Telegraf Best Practices: Config Recommendations and Performance Monitoring
By
Jay Clifford
updated December 14, 2025
Use Cases
Product
Developer
Navigate to:
Telegraf has reached the ripe old age of V1.21.2. Thanks to community feedback and contribution, there have been many features added over the years. Lately, I have seen these questions pop up:
- How can I monitor the performance of my Telegraf instance?
- What configuration parameters can I change to reduce memory consumption?
- How can I maintain a configuration file with hundreds of plugins?
- How can I improve the readability of debugging and test new configs?
If any of these questions plague your mind, have no fear this blog is here to help! Here are my golden rules for maintaining best practices when building your Telegraf solution.
Maintaining a large and complex config file
In many use cases, Telegraf is being deployed to ingest data from multiple input sources and deliver that data to either InfluxDB or other enterprise platforms (as shown in the below example).

So how do we maintain and future-proof the Telegraf config?
Divide and conquer
My first golden rule is to split your configuration into manageable chunks. How is this possible? Telegraf provides the ability to add configuration files to the telegraf.d directory. This is usually located:
- Linux: /etc/telegraf/telegraf.d/
- Windows: C:\Program Files\Telegraf\telegraf.d (You set this as part of the service install)
- Mac: /usr/local/etc/telegraf.d
Note: you can also define your own directory locations for storing Telegraf configs using the –config-directory flag. All files ending in .conf are considered a Telegraf config.
Doing this allows you to keep parts of your large configuration in multiple smaller ones. For example:
- Create three config files called: inputs, processors and outputs. Add your plugins to match the corresponding config.
- Create a config file per usage scenario. This is my personal preference when using Telegraf.
This is how I would divide up the above diagram into configuration files:
| telegraf.conf |
| Global Parameters |
| opc_ua_machines.conf | modbus_sensors.conf | system_performance.conf |
| Input: opc_ua client x2 Output: influxdb x1, cloud connector x1 | Input: modbus x1 Output:influxdb x1, cloud connector x1 | Input: internal x1, cpu x1, etc. Output: influxdb x1 |
Pros:
- This structure can be scaled to hundreds of plugins while maintaining the readability and maintainability of scenarios running under one Telegraf instance.
Cons:
- The administrator must remember that Telegraf does not distinguish between config files (they are run as one). Routing must still be considered in each configuration file (We will discuss this later in the blog post).
Naming plugins
Let’s start with the easy one which will save you hours debugging in the future: naming your plugins. My second golden rule is to provide a descriptive alias to each one of your plugins. An example would look like this:
[[inputs.file]]
alias = "file-2"
files = ["/data/sample.json"]
data_format = "json"This will provide further context when inspecting Telegraf logs, allowing you to route out the problematic plugin:
Without Alias:
2021-11-29T17:11:04Z E! [inputs.file] Error in plugin: could not find file: /data/sample.json
With Alias:
2021-11-29T17:11:04Z E! [inputs.file::file-2] Error in plugin: could not find file: /data/sample.json
Tags, tags, tags!
Before we dive into the usefulness of tags, let’s quickly run through the data structure of line protocol and why it matters to understand its structure when using Telegraf. Line protocol is made up of 4 key components:
- Measurement name: Description and namespace for the metric
- Tags: Key/Value string pairs and usually used to identify the metric
- Fields: Key/Value pairs that are typed and usually contain the metric data
- Timestamp: Date and time associated with the fields
Suppose we are ingesting this JSON message and overwrite the measurement name of the plugin to be:
[
{
"Factory" :"US_Factory",
"Machine" :"Chocolate_conveyor",
"Temperature" : 30,
"Speed" : 0.6
},
{
"Factory" :"US_Factory",
"Machine" :"hard_candy_conveyor",
"Temperature" : 40,
"Speed" : 0.4
},
{
"Factory" :"UK_Factory",
"Machine" :"Chocolate_conveyor",
"Temperature" : 28,
"Speed" : 0.5
}
]Here is the current result in line protocol:
factory_data Factory="US_Factory",Machine="Chocolate_conveyor",Temperature=30,Speed=0.6 1638975030000000000
factory_data Factory="US_Factory",Machine="hard_candy_conveyor",Temperature=40,Speed=0.4 1638975030000000000
factory_data Factory="UK_Factory",Machine="Chocolate_conveyor",Temperature=28,Speed=0.5 1638975030000000000Houston, I think we have a problem (to quote the Apollo 13 astronauts’ radio communications upon discovering a problem). Since we have not defined tags, each one of our JSON properties has become a field. In some circumstances, this might not be a problem. In this case, it’s a big one! Imagine if we wrote these metrics to InfluxDB, since each metric shares the same timestamp, we would essentially overwrite our data with the next value. This is where the importance of assigning tags early on within the Telegraf pipeline comes into play. Let’s define these now:
factory_data
Factory="US_Factory",Machine="Chocolate_conveyor" Temperature=30,Speed=0.6 1638975030000000000
Factory_data Factory="US_Factory",Machine="hard_candy_conveyor" Temperature=40,Speed=0.4 1638975030000000000
factory_data Factory="UK_Factory",Machine="Chocolate_conveyor" Temperature=28,Speed=0.5 1638975030000000000As you can see, tagging provides a searchable and segregatable definition to our metrics. It is an extremely important data feature used within InfluxDB. Aside from this, Telegraf can make use of tags as part of a number of advanced features like routing, which we will discuss next.
Routing plugins
My next golden rule is to always be in control of where your data is going. For simple Telegraf configs, this really isn’t a problem as usually you are collecting from one or more input sources and sending the data to an output plugin like InfluxDB. However, let’s consider the example shown in the above diagram. How do I make sure that my OPC-UA data is only included in the machine’s bucket of InfluxDB and my Modbus data is included within the sensors bucket. This is where routing comes into play.
Just to be clear routing = filtering in official Telegraf terminology. We essentially drop the metrics before they are processed by a plugin depending on the rule used:
- namepass: An array of glob pattern strings. Only metrics whose measurement name matches a pattern in this list are emitted.
- namedrop: The inverse of namepass. If a match is found, the metric is discarded. This is tested on metrics after they have passed the namepass test.
Let’s take a look at this example:
[[outputs.influxdb_v2]]
namepass = ["test"]
alias = "k8"
urls = ["${INFLUX_HOST}"]
token = "${INFLUX_TOKEN}"
organization = "${INFLUX_ORG}"
bucket = "bucket1"
[[outputs.influxdb_v2]]
namedrop = ["test"]
alias = "k8-2"
urls = ["${INFLUX_HOST}"]
token = "${INFLUX_TOKEN}"
organization = "${INFLUX_ORG}"
bucket = "bucket2"
[[inputs.file]]
alias = "file-1"
files = ["./data/sample.json"]
data_format = "json"
tag_keys = ["Driver", "Channel", "Trace", "Notes", "Address", "Instrument"]
name_override = "test"
[[inputs.file]]
alias = "file-2"
files = ["./data/sample.json"]
data_format = "json"
tag_keys = ["Driver", "Channel", "Trace", "Notes", "Address", "Instrument"]
name_override = "test2"
[[inputs.file]]
alias = "file-3"
files = ["./data/sample.json"]
data_format = "json"
tag_keys = ["Driver", "Channel", "Trace", "Notes", "Address", "Instrument"]
name_override = "test3"The breakdown:
- There are three file input plugins. Each measurement name has been overwritten using name_override (test, test2, test3).
- We have two InfluxDB output plugins, each pointing at a different bucket (bucket1, bucket2)
- In bucket1 we only want to accept metrics from "test". In this case, we use a namepass. This will drop all other metrics (test2 & test3) and write only "test" to InfluxDB.
- In bucket2 we will store all other metrics accept "test" since we are already storing this in bucket1. We can use namedrop to drop "test" before it's processed by the InfluxDB plugin. The rest of the metrics are accepted as normal.
Note: It’s worth mentioning that we have only discussed dropping metrics based on the measurement name in this blog. There is also equivalent functionality for tags (tagpass, tagdrop). Find more information here.
InfluxDB bucket routing by tag
So currently to route data between buckets, we generate an output plugin for each bucket. This is not particularly efficient if all data is ending up in the same InfluxDB instance. Another method of routing data between buckets is to use bucket_tag. Let’s take a look at a config:
[[outputs.influxdb_v2]]
alias = "k8"
urls = ["${INFLUX_HOST}"]
token = "${INFLUX_TOKEN}"
organization = "${INFLUX_ORG}"
bucket_tag = "bucket"
[[inputs.file]]
alias = "file-1"
files = ["./data/sample.json"]
data_format = "json"
tag_keys = ["Driver", "Channel", "Trace", "Notes", "Address", "Instrument"]
name_override = "test"
[inputs.file.tags]
bucket = "bucket1"
[[inputs.file]]
alias = "file-2"
files = ["./data/sample.json"]
data_format = "json"
tag_keys = ["Driver", "Channel", "Trace", "Notes", "Address", "Instrument"]
name_override = "test2"
[inputs.file.tags]
bucket = "bucket2"As you can see for each input file, we define a tag (this is completely optional since you can use one of your already defined tags. The tag value, though, should equal one of your bucket names). Within our InfluxDB V2 output plugin instead of defining a bucket explicitly, we add our tag to bucket_tag. The value of this tag is used to match against a bucket name.
Sensitive configuration parameters
A highly important security feature to consider is storing credential information within a config. If I told a security specialist that I was going to store their enterprise systems security token within a configuration file, I think they might just implode right in front of me. One of the best ways to mitigate this is using environment variables as part of your best practice. This provides more scope to apply security best practices but also provides further flexibility in your Telegraf config.
Here is an example:
[[outputs.influxdb_v2]]
alias = "k8"
urls = ["${INFLUX_HOST}"]
token = "${INFLUX_TOKEN}"
organization = "${INFLUX_ORG}"
bucket = "${INFLUX_BUCKET}"In the above example, each parameter for connecting to our InfluxDB instance has been anonymized by an environment variable. Note you could also deploy some form of scripting log for changing these parameters reactively and automatically restarting the Telegraf service based upon a desired system state change.
New config debugging
Itchy feet before pressing the go button on your Telegraf config? Don’t worry from days working in automation, I am exactly the same. Luckily, Telegraf has a few tricks we can deploy before we hit production.
Test flag
The test flag provides two great opportunities:
- A sense check of your configuration file (TOML parsing errors, connection errors, etc.)
- It also provides insight into what the final data structure will look like based on your pipeline design.
telegraf --test --config ./file_parsing/telegraf-json-v1.confRunning the above will yield the following output based upon my pipeline:
> test,Address=femto.febo.com:1298,Channel=1/1,Driver=Symmetricom\ 5115A,Instrument=TSC-5120A,Trace=HP5065A\ vs.\ BVA,host=Jays-MBP Bin\ Density=29,Bin\ Threshold=4,Data\ Type=0,Duration=86400000000,Duration\ Type=5,Input\ Freq=5000000,MJD=56026.95680392361,Sample\ Interval=0.1,Sample\ Rate=1000,Scale\ Factor=1,Stop\ Condition=0,Trace\ History=1 1638543044000000000
> test-list-2,host=Jays-MBP angle_0=0.35431448844127544,angle_1=0.09063859006636221,odometer_0=9.9,odometer_1=9.1,odometer_2=9.5,updated=1634607913.044073,x=566753.985858001,y=566753.9858582001 1638543044000000000Debug flag
After running the test flag you have two options; go gun-ho into running the Telegraf service or run using the debug flag. Using the debug flag exposes extended logging for each plugin within the pipeline. A great use case for this is trying to understand connectivity/parsing errors. Note that this is where Aliases come into effect.
telegraf --debug --config ./file_parsing/telegraf-json-v1.conf
Our log looks like this:
2021-12-08T13:24:13Z I! Starting Telegraf 1.20.3
2021-12-08T13:24:13Z I! Loaded inputs: file (3x)
2021-12-08T13:24:13Z I! Loaded aggregators:
2021-12-08T13:24:13Z I! Loaded processors:
2021-12-08T13:24:13Z I! Loaded outputs: influxdb_v2
2021-12-08T13:24:13Z I! Tags enabled: host=Jays-MacBook-Pro.local
2021-12-08T13:24:13Z I! [agent] Config: Interval:5s, Quiet:false, Hostname:"Jays-MacBook-Pro.local", Flush Interval:10s
2021-12-08T13:24:13Z D! [agent] Initializing plugins
2021-12-08T13:24:13Z D! [agent] Connecting outputs
2021-12-08T13:24:13Z D! [agent] Attempting connection to [outputs.influxdb_v2::k8]
2021-12-08T13:24:13Z D! [agent] Successfully connected to outputs.influxdb_v2::k8
2021-12-08T13:24:13Z D! [agent] Starting service inputs
2021-12-08T13:24:28Z D! [outputs.influxdb_v2::k8] Wrote batch of 9 metrics in 28.325372ms
2021-12-08T13:24:28Z D! [outputs.influxdb_v2::k8] Buffer fullness: 0 / 10000 metricsAdditionally, we can define the –once flag alongside –debug. –once will trigger the Telegraf agent to run the full pipeline once and only once. The main difference to keep in mind between the –test and –once flags is that the –test will NOT deliver the gathered metrics to the output endpoints. Here is an example of the test flag:
telegraf --once --config ./file_parsing/telegraf-json-v1.conf
Improving Telegraf's efficiency
So we have spent some time building a config based on the golden rules above. We start up our Telegraf service to begin ingesting and outputting metrics. The next step is to optimize Telegraf’s overall performance for the host it’s running on.
This will be different for each use case, but what I hope to provide is a checklist of steps that will allow you to make a calculated judgment on what settings to change.
Monitoring Telegraf
I am a strong believer in the saying “eating your own dog food”. If Telegraf is designed to scrape and monitor metrics from other platforms, it should also be able to monitor itself. We can do this using the Telegraf Internal Input Plugin.
Let’s create a config for it following our best practices:
- Create a conf file called telegraf-internal-monitor.conf
- Add the Telegraf Internal plugin and an InfluxDB output plugin (remember to apply an alias and routing). Find an example here. Note: I have chosen to enable memstats for this plugin. This is primarily due to the fact that some of the template dashboard nodes expect metric data from memstats. It is worth noting this feature is mostly relevant for debugging purposes and does not need to be enabled all the time.
- Thanks to Steven Soroka, there is an InfluxDB template for dashboarding the new metrics we are collecting. Find that template here.
We now have a dashboard that looks something like this:
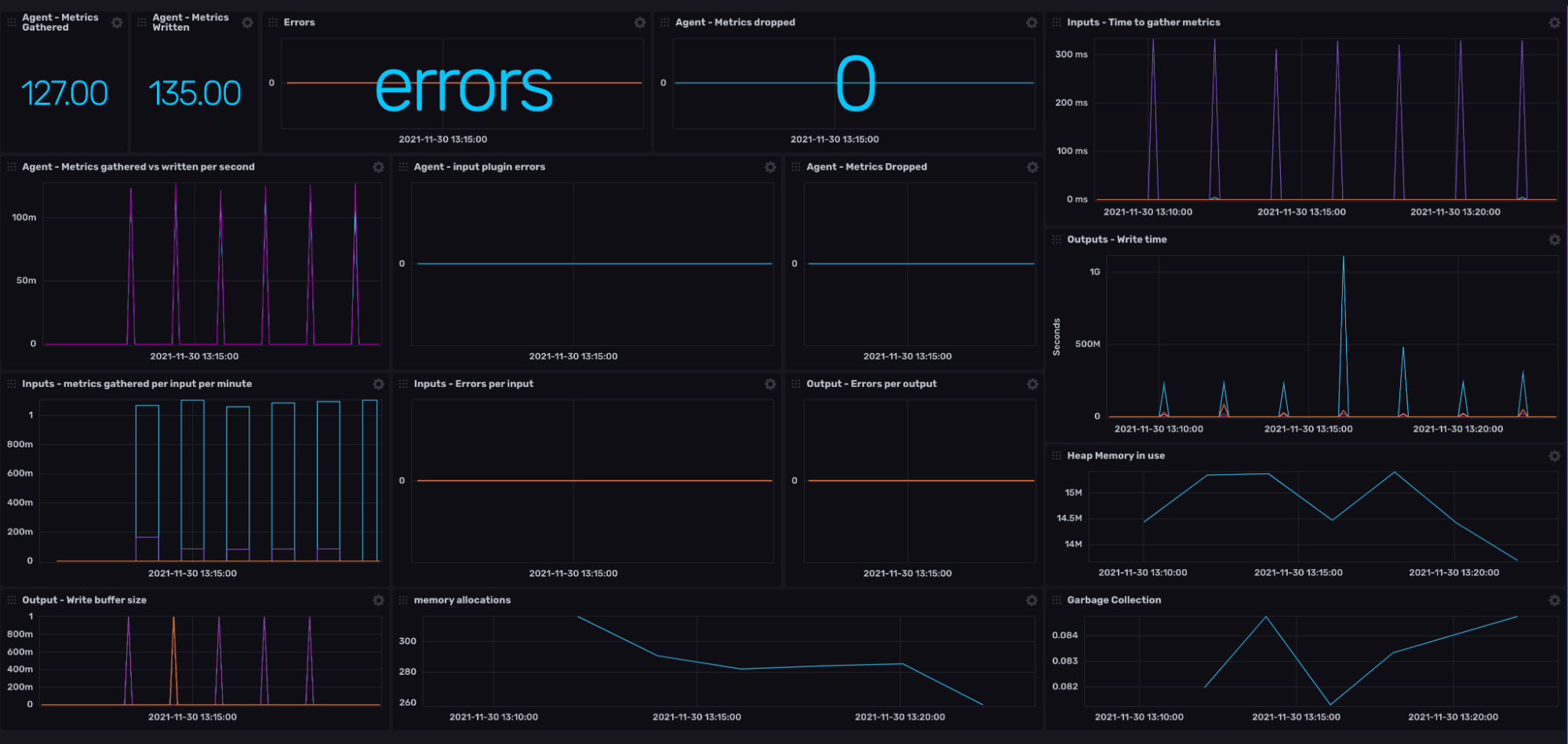
The checklist
So we have already ticked the first point of our list (Gaining visibility over our current Telegraf agent performance). So what next? Well, let’s have a look at the checklist and then explain the science/madness behind each item.
| Item | System Impact |
| Agent | |
| Is your time interval appropriate for the data you are collecting? | CPU / memory / bandwidth |
| Can you be more granular with your time intervals for each input plugin? | CPU / memory |
| Does your flush interval make sense when compared to your collection interval? | CPU / Latency |
| Have you considered the number of metrics you send per batch? | network / CPU |
Do you have scope to reduce the buffer size? Check the following dashboard cells:
|
memory |
| Have you defined a collection Jitter? | CPU / memory |
| Have you defined a flush Jitter? | network / CPU |
Time interval
In short, the interval parameter defines when the Telegraf agent will trigger the collection of metrics from each input plugin. So in general we should be conscious of when and why we are collecting data from a specific input. For example, if our endpoint only updates once an hour, then it makes no sense to scrape the endpoint every 10 seconds.
My golden rule is to explicitly specify a collection interval for each input plugin based upon the endpoint behavior. Ask yourself: how regularly do I need to monitor new data from this endpoint?
You also have the option of defining multiple Telegraf instances. We will discuss this within the Extra Credit section.
Flush interval
Parallel to this, you must also consider your flush internal. Flush interval simply sets a trigger time for when all metrics stored within the buffer are written to their output endpoints. Here are some points to consider:
- If you are collecting metrics on the hour, it does not make sense to flush your buffer before the hour.
- Experiment with your flush interval based upon your collection throughput. For example, the closer the flush interval is to a collection interval, the higher the processing requirements at that time.
- The longer the flush interval, the higher the latency until you see the metric in e.g. your database.
Batching
Batching governs how many metrics are sent to the output plugin at one time. For example, let’s consider we have a batch size of 20, but we are collecting 30 metrics per interval. Telegraf will automatically send the first 20 metrics to the output endpoints because we have reached our batching size. The remaining 10 will be sent afterwards. It is worth noting that when the flush interval is triggered, the entire buffer will be emptied in batches maximum to the buffer limit. For example, a buffer of 80 would release 4 batches of 20 metrics one after the other.
Writes and buffer size
So it is worth mentioning straight up the buffer affects memory usage. For most systems, the default limit will not cause a noticeable effect on system performance. That being said smaller edge devices (Raspberry Pi’s, Jetsons, etc.) may require more careful management of memory.
My advice is to use the internal plugin to monitor three metrics:
- Write buffer size - this one is a no-brainer. Keep note of any peaks within this count which reach close to your limit. Are there any trends in this data? Sharp spikes could be due to a number of input plugins triggering in close proximity. Gradual incline can be due to limited connectivity to output plugin endpoints.
- Metrics dropped - This is a strong indicator that your buffer size is too small for your desired input frequency.
- Metrics gathered vs. metrics written - This cell provides a good indicator of the overall health between collecting and writing metrics. If these two line graphs mirror one another closely, then you have scope to adjust your buffer size.
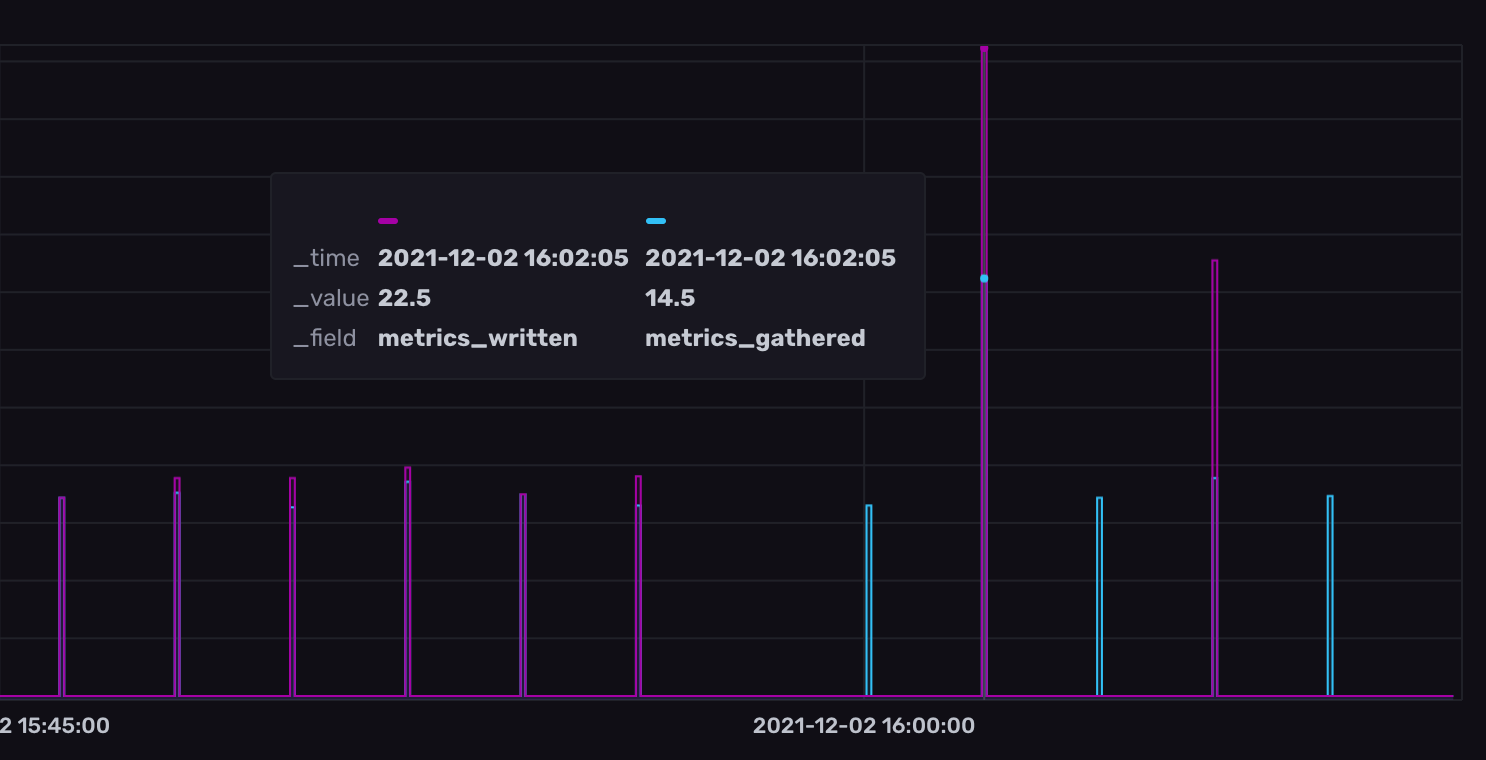
As you can see before 4 pm, my metrics gathered to metrics written mirrored each other nicely. After 4 pm, I doubled the flush interval parameter which we discussed earlier.
Collection and flush jitter
Another important feature Telegraf offers is staggering the collection and writing of metrics from different plugins. This is done using the collection and flush jitter. They both work slightly differently, so let’s discuss:
- Collection jitter forces each input plugin to sleep for a random amount of time within the jitter before collecting. This can be used to avoid many plugins querying things like sysfs at the same time, which can have a measurable effect on the system.
- Flush jitter randomizes the flush interval by a set amount of time within the jitter. This is primarily to avoid large write spikes from users running several Telegraf instances.
Extra credit
Finally, let’s discuss some optional wins which will help improve the monitoring and durability of your Telegraf solution.
Remote monitoring
So you might have a use case where the Telegraf host is not always accessible. In these situations, we still want to be able to monitor the health of our Telegraf agent. To do this, we can use Health Output Plugin (example config here):
[[outputs.health]]
service_address = "http://:8080"
namepass = ["internal_write"]
tagpass = { output = ["influxdb"] }
[[outputs.health.compares]]
field = "buffer_size"
lt = 100.0Let’s break this config snippet down:
- Service address allows us to designate a port for the health output to listen on. We will use this port to collect our health status.
- We then namepass and tagpass to filter for the specific metric we would like to operate on. In this case, we only care about internal_write which comes from our internal plugin discussed earlier. We further filter internal_write with tagpass to only give us metrics related to the InfluxDB output plugins.
- Lastly, we define a conditional argument that compares the value of a field. In this case, we are checking buffer_size to see if the value reaches 100 or over, then our conditional check fails.
Note that you can define multiple checks with this plugin. The main rule to keep in mind: If all conditional statements pass, then the health plugin outputs OK, else any one rule fails then the plugin outputs unhealthy.
Multiple Telegraf instances
Lastly, let’s reflect on the durability of our solution in the event of a failure. Since our Telegraf runs as a single process, we run the risk that if one of our plugins fails, this could interrupt the stability of the rest. One of the primary ways to mitigate this is running multiple instances of Telegraf. Let’s consider our original industrial example:
| <Telegraf-agent-1> opc_ua_machines.conf |
<Telegraf-agent-2> modbus_sensors.conf |
<Telegraf-agent-3> system_performance.conf |
|
Input: opc_ua client x2. internal x1 Output: influxdb x1, cloud connector x1 |
Input: modbus x1, internal x1 Output: influxdb x1, cloud connector x1 |
Input: cpu x1, etc. Output: influxdb x1 |
This architecture ensures that if one modbus_sensor collection fails, we will continue collecting data from our opc_ua_machines and system_performance. The easiest way to achieve this is through Docker containers. Here is an example docker-compose to get you started.
Conclusion
I hope this blog post gives you some confidence in the control you have over the Telegraf agent and its setup. In a lot of cases, Telegraf’s default behavior and setup will provide the plug-and- play functionality you need to get your project off the ground. It is always worthwhile keeping these golden rules in mind to make sure your Telegraf solution is scalable, efficient and maintainable as your project expands. I would love to hear your thoughts on this matter. Have I overlooked a golden rule that should be on here? Head over to the InfluxData Slack and Community forums (just make sure to @Jay Clifford). Let’s continue the discussion there!
