The Plan for InfluxDB 3 Open Source
By
Paul Dix /
Product
Sep 21, 2023
Navigate to:
The commercial version of InfluxDB 3 is a distributed, scalable time series database built for real-time analytic workloads. It supports infinite cardinality, SQL and InfluxQL as native query languages, and manages data efficiently in object storage as Apache Parquet files. It delivers significant gains in ingest efficiency, scalability, data compression, storage costs, and query performance on higher cardinality data. So far this year we’ve announced the availability of InfluxDB 3 in three separate flavors: InfluxDB Cloud Serverless (multi-tenant usage based billing for smaller workloads), InfluxDB Cloud Dedicated (managed single-tenant offering for medium to large workloads), and InfluxDB Clustered (self-managed for medium to large workloads). In this post, we’re announcing our plan to deliver an open source InfluxDB 3, which we’re calling calling InfluxDB Edge.
Talking about open source InfluxDB 3 pulls the thread on many other topics that people will likely have questions about as a result. So we’ll go into detail on multiple related topics, but here are the highlights:
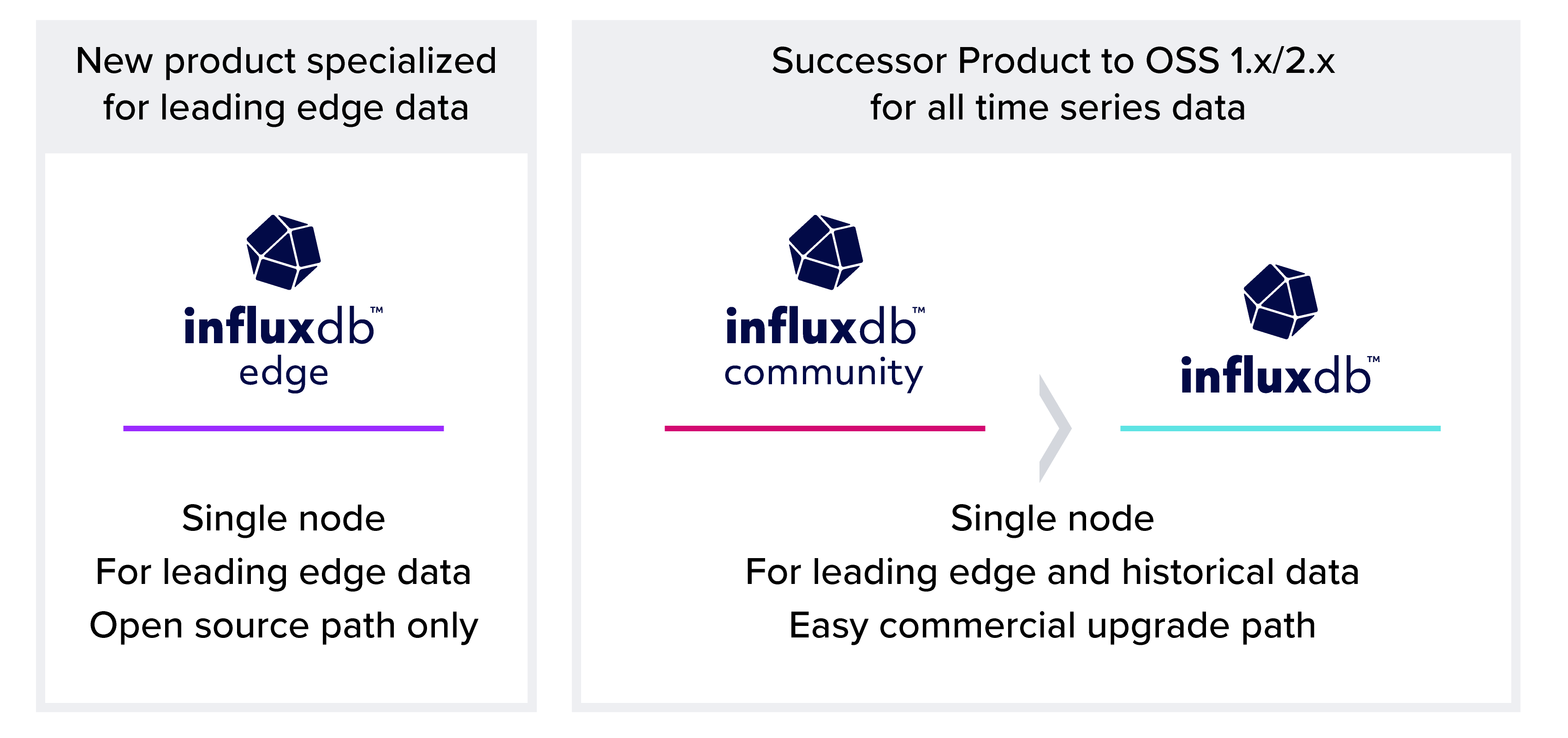
- InfluxDB 3 open source will be called InfluxDB Edge, with development happening in the existing InfluxDB repo, continuing under a permissive MIT or Apache2 license.
- After InfluxDB Edge is released, we will create a free community edition named InfluxDB Community with additional features not in Edge (this development effort will not be in the InfluxDB repo).
- InfluxDB Community will be upgradeable to a commercial version of InfluxDB with features not available in either Edge or Community.
- The InfluxDB IOx repo has been copied over to the InfluxDB repo under this commit. The IOx repo will be made private in a week.
- Flux is in maintenance mode. We will continue to support and run it for our customers with security and critical fixes, but our current focus is on our core SQL and InfluxQL query engine.
I’ll cover each of these topics in the following sections along with a reflection on the development of InfluxDB 3 (previously named IOx), Flux and how we got here. There are headings for each section to make it easier to skip ahead if the later parts of this post are of more interest to you.
InfluxDB Edge: Open Source InfluxDB 3
InfluxDB Edge will be a standalone process optimized for providing a queryable, real-time buffer of time series and observational data of all kinds stored as Parquet files in either object storage or local disk. It will have an embedded VM for connecting to third-party systems to pull data into its buffer or for transforming and acting on data as it arrives, periodically on a schedule, or when data is persisted in Parquet files.
We believe that Parquet—as a standard format for observational and analytic data of all kinds—will be transformational for data science, analytics, sensor data, data warehousing, and important data tasks of all kinds. What is lacking at the moment is an easy way to get data into this format while having it available for query before that data is written into larger immutable Parquet files. We think that InfluxDB Edge can serve as a time series database for the leading edge of data while making this data available to third-party systems to collaborate and build around Parquet and object storage.
From an API perspective it will support the InfluxDB 1.x and 2.x write APIs with Line Protocol, the InfluxQL query API (same as in both previous major InfluxDB versions), and all new APIs specifically built for 3, including the ability to query with industry standard SQL via FlightSQL or InfluxQL via Apache Arrow Flight. For those familiar with InfluxDB 1.x and 2.x, this should sound similar in some respects to the prior versions, but also very different at the same time.
The database architecture for InfluxDB 3 doesn’t include the inverted index (TSI) or the time series merge tree (TSM) storage engine that InfluxDB 1.x and 2.x were built around. Its storage system is designed to organize data in bulk chunks that can be quickly processed and kept in highly compressed Parquet files. This means that it is optimized for queries against the leading edge of data and time series and analytic queries in particular. InfluxDB 3 Edge will not include a compactor for re-organizing the data for deletes or query optimization over longer time periods, which means its sweet spot will be for collecting and querying recent data.
“The inclusion of an embedded VM will make InfluxDB Edge a powerful agent for collecting, processing, and monitoring data in addition to being a leading edge time series database.”

We don’t intend for InfluxDB 3 Edge to be a replacement or “light” version of our commercial clustered, distributed database offerings, or a full replacement for all use cases of InfluxDB 1.x or 2.x open source. There will be some intersection in functionality, but over time, it will fill a different spot in the tool belt and infrastructure of any company working with time series data at scale. We intend for InfluxDB 3 Edge to fill some of the same needs as previous versions while also expanding out into new territory. The inclusion of an embedded VM will make InfluxDB Edge a powerful agent for collecting, processing, and monitoring data in addition to being a leading edge time series database.
InfluxDB Community: the successor to InfluxDB 1.x and 2.x
After the initial release of Edge, we intend to release another version of InfluxDB 3 that will be useful for time series workloads on more historical and longer time frames of data: InfluxDB Community. It will be free to use and be upgradable to a commercial version named simply, InfluxDB. The free-to-use version will include functionality like a compactor, which will add capabilities for deletes and re-organizing files to optimize for queries on longer time ranges of data than InfluxDB Edge. For the InfluxDB 1.x and 2.x users that don’t quite fit within the capabilities of Edge, Community will be the tool of choice for them.
Features that we’re likely to include in the commercial single server version of InfluxDB 3 might include:
- Integration with third-party authentication providers
- Attribute- and role-based access control (ABAC & RBAC)
- Replicas for high availability
- Federated query across multiple Edge or Community nodes
Our intent is to enable as much of the 1.x and 2.x open source user base to migrate over to either Edge or the free Community version as possible, while maintaining our ability to ship a commercial version of the single server InfluxDB. If you’re interested in getting updates about this upcoming version of InfluxDB, sign up here.
Different projects for different use cases
With this announcement today, we’re laying out the long-term vision for our product line and where we expect to land different features. We’ve defined the following products:
- InfluxDB Edge (MIT/Apache2 open source, next product to release)
- InfluxDB Community (free to use, release after edge)
- InfluxDB (paid license, release with or after community)
- InfluxDB Clustered (self-managed, annual subscription, available now)
- InfluxDB Cloud Serverless (multi-tenant, usage billing, available now)
- InfluxDB Cloud Dedicated (single-tenant, resource billing, available now)
All these products will support the InfluxDB 1.x and 2.x write APIs, the InfluxQL query API, FlightSQL, and future 3 APIs related to writing data, querying, and background processing via the embedded VM. These APIs and the InfluxDB data model form the set of common interfaces across all these products. Additionally, Parquet as a format for sharing data in bulk enables movement of data from one product to another.
“InfluxDB Community will provide all the functionality of Edge, but also make queries over longer time ranges of data more efficient while adding delete capabilities.”
InfluxDB Edge will be for collecting and transforming time series and observational data while providing a leading edge real-time database. It will be useful at the Edge, but also within the data center. It can run on its own or as part of a larger infrastructure that has many Edge nodes sending data to larger InfluxDB Dedicated or Clustered installations.
InfluxDB Community will provide all the functionality of Edge, but also make queries over longer time ranges of data more efficient while adding delete capabilities. We expect that a number of users of InfluxDB 1.x and 2.x will require these features before they can make the upgrade to 3. This will provide them with a free pathway to do so when we release it after the initial release of Edge. This is useful as a historical time series database where high availability or scale are not a concern.
InfluxDB paid edition will provide all the functionality of Edge and Community while adding features for high availability and security for groups working with the database. InfluxDB Community will be able to have the paid features turned on through licensing. The commercial version of InfluxDB single server will be ideal for environments that do not require scaleout and prefer to run on bare VMs without the overhead and complexity of Kubernetes. For small-to medium-sized production workloads that require security or high availability, this will be an ideal choice.
Finally, InfluxDB Cloud Dedicated and InfluxDB Clustered represent our flagship distributed, dynamically scalable, secure, and most robust database offerings. Based on the same InfluxDB distributed core, these products run inside Kubernetes with workload isolation separating ingest, query, and compaction from each other. All service tiers can scale independently from each other, and we plan to add distributed caching and query workload isolation in future versions. For environments that span multiple teams using the same backend, or medium to larger workloads, InfluxDB Cloud Dedicated or InfluxDB Clustered will be the ideal choice.
The history of InfluxDB 3 (formerly IOx)
Initially, we started the development of InfluxDB 3 in early 2020 as a research project to answer a few questions:
- What would a new database architecture look like that supported infinite cardinality with data kept in object storage?
- Could we build around an existing SQL engine to add support for the language and get performance wins?
- What standards could we build around to enable more third-party integrations and compatibility with a broader ecosystem of tools?
As we looked into the changes we’d need to make to accomplish all these goals, we realized that we were looking at a near total rewrite of the core database. InfluxDB, up to this point, was written in Go with a database architecture that combined two kinds of databases into one: an inverted index and a time series store. We realized that this format wouldn’t work to serve the more analytical workloads we had in mind for future versions of InfluxDB.
When we announced we were working on a big update to InfluxDB in November of 2020 we called the project InfluxDB IOx, a new core for InfluxDB written in Rust, built with Apache Arrow, Apache DataFusion, Apache Parquet, and Arrow Flight. At that stage it was still a very early project with a long development path ahead. Over time, our choice of foundational tools evolved into a sophisticated stack for building analytic systems. We think that these building blocks are the future of open data systems, real-time analytics, lakehouse, and data warehouse architectures.
At the time we said that we’d build it as two pieces of software: an open source, shared-nothing data plane and a commercial closed source control plane, which we’d offer as a cloud-hosted product or self-managed software. Over the next three years of software development, we changed the architecture dramatically. As we made these changes, we did so in the open in the InfluxDB IOx repo.
While we’ve done this development, we’ve been unclear about what would ultimately be in the InfluxDB 3 open source builds. Today, with this announcement, we’re stating what we intend to include in the open source. As a first step, we’ve copied all the code from the IOx repo into the main branch (the new default) of the InfluxDB open source repo, which continues under a permissive MIT & Apache2 license. A week from today we’ll be closing out the IOx repo. For anyone that was pulling code from that repo, as of today they should point at this commit in the InfluxDB repo.
What is in the IOx repo is not what we intend to put in the final InfluxDB 3 builds, but we wanted to move that code over to a single point where anyone who was depending on it can reference it. Many of the libraries in the IOx code base will form the basis of InfluxDB 3 Edge. As of today, the main branch in the InfluxDB repo is the home for our open source efforts.
“Given the strength of the format and its increasing use in data and analytic systems, we think the time is right for InfluxDB 3 Edge to help users gather and query their data in real-time as it gets stored into Parquet files.”
Ultimately, our vision of an open data plane and a commercial control plane wasn’t viable due to necessary architecture changes, so we had to rethink what InfluxDB 3 would be. In the time we’ve been developing this new version of InfluxDB, we’ve seen Parquet get broader adoption. What seems to be missing at the moment is more useful tooling for gathering and transforming data into Parquet files. Given the strength of the format and its increasing use in data and analytic systems, we think the time is right for InfluxDB 3 Edge to help users gather and query their data in real-time as it gets stored into Parquet files.
Flux in maintenance mode
Flux is the custom scripting and query language we developed as part of our effort on InfluxDB 2.0. While we will continue to support Flux for our customers, it is noticeably absent from the description of InfluxDB 3. Written in Go, we built Flux hoping it would get broad adoption and empower users to do things with the database that were previously impossible. While we delivered a powerful new way to work with time series data, many users found Flux to be an adoption blocker for the database.
We spent years of developer effort on Flux starting in 2018. The size of the effort – including creating a new language, VM, query planner, parser, optimizer, and execution engine – was significant. We ultimately weren’t able to devote the kind of attention we would have liked to more language features, tooling, and overall usability and developer experience. We worked constantly on performance, but because we were building everything from scratch, all the effort was solely on the shoulders of our small team. We think this ultimately kept us from working on the kinds of usability improvements that would have helped Flux gain broader adoption.
For InfluxDB 3 we had a thesis that building on top of an existing engine would enable us to go faster and deliver more features with better performance over time. We decided on Apache Arrow DataFusion, an existing query parser, planner, and executor. It was a project still in its early stages in mid-2020 when we made this choice, but over the course of the last three years, there have been significant contributions from an active and growing community. While we remain major contributors to the project, it is continuously getting feature enhancements and performance improvements from a worldwide pool of developers. Our efforts on the Flux implementation would simply not be able to keep pace with the much larger group of DataFusion developers.
With InfluxDB 3 being a ground-up rewrite of the database in a new language (from Go to Rust), we weren’t able to bring the Flux implementation along. For InfluxQL we were able to support it natively by writing a language parser in Rust and then converting InfluxQL queries into logical plans that our new native query engine, Apache Arrow DataFusion, can understand and process. We also had to add new capabilities to the query engine to support some of the time series queries that InfluxQL enables. This is an effort that took over a year and is still ongoing. This approach means that the contributions to DataFusion also become improvements to InfluxQL given they share the underlying engine.
Initially, our plan to support Flux in 3 was to do so through a lower-level API that the database would provide. In our Cloud2 product, Flux processes connect to the InfluxDB 1 & 2 TSM storage engine through a gRPC API. We built support for this in InfluxDB 3 and started testing with mirrored production workloads. We quickly found that this interface performed poorly and had unforeseen bugs, eliminating it as a viable option for Flux users to bring their scripts over to 3. This is due to the API being designed around the TSM storage engine’s very specific format, which the 3 engine is unable to serve up as quickly.
We’ll continue to support Flux for our users and customers. Given the broad scope of Flux as a scripting language in addition to being a query language, planner, optimizer, and execution engine, a Rust-native version of it is likely out of reach. And because the surface area of the language is so large, such an effort would be unlikely to yield a version that is compatible enough to run existing Flux queries without modification or rewrites, which would eliminate the point of the effort to begin with.
For Flux to have a path forward, we believe the best plan is to update the core engine so that it can use FlightSQL to talk to InfluxDB 3. This would make an architecture where independent processes that serve the InfluxDB 2.x query API (i.e., Flux) would be able to convert whatever portion of a Flux script that is a query into a SQL query. That query would then get sent to the InfluxDB 3 process with the result being post processed by the Flux engine.
This is likely not a small effort as the Flux engine is built around InfluxDB 2.0’s TSM storage engine and the representation of all data as individual time series. InfluxDB 3 doesn’t keep a concept of series so the SQL query would either have to do a bunch of work to return individual series, or the Flux engine would do work with the resulting query response to construct the series. For the moment, we’re focused on improvements to the core SQL (and by extension InfluxQL) query engine and experience both in InfluxDB 3 and DataFusion.
We may come back to this effort in the future, but we don’t want to stop the community from self-organizing an effort to bring Flux forward. The Flux runtime and language exists as permissively licensed open source here. We’ve also created a community fork of Flux where the community can self-organize and move development forward without requiring our code review process. There are already a few community members working on this potential path forward. If you’re interested in helping with this effort, please speak up on this tracked issue.
We realize that Flux still has an enthusiastic, if small, user base and we’d like to figure out the best path forward for these users. For now, with our limited resources, we think focusing our efforts on improvements to Apache Arrow DataFusion and InfluxDB 3’s usage of it is the best way to serve our users that are willing to convert to either InfluxQL or SQL. In the meantime, we’ll continue to maintain Flux with security and critical fixes for our users and customers.
Continued commitment to open source
With InfluxDB 3 built around Apache Arrow, Apache DataFusion, Apache Parquet, and FlightSQL, we’ve expanded our commitment to open source. We actively contribute to, and in some cases lead, those upstream projects in addition to our efforts on InfluxDB 3. When we made the bet on these projects as the core of InfluxDB 3 in the summer of 2020, it wasn’t yet obvious that they would be adopted and contributed to as broadly as they have been.
We think that the Apache Arrow ecosystem of tools, Parquet, DataFusion, and Rust will form the basis of OLAP and large-scale data processing systems of the future. In addition to InfluxDB 3, we’re putting our open source efforts into these standards so that the community continues to grow and the Apache Arrow set of projects gets easier to use with more features and functionality.
We’re very excited about the future of InfluxDB Edge and hope you’ll follow along with the effort on the open source InfluxDB repo.
