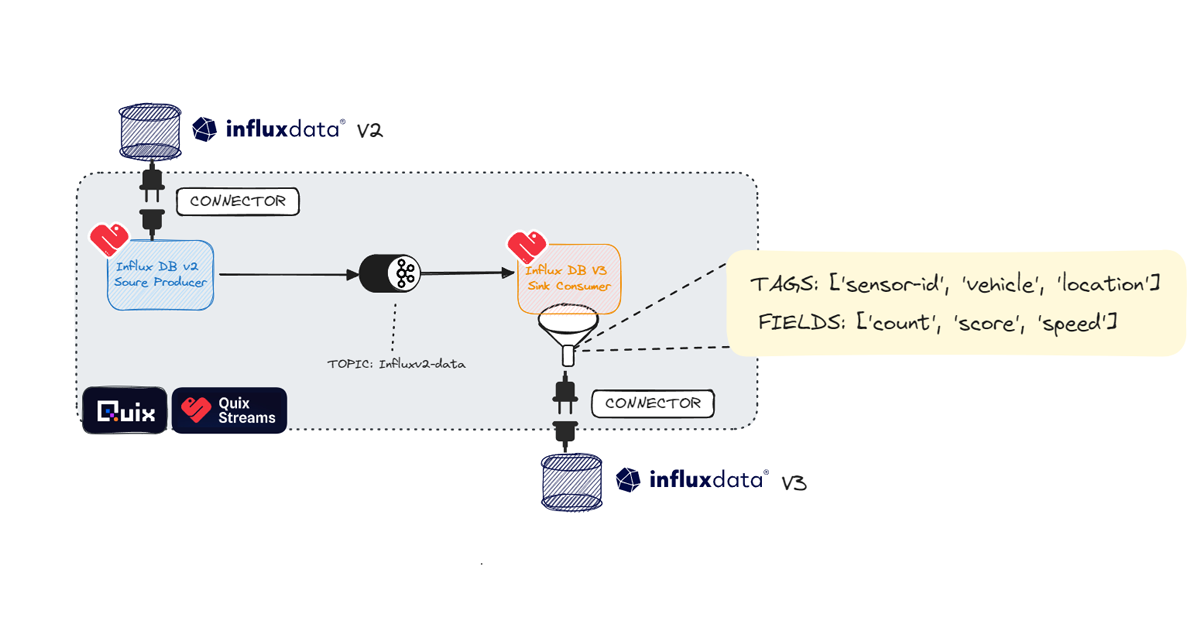
A simple architecture drawing of the InfluxDB v2 to v3 connector from Quix.
Requirements
In order to follow this blog post, you’ll need the following:
- An InfluxDB v2 instance with real-time data
- An InfluxDB v3 account—sign up here for a free cloud tier
- A Quix account—sign up here for a free 30-day trial.
Make sure to gather the following credentials from both of your v2 and v3 InfluxDB accounts:
- Buckets (both your InfluxDB v2 source and InfluxDB v3 destination bucket)
- Token
- Organization ID
- The fields and tags you want to sync from your v2 instance to your v3 instance
For this blog post, we’ll demonstrate how to write CPU data to InfluxDB v2 collected from and written to InfluxDB v2 with the Telegraf CPU input plugin.
Configure and sync
Getting started with this Quix template is incredibly straightforward. All you have to do is click the Clone this project button in the UI.
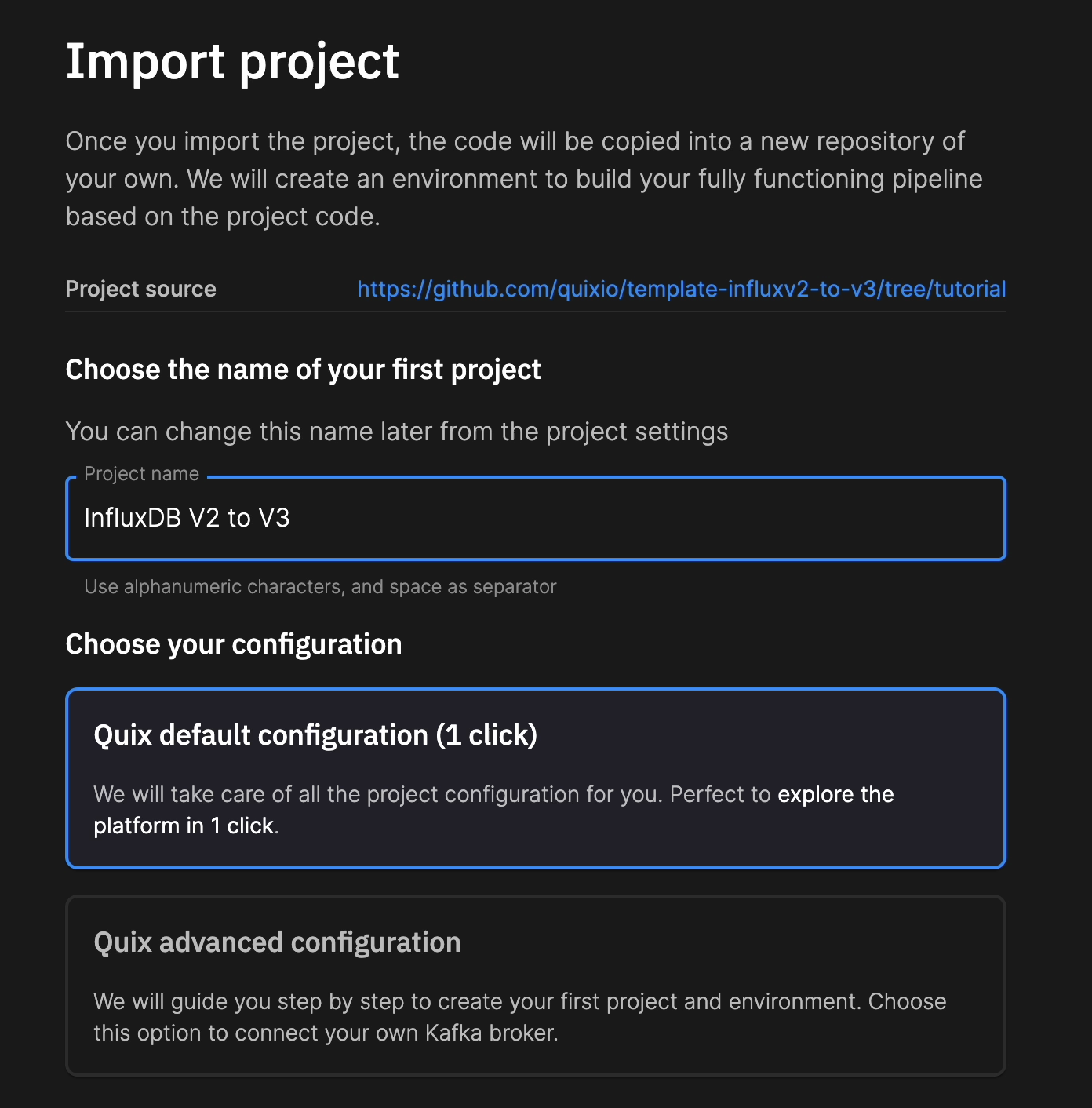
 You’ll be redirected to your Quix account. From there, import the project.
You’ll be redirected to your Quix account. From there, import the project.
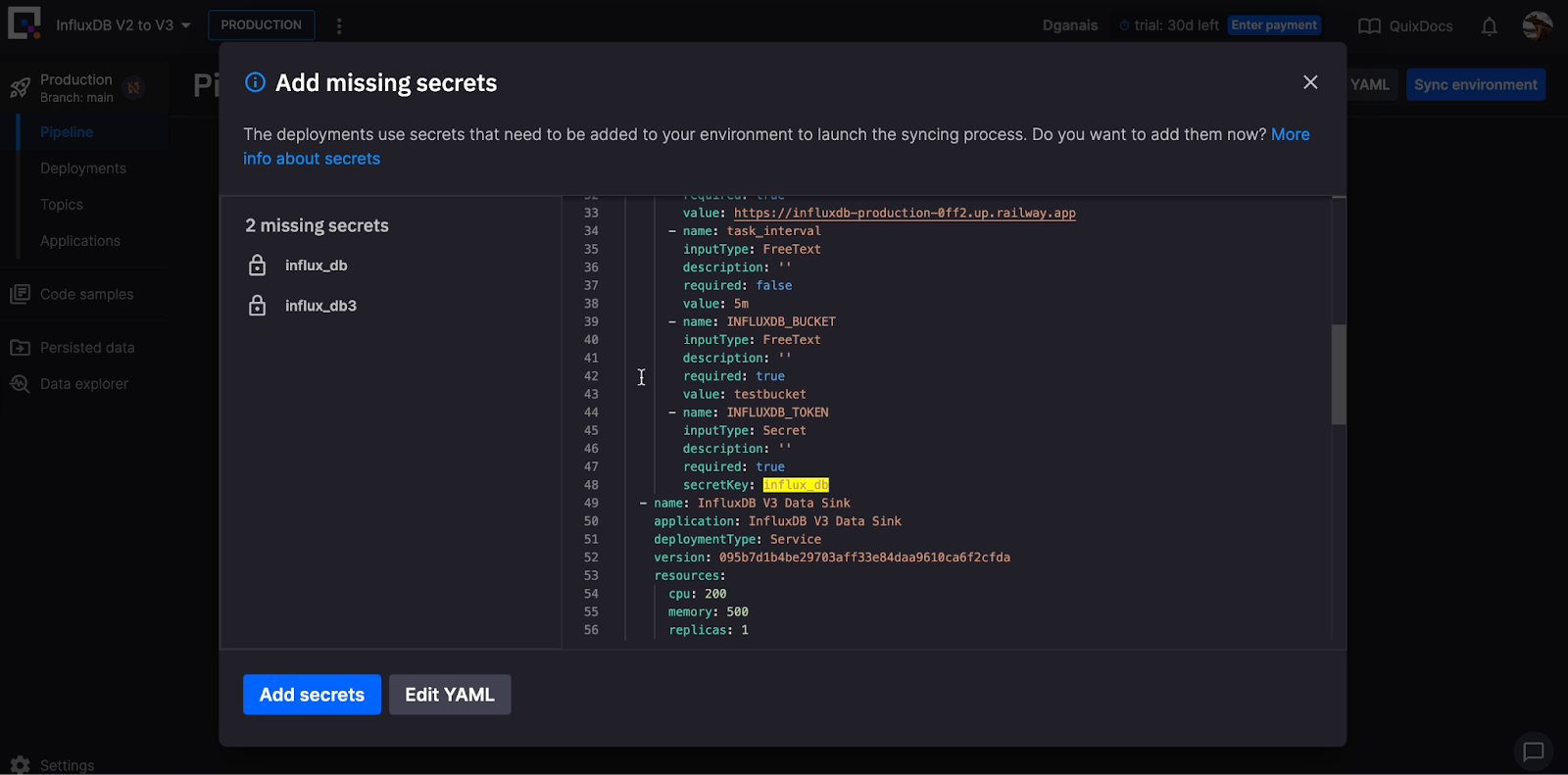
 After you’ve imported and created the project, you can sync your environment from the Pipeline page. Quix uses pipelines as code, enabling pipeline versioning with a YAML file. Click Sync environment to add your InfluxDB v2 and v3 tokens as secrets.
After you’ve imported and created the project, you can sync your environment from the Pipeline page. Quix uses pipelines as code, enabling pipeline versioning with a YAML file. Click Sync environment to add your InfluxDB v2 and v3 tokens as secrets.
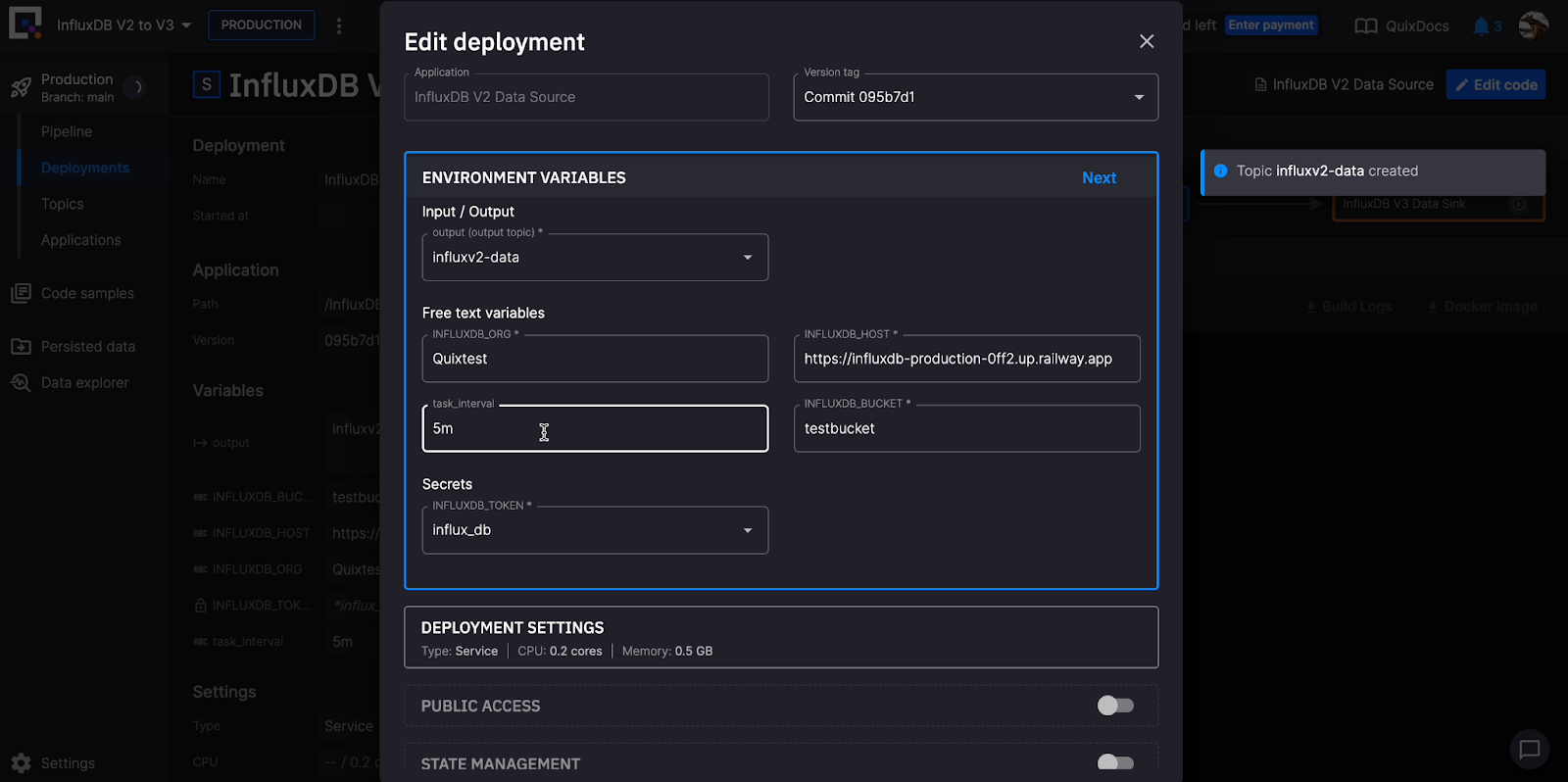
 The services in the pipeline will now start. Click on each service to edit the deployment. Add your bucket and query information and task interval in the ENVIRONMENT VARIABLES section and details about the data you want to query under the DEPLOYMENT SETTINGS.
The services in the pipeline will now start. Click on each service to edit the deployment. Add your bucket and query information and task interval in the ENVIRONMENT VARIABLES section and details about the data you want to query under the DEPLOYMENT SETTINGS.
 Click on the Logs tab to verify that your Flux query is correct so you can successfully replicate the data from your InfluxDB v2 instance to your InfluxDB v3 Cloud account.
Click on the Logs tab to verify that your Flux query is correct so you can successfully replicate the data from your InfluxDB v2 instance to your InfluxDB v3 Cloud account.

Final thoughts
I hope this tutorial helps you get started with the InfluxDB v2 to v3 sync Quix Template. Many thanks to the Quix team for continuing to make solutions that help the InfluxDB community. I also want to encourage you to take a look at some of the other InfluxDB Quix templates and projects, including:
- Event detection and alerting featuring InfluxDB and PagerDuty: In this tutorial, you learn how to create a CPU overload alerting pipeline with Quix Cloud, Quix Streams, InfluxDB, and PagerDuty.
- Predictive maintenance: This project template contains the full source code for a data pipeline and dashboard that illustrates how predictive maintenance can work in practice. Using a time series forecasting algorithm, it simulates data generated by a fleet of 3D printers and predicts which ones will fail before the print finishes.
- Quix Saving the Holidays: This project provides an example of how to use Quix and InfluxDB 3.0 to build a machine anomaly detection data pipeline. This repository contains the full data pipeline as a project but does not include the data simulator (See getting started for more details).
Get started with InfluxDB Cloud 3.0 here. If you need help, please contact our community site or Slack channel.
