Using Flux to Get IoT Sensor Metadata from MySQL
By
David G. Simmons
updated December 14, 2025
Use Cases
Developer
Product
Navigate to:
If you’ve deployed an IoT solution, you’ve had to decide where, and how, to store all your data. At least from my perspective, the best and easiest place to store the sensor data is, of course, InfluxDB. My saying that can’t come as a surprise to you. But what about the other data you need to store? The data about the sensors? Things like the sensor manufacturer, the date it was placed into service, the customer ID, what kind of platform it’s running on. You know, all the sensor metadata.
One solution, of course, is to simply add all that stuff as tags to your sensor data in InfluxDB and go on about your day. But do you really want to store all your sensor data with each datapoint? Lots of things seem like a good idea at the time, but then rapidly devolve into a terrible idea when reality hits. Since most of this metadata doesn’t change often, and may also be associated with customer information, the best place for it is very likely in a traditional RDBMS. Most likely you already have an RDBMS with customer data in it, so why not just continue to leverage that investment? As I’ve said repeatedly, this is not the best place for your sensor data. So now you’ve got your IoT data in two different databases. How do you access it and merge it into one place where you can see it all?
Flux is the answer
Tell me you saw that coming. You had to have seen that coming. Ok, to be fair, you may have because, after all, how are you going to get your SQL-based data via Flux? That’s the beauty of Flux: it’s extensible! So we now have an extension that allows you to read data from either MySQL, MariaDB or Postgres via Flux. When I heard that this SQL connector was ready to go, I just had to try it. I’ll show you what I built, and how.
Build a customer database
The first thing to do was build a MySQL database with some Customer Information. I created a new database called IoTMeta into which I put a table with some sensor metadata. I also added another table with customer information about those sensors.
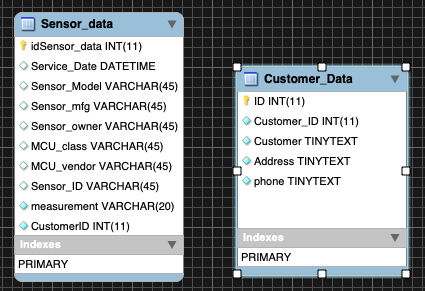
Pretty basic tables, really. The Sensor_ID field I populated with data corresponding to the Sensor_id tag in my InfluxDB instance. I bet you can see where I’m going with this already. I added a bunch of data:


So now my sensor metadata database has some information about each sensor I’m running here, as well as some ‘customer data’ about who owns the sensors. Now it’s time to pull this all into something useful.
Query the data with Flux
First, I built a query in Flux to get some of my sensor data, but I wasn’t actually interested in the sensor data itself. I was looking for an identifying Tag value: Sensor_id. This query will look a little strange, but it will make sense in the end, I promise.
temperature = from(bucket: "telegraf")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r._measurement == "temperature" and (r._field == "temp_c"))
|> last()
|> map(fn: (r) => {
return { query: r.Sensor_id }
}) |> tableFind(fn: (key) => true) |> getRecord(idx: 0)It returns a table of one row, and then pulls out the Sensor_id tag, and that’s where you’re probably saying “Whaaaat?” Remember: Flux returns everything in tables. What I need is essentially a scalar value out of that table. In this case, it’s a string value for the Tag in question. That’s how you do that.
Next, I’m going to get the username and password for my MySQL database, which is conveniently stored in the InfluxDB Secrets Store.
uname = secrets.get(key: "SQL_USER")
pass = secrets.get(key: "SQL_PASSW")Wait, how did I get those values into this Secrets Store anyway? Right, let’s back up a minute.
curl -XPATCH http://localhost:9999/api/v2/orgs/<org-id>/secrets -H 'Authorization: Token <token>' -H 'Content-type: application/json' --data '{ "SQL_USER": "<username>" }'One thing to note is that you get the <org-id> out of your URL. It’s not the actual name of your organization in InfluxDB. Then you do the same thing for the SQL_PASSW secret. You can call them anything you want, really. Now you don’t have to put your username/password in plain text in your query.
Next, I’m going to use all of that to build my SQL Query:
sq = sql.from(
driverName: "mysql",
dataSourceName: "${uname}:${pass}@tcp(localhost:3306)/IoTMeta",
query: "SELECT * FROM Sensor_data, Customer_Data WHERE Sensor_data.Sensor_ID = ${"\""+temperature.query+"\" AND Sensor_data.measurement = \"temperature\" AND Sensor_data.CustomerID = Customer_Data.Customer_ID"}" //"SELECT * FROM Sensor_data WHERE Sensor_ID = ${"\""+temperature.query+"\" AND measurement = \"temperature\""}" //q // humidity.query //"SELECT * FROM Sensor_Data WHERE Sensor_ID = \"THPL001\""// humidity.query
)You’ll see that I’m using the value from my first Flux query in the SQL query. Cool! You might also notice that I am performing a join in that SQL query so that I can get data from both tables in the database. How cool is that? Next, I’ll format the resulting table to have just the columns I want to display:
fin = sq
|> map(fn: (r) => ({Sensor_id: r.Sensor_ID, Owner: r._Sensor_owner, Manufacturer: r.Sensor_mfg, MCU_Class: r.MCU_class, MCU_Vendor: r.MCU_vendor, Customer: r.Customer, Address: r.Address, Phone: r.phone}))
I’ve now got a table that contains all the metadata about my sensor, as well as all the customer contact data about that sensor. It’s time for some magic:
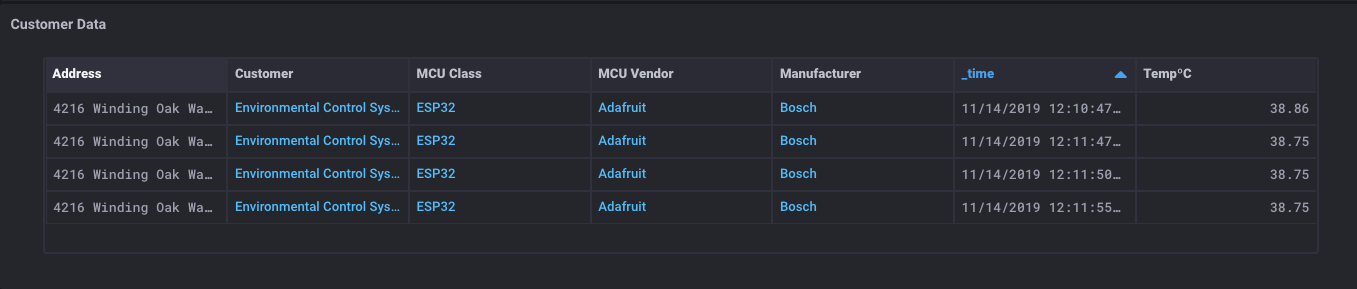
What is this sorcery? I have a table that has all the metadata about the sensor, some customer data, and the sensor readings too? Yep. I do. And here’s the really magic thing: Since you can get data from both SQL databases and InfluxDB buckets, you can also join that data together into a single table.
Here’s how I did that:
temp = from(bucket: "telegraf")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r._measurement == "temperature" and (r._field == "temp_c"))Gets me a table of the sensor data. I already have a table of the metadata from SQL, so …
j1 = join(tables: {temp: temp, fin: fin}, on: ["Sensor_id"] )
|> map(fn: (r) => ({_value: r._value, _time: r._time, Owner: r.Owner, Manufacturer: r.Manufacturer, MCU_Class: r.MCU_Class, MCU_Vendor: r.MCU_Vendor, Customer: r.Customer, Address: r.Address, Phone: r.phone}))
|> yield()I just join those two tables on a common element (the Sensor_id field) and I have a table that has everything in one place!
There are any number of ways that you can use this ability to merge data from different sources. I’d love to hear how you would implement something like this to better understand your sensor deployments.
I’ve done all this using the Alpha18 build of InfluxDB 2.0, which is what I run actually I custom-build my version from the master because I have some additions to Flux that I use, but that’s a whole other post. For this stuff, the Alpha builds of OSS InfluxDB 2.0 work just fine. You should absolutely give it a try!
