Under the hood with Continuous Queries - Part II
By
Jimmy Guerrero
updated December 14, 2025
Product
Navigate to:
In InfluxDB, continuous queries allow you to pre-compute and store query results so that they are ready when you need them, without overloading your database. In the first part of this series, we covered the basics of continuous queries, and their use-cases. In this part, we will take things one step further and discover how a continuous query is executed InfluxDB.
So, let’s get started
Continuous query execution service
To execute a query, whether continuous or not, a database needs to have an execution engine. Inside InfluxDB, the execution of a Continuous Query is handled behind the scenes by a background service called the Continuous querier. This service mimics the experience as though you sat at your keyboard, and continually executed the query. The querier service is started by the database engine, and waits for a continuous query to be created.
A continuous query can be created using the CREATE CONTINUOUS QUERY statement. Before the continuous query is stored, it is parsed and syntax validated to ensure that it is a valid continuous query. If all goes well, the metadata associated with the query is stored in the cluster-wide database metastore, that is accessible to all the servers in the cluster.
Scheduling a continuous query execution
To execute continuous queries, the querier service loops through all the databases, reads the continuous queries from the metastore, and checks them one-by-one, whether or not they need to be executed. This operation is repeated by the querier service once per second.
Once the querier service finds a continuous query to be executed, it figures out how often to schedule the query for execution depending on the group by interval specified in the query.
First, the execution interval is estimated using the following formula -
computeEvery = (group-by-time/ compute-runs-per-interval)
The group by interval specified by the user in the query, is divided by compute-runs-per-interval, which is the number of times the current and previous intervals will be computed. By default, the value of compute-runs-per-interval is configured to be 10.
For example, as shown below, if we have a continuous query with group by interval as 10m, compute-runs-per-interval set to 10, and compute-no-more-than set to 1m.
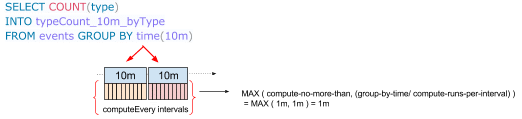
The query will be computed once per minute and there will be 10 runs in a 10m query interval.
Next, if the calculated execution interval is more frequent than the max frequency specified in the configuration (compute-no-more-than), the execution interval is overwritten by the max frequency value. In cases where the group by interval of a continuous query is shorter than the compute-no-more-than setting, the recompute-previous-n setting is used.
For example, as shown below, if we have a continuous query with group by interval as 5m, compute-runs-per-interval set to 10, and compute-no-more-than set to 1m.

The query will be computed once per minute (instead of every 1?2 minute) and there will be 5 runs in a 5m query interval.
Validate, run and write results
When a continuous query is created, the measurement and retention policy is extracted from the into clause of the query and validated. After validation, the query is run, and the output results are written into the measurement specified on disk. If no retention policy is specified for the measurement, the measurement is written into the default retention policy of the database.
With continuous queries, InfluxDB automatically recomputes previous intervals in case lagged data comes in. This is useful in the cases where you may have a data stream which lags behind or if you’re writing in historical data. After the first run-write pass, the execution service re-executes the continuous query for periods that recently passed upto the maximum interval setting specified in the configuration settings (recompute-no-older-than). Typically, this setting must be at least as old as the most out-of-sync timestamp that arrives, or else the data will not be part of the downsampling.
Conclusion
Today, we covered how continuous queries are executed inside InfluxDB. Stay tuned for our finale part three of this continuous query blog series to learn how you can monitor, and troubleshoot your continuous queries.
Till then, we invite you to a 14-day free trial of hosted InfluxDB + Grafana, and hope you get started with using InfluxDB for your applications.
