Troubleshoot From Anywhere with PanSift
By
Community
updated November 15, 2023
Product
Use Cases
Developer
Navigate to:
This article was written by Donal O Duibhir, Founder & CTO, PanSift. Scroll down for the author bio and photo.
In 2015 I gave a brief talk at the Wireless LAN Professionals conference in Berlin about remotely troubleshooting client performance and Wi-Fi at scale. The solution I described then was rough and didn’t yet use a time series database (TSDB), but the requirements and goals are still valid and even more vital today. After many diversions, last year we finally built a productized offering to help technical teams support remote workers, irrespective of their location. It’s called PanSift, and at its core is InfluxDB.
Remote working has been around since the dawn of the Internet, but broadband penetration and knowledge work have proliferated over the last fifteen years. More recently, remote work became an urgent public health necessity for many sectors. This has led to an increase in flexible working agreements and a greater range of shared, dedicated, and personal workspaces. Gartner forecasts that ~53% of the UK & US workforce will work remotely during 2022, with 31% globally. It’s time to start treating the distributed user edge as a first-class tier, just as we do with our servers and network infrastructure.
The human edge of time
Employers and IT teams have scrambled to facilitate and scale up their WFH (Work From Home) and WFA (Work from Anywhere) arrangements. For some, remote work was already the status quo, with many working from coffee shops, coworking spaces, and home offices, but for others, this is a new way of working that’s brought a whole new set of challenges, especially at scale.
As complexity grows across this new distributed edge, engineering and support teams lack visibility of and access to local networks, wireless performance, and ISP configurations. Even if available, basic playbooks and point-in-time command-line scripts are not fit-for-purpose when trying to observe historical problems or catch intermittent issues.
When employee productivity is negatively impacted, teams lose time, money, and forward momentum. Culture and confidence can also take a hit, competence can be questioned, and blameless post-mortems become untenable, all leading to frustration on both sides of the fence. Operations are not wholly about how well people, processes, and technology perform, but about how well they fail.
Built on solid foundations
As the world changes, so too must our support models and tools. In a more decentralized world, we must meet employees where they do their best work, rather than cling to industrial legacies and images of where work was supposed to happen. Unfortunately, by decentralizing, complexity moves to the edge, but by instrumenting this new edge, we can fault-find and remediate faster when inevitable issues arise.
It’s early days for PanSift, but we’ve built something we believe will scale to this challenge. PanSift makes remote troubleshooting instantaneous. It uses continuous end-user experience monitoring to see things from the remote workers’ perspective. The agent gathers system and network health information from a remote worker’s laptop and sends this data back to PanSift’s InfluxDB instances at high frequency. As network conditions are dynamic (particularly Wi-Fi), these metrics are gathered every 30 seconds and then transmitted back every 60 seconds (or buffered during full outages) to enable high-fidelity troubleshooting. PanSift then automatically surfaces current and historical problems and can even suggest remediation actions (right now, we’re very focused on Wi-Fi clear channels, but lots more to come around DNS, IP, system usage, etc.).
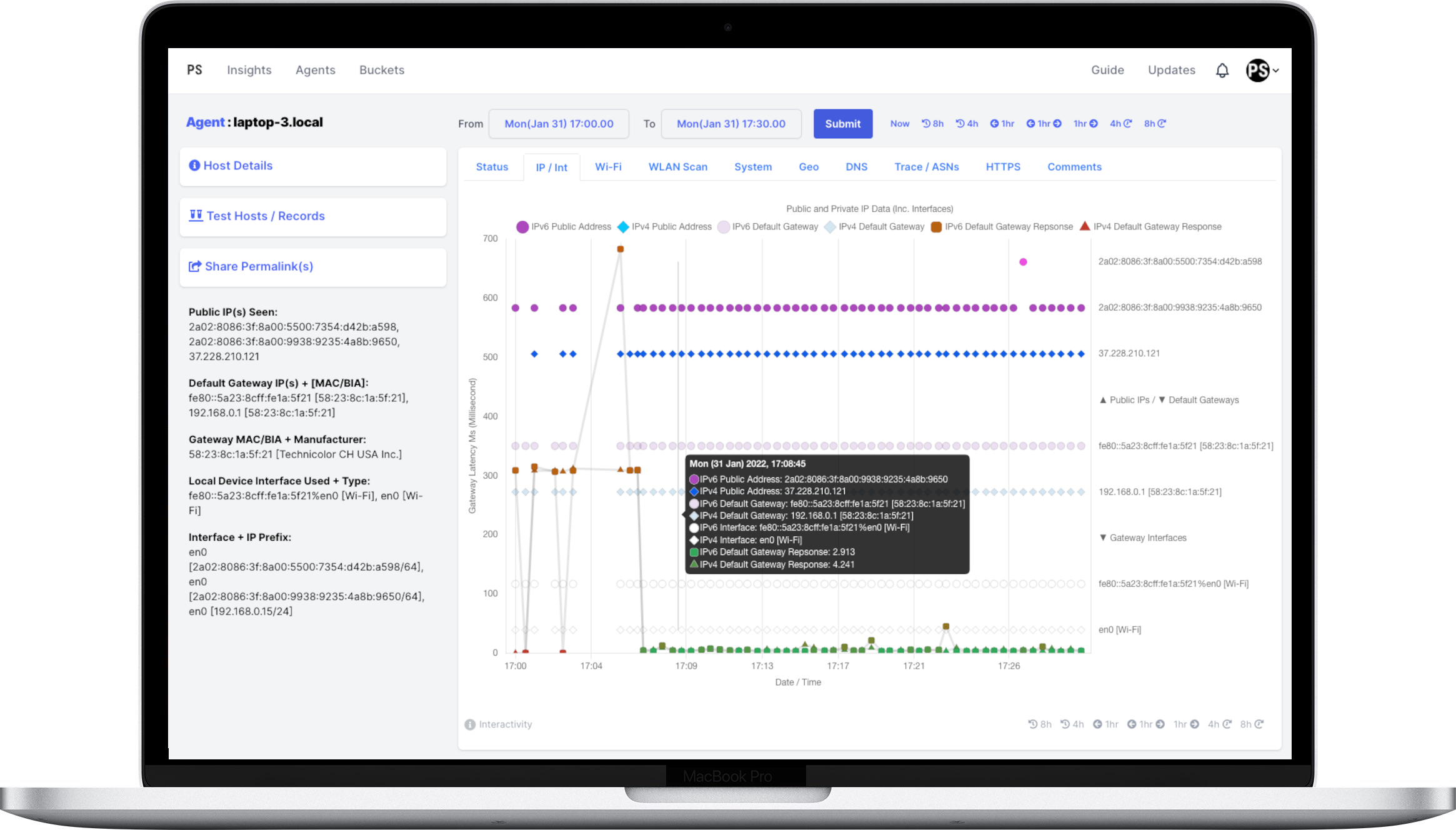
PanSift is comprised of five main components:
- Native endpoint agents (leveraging Telegraf) for data collection and transformation
- Serverless "lighthouses" (CDN based JS workers) for fast network probing
- API controlled DNS zones for the first tier of ingest traffic management
- Horizontal TSDBs (InfluxDB OSS) for store, query, and process (fronted by HAProxy)
- A web/SaaS (Software as a Service) front end (built with Ruby on Rails) for:
- Main UI (User Interface), IAM / multitenancy, etc.
- ZTP (Zero Touch Provisioning) of agents
- FLUX (InfluxDB scripting language) queries, insights, anomaly detection, etc.
- InfluxDB orchestration (via API + Ruby gem: influxdb-client-ruby)
- Network data enrichment via 3rd parties
Scaling every edge
PanSift agents write to InfluxDB instances based upon their bucket UUID (Universally Unique Identifier). The UUID is assigned during the initial Zero Touch Provisioning (ZTP). This UUID also exists in DNS and is queried by the agent as a CNAME RR (Resource Record), which then maps to a target InfluxDB instance. The main PanSift web application keeps track of active and healthy InfluxDB instances for the appropriate provisioning, I/O, and background jobs.
By distributing buckets across instances, we can create a type of horizontal elasticity which allows us to perform simple scaling, load balancing, steering, and future traffic optimizations. This architecture is modular and flexible, whereby the first DNS “tier” means we can also locally null route traffic from a source quickly if need be.
Velocity and viscosity
Rather than getting stuck in the mud and building everything from scratch, we decided early on that Telegraf could accelerate our agent development and let us focus on our own higher-order problems and presentation. Telegraf solves so many challenges like collection, scheduling, transformation, and transport, to name but a few, but it’s also performant and trusted. When adding in its extensibility, plugin architecture, and supported platforms, it became a no-brainer for accelerating our efforts.
The combination of Telegraf and InfluxDB (including its first-class API) immediately became a dependable and secure nexus for PanSift. We could again focus on the web application, workflows, user experience, and service outcomes rather than languishing trying to re-invent the wheel. In fairness, the InfluxDB ecosystem could be better thought of as not just the wheel(s) but the transmission, engine, and electrics of PanSift too!
So, by choosing InfluxDB, we knew that we were building on the best TSDB. We were betting on a platform that was powered by a strong community, one with a clearly communicated vision and roadmap that aligned with our ethos. For startups, velocity is key, so with a modular architecture that leveraged trusted and scalable building blocks, we avoided getting bogged down and started to iterate more quickly.
Future states
With an eye on capacity and workload segregation, we are considering how we might use the InfluxDB Cloud offering and migrate specific account workloads onto it. By using it as an elastic silo, it would result in simplified administration and reduced operational overheads. This might be suitable for larger customers with growing buckets, machine learning jobs, or other heavier and longer background tasks that should be isolated from standard web reads or agent writes.
Additionally, we’re not just excited about the innovations in the underlying time series datastore like InfluxDB IOx, but about how we might leverage InfluxDB tasks to develop new features. We’re also super excited about InfluxDB’s focus on developer experience and associated tooling.
Overall there’s a lot we’d like to achieve by helping IT teams to scale their remote workforces into a more positive and decentralized future. It’s not just about quality of life, reducing impact on the environment, or aiding in rural regeneration, but about empowering and enabling those in the trenches to remove toil and be more productive. With extra time comes extra opportunities to have a greater impact in other areas and facets of life.
P.S. The more free agents we deploy, the greater the network effect that enables us to ask deeper questions of larger datasets, be they technical in nature like “Does MCS index affect latency” or wider macro observations around ISPs and remote workers. Check out our one-click demo, or leave a comment on our nascent blog around which questions you’d like answered next!
About the author:

Donal is a Buddhist informed permaculture network geek who sees everything as interconnected. From corporate multinationals to startups, farming, and chasing unicorns… you might find him digging potatoes, tweaking the RF/Wi-Fi in a coworking space, designing a data-center fabric, or developing web apps…
