Using Flux to Write Data Out to SQL Data Stores
By
Nate Isley
updated December 14, 2025
Use Cases
Developer
Product
Navigate to:
As discussed in multi-data source Flux, Flux can now get data out of RDBMs with SQL.from() and use it to perform deeper analysis. In many cases, results from crunching data lend themselves naturally to time series storage. In others, the results are more appropriately leveraged on different data stores. In order to fulfill Flux’s general-purpose analysis engine vision, data must flow both into and out of InfluxDB.
To that end, InfluxDB 2.0 Alpha 15 introduced SQL.to(). SQL.to() mirrors Flux’s ability to pull data out of a SQL store by enabling writes to MySQL, MariaDB, and Postgres. Below, I outline using SQL.to() and walk through an example of counting events and storing them into Postgres.
Tables make the world go round
Once I understood that Flux results are truly just tables of data, I wondered how close a Flux result table was to an RDBMs table. It turns out that they are close enough that Flux can leverage their kinship to make SQL writes exceedingly elegant.
Once you shape and name your data to conform to the destination table definition, you simply pipe forward your data to SQL.to(). Let’s build up a use case for a new billing system to demonstrate this new functionality.
Fishtank health vendor - a new business model
My favorite fictional fish tank health vendor notices a large variation in the cost of supporting different customers. After studying their data closely, they learn costs are almost entirely driven by the number of corrective actions their automated water system performs. They decide to adjust their subscription model to one that charges customers for the number of weekly corrective events.
Luckily, every time the devices deployed into their customers’ fish tanks take corrective action, like adjusting pH or nitrate levels, the devices send an event to InfluxDB. Events are similar to the stream of sensor data, except for being emitted on demand instead of every X seconds. These on-demand events are also known as “irregular time series” because they can occur at any time.
The specific format and content of events can be anything you want, but let’s assume the events look like these two examples below (displayed in line protocol):
# Adjustment events - note timestamp will be added by InfluxDB at arrival time
water_sensor,type=adjustment,adjust_what=nitrates,change=up,device_id=TLM0101 triggering_value=5
water_sensor,type=adjustment,adjust_what=pH,change=down,device_id=TLM0102 triggering_value=9Why use a SQL data store?
The events are already in InfluxDB. Why introduce a SQL data store? There are several characteristics of a time series database that, generally speaking, do not make them an ideal foundation for a billing system.
InfluxDB is designed to flexibly adjust to large volumes of data that change quite often, either due to endpoint changes or data variability because clients can do things like schema at write. Often, users pour tens of millions of data points in very quickly but then downsample or delete most of them after a few weeks. This flexibility is great when you have, say, millions of different sensors or thousands of servers you constantly upgrade.
In contrast, anyone trying to create a billing system wants to keep many years of stable customer billing data. While capturing the raw data at scale makes sense to store within a time series database like InfluxDB, the aggregated and processed data represents a “finished product” that may make more sense to store with other customer data such as billing address and telephone number. A relational database designed for stable, infrequent table changes could be a much better foundation for a billing system.
Come on already, crunch the numbers!
To collect the data for the new subscription billing model, our fish tank vendor decides to create a simple weekly task to count adjustments for each device and save them to their Postgres database. (Note: this naive scenario will not scale at some large count of devices, both Postgres and InfluxDB will bottleneck. A more comprehensive approach might be to create a task per customer.)
The first step for storing the adjustment count is to create a table in Postgres. Here is the Postgres SQL command I used to create a simple example table:
CREATE TABLE adjustment_billing
(billing_record SERIAL PRIMARY KEY, device_id VARCHAR NOT NULL,
adjustment_actions integer, created_on TIMESTAMP);Armed with a table to store results, the vendor begins to put together the pieces of the Flux script. We start by getting the last week of data from the tank-health bucket, filtering in only the adjustment events, and grouping the data:
import "sql"
adjustmentActions = from(bucket: "tank-health")
|> range(start: -1w)
|> filter(fn: (r) => r._measurement == "water_sensor" and r.type == "adjustment")
|> group(columns: ["type", "device_id"], mode:"by")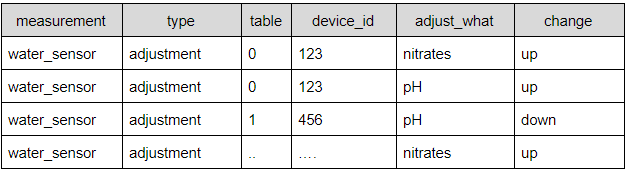
The result of grouping by type and device IDs is a table for every device. To get a count of adjustments for each device (table), we pipe forward the result to count the number of rows with a value in the change column:
// Count the number of changes for each device
|> count(column: "change")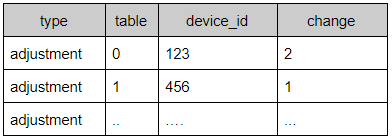
Note that at this point, only the columns called out by grouping and the count are retained. (Technically, _start and _stop times exist, but they are dropped in the next step).
This result is very close to the format of the SQL billing table we created, but it doesn’t quite line up and a final adjustment is required.
// Adjust the table to match the SQL destination schema/format
|> rename(columns: {change: "adjustment_actions"})
|> keep(columns: ["device_id", "adjustment_actions"])
Now, the data columns perfectly match the billing table, and the Flux script can simply store the result.
// Store result in Postgres
|> sql.to(driverName: "postgres", dataSourceName: "postgresql://localhost?sslmode=disable", table: "adjustment_billing")After the task is saved and set to run weekly, the adjustment event counts for every device will be stored in Postgres. If you query Postgres directly with a “SELECT * from adjustment_billing” after a task runs, you can see the fruit of all your Flux labors.
Get started with Flux today
Hopefully, this example of using Flux to write data to a data store other than InfluxDB illustrates the power and flexibility of multi-data source Flux. I am excited to explore all the different possibilities multi-data source Flux is sure to open up over the next few months.
Come join me in exploring Flux by signing up for InfluxDB Cloud 2 or by downloading the latest OSS alpha. As always, if you have questions or feature requests for Flux, head on over to Flux’s community forum and let us know!
