Table of Contents
In a previous post, we showed you how to make Flux queries in a Rails app. In this post, we’ll extend that knowledge to use GraphQL in a Rails app which leverages the power of Flux to query InfluxDB. This allows the client to fine-tune the results of an underlying Flux query. You’ll start to understand the powerful capabilities you can access when you pair GraphQL with Flux.
Before we begin, let’s talk a bit about GraphQL and why you would use it over a traditional REST API. I highly recommend doing the tutorials and looking through the documentation at How to GraphQL to better understand what GraphQL is and how to implement it in your apps. I did a lot of my own learning there.
What is GraphQL?
GraphQL is a query language that allows the client to specify exactly what data it wants in a single request rather than having to make multiple requests to fetch the same data or deal with over-fetching or under-fetching of data. It is database agnostic in that it does not itself directly query the database. Backend logic still handles that, as usual (in our case, a Flux query will be doing the heavy lifting). GraphQL uses resolvers to handle incoming queries and then implements the backend logic to fetch data. It allows the client to have more power over fetching data than it does with a traditional REST API that returns pre-determined data structures.
What are We Building?
We’re going to build a backend that triggers Flux to query our InfluxDB database when a client initiates a GraphQL query. In this case, we are a train company that uses sensors to capture data about our trains along with other pertinent information, such as outdoor temperature. We want our client to be able to choose exactly which data it wants to retrieve, such as speed and/or track temperature, rather than over-fetching or under-fetching data. We will therefore give our client a few GraphQL queries that it can customize to suit its needs.
Trains, Planes, and Data Points
In the last post, I used a measurement called cpu_load_short with various tags and fields. In this post I’ve seeded my InfluxDB database, called trains, with train data. The measurement is train_speed. My tags are driver, location, and train. My fields are outdoor_temp, speed, and track_temp. Below you can see a sample of data for three different drivers.
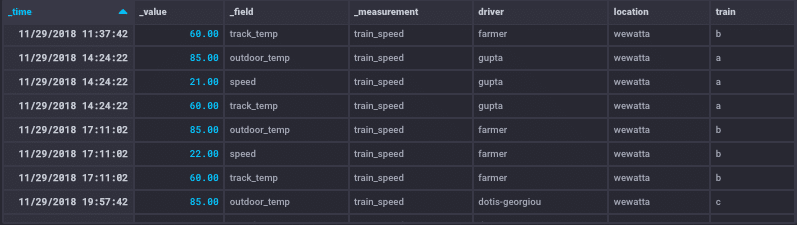
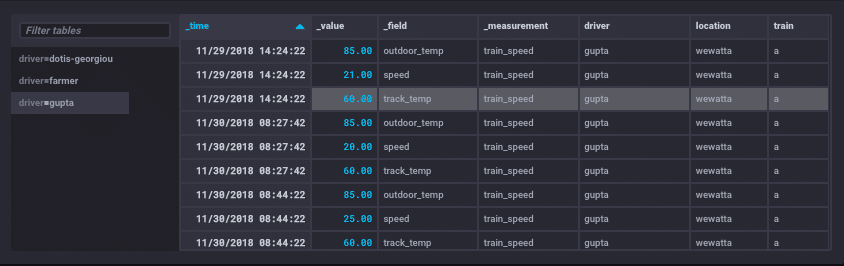
Below is a sample of data for one driver.
The method to format the annotated CSV response to our Flux query, which you saw in the previous post, now looks like this after some refactoring. It performs the same function as beforeexcept I’m now generating a train object rather than a cpu load object:
def parse_trains(response)
header, *rows = response.body.split("\r\n").drop(3)
column_names = parse_row(header)
rows.map do |row|
values = parse_row(row)
train_data = column_names.zip(values).to_h
Train.new(train_data)
end
end
def parse_row(raw_row)
raw_row.split(",").drop(3)
endI also made a new PORO (plain old ruby object) for my train object:
class Train
attr_reader :time, :measurement, :driver, :location, :train, :outdoor_temp, :speed, :track_temp
def initialize(train)
@time = train["_time"]
@measurement = train["_measurement"]
@driver = train["driver"]
@location = train["location"]
@train = train["train"]
@outdoor_temp = train["outdoor_temp"]
@speed = train["speed"]
@track_temp = train["track_temp"]
end
endThis PORO, generated at the end of my parse_trains method, comes in handy because the GraphQL gem simply fetches the respective instance variable value when resolving the incoming GraphQL query.
Adding GraphQL to a Rails Project
I found the How to GraphQL Rails tutorial to be really useful in getting started, and I recommend following the steps outlined there to add the graphql gem and the GraphiQL tool to your project.
The rest of that tutorial uses Active Record queries to fetch data from a traditional relational database using GraphQL resolvers. It’s helpful to understand how that works, but what if we want to fetch data from an InfluxDB instance? We can’t use Active Record for that, but as we learned in the last post, we can use a Flux query inside an HTTP call to fetch that data (and when the InfluxDB v2.0 client libraries are ready, we can use those).
For my new train data points, my HTTP request to the query endpoint of my InfluxDB database now looks like this:
def query_influxdb(time, filter_param = nil)
uri = URI.parse("http://localhost:8086/api/v2/query")
request = Net::HTTP::Post.new(uri)
request.content_type = "application/vnd.flux"
request["Accept"] = "application/csv"
request.body = flux_query(time, filter_param)
req_options = {
use_ssl: uri.scheme == "https",
}
response = Net::HTTP.start(uri.hostname, uri.port, req_options) do |http|
http.request(request)
end
endThis is a generic HTTP request that is invoked for every GraphQL query. A Flux query is then dynamically generated and passed into its request.body.
Depending on the GraphQL query that is being resolved, the Flux query is constructed as follows:
def flux_query(time, filter_param = nil)
%Q[
#{flux_from}
|> #{flux_range(time)}
|> #{flux_filter(filter_param)}
|> #{flux_pivot}
|> #{flux_yield}
]
end
def flux_from
"from(bucket:\"trains/autogen\")"
End
# There are two possible options in the range method because for most queries I just
# want a default range of the last 60 days, but in order to search by
# timestamp, I need to set my range to that exact timestamp. Flux
# allows me to do that by choosing an inclusive start time, which is my timestamp,
# and an exclusive stop time, which is one second later.
def flux_range(time)
if time == TIME
"range(start: #{time})"
else
start_time = Time.parse(time)
stop_time = start_time + 1.second
"range(start: #{start_time.rfc3339}, stop: #{stop_time.rfc3339})"
end
end
def flux_filter(filter_param = nil)
if filter_param
"filter(fn: (r) => r.driver == \"#{filter_param}\" and
r._measurement == \"train_speed\")"
else
"filter(fn: (r) => r._measurement == \"train_speed\")"
end
end
def flux_pivot
"pivot(
rowKey:[\"_time\"],
columnKey: [\"_field\"],
valueColumn: \"_value\"
)"
end
def flux_yield
"yield()"
endDefining GraphQL Types
After following the initial setup instructions outlined in the How to GraphQL Rails tutorial, I created a new file, app/graphql/types/train_type.rb, into which I placed the following code:
# defines a new GraphQL type
Types::TrainType = GraphQL::ObjectType.define do
# this type is named 'Train'
name 'Train'
# it has the following fields
field :time, types.String
field :measurement, types.String
field :driver, types.String
field :location, types.String
field :train, types.String
field :outdoor_temp, types.String
field :speed, types.String
field :track_temp, types.String
endSo what’s going on here, exactly? I’m defining an object type. I know I’ve got an InfluxDB database populated with train data points, with my measurement being train_speed, tags of driver, location, and train, and my fields being speed, outdoor_temp, and track_temp. I need the shape of my GraphQL object type to mimic the shape of my data points in order to render each of the fields. Each of the GraphQL fields thus corresponds to a column of my InfluxDB data points. Note that the Flux pivot function is what allows me to have my InfluxDB fields appear as their own separate columns, which makes the data more readable.
In addition to object types, there are also root types in GraphQL. Root types include a query type and a mutation type. Since we will be querying data, we need to establish our query type in which we will place the code for all of our queries. When we ran rails generate graphql:install in the initial setup, we generated a template file called app/graphql/types/query_type.rb. We now place into this file our various queries, which are just defined as fields, similar to the object type. My entire file looks like this (for easier reading I placed the aforementioned HTTP call, parsing method, and Flux query generator methods at the bottom as private methods):
require 'net/http'
require 'uri'
TIME = "-60d"
Types::QueryType = GraphQL::ObjectType.define do
name "Query"
field :allTrains, !types[Types::TrainType] do
description "Return all train data"
resolve -> (obj, args, ctx) {
parse_trains(query_influxdb(TIME))
}
end
field :trainByDriver, !types[Types::TrainType] do
argument :driver, !types.String
description "Find train stats by driver"
resolve -> (obj, args, ctx) {
parse_trains(query_influxdb(TIME, args[:driver]))
}
end
field :trainByTime, !types[Types::TrainType] do
argument :time, !types.String
description "Find train stats by time"
resolve -> (obj, args, ctx) {
parse_trains(query_influxdb(args[:time]))
}
end
end
private
def parse_trains(response)
header, *rows = response.body.split("\r\n").drop(3)
column_names = parse_row(header)
rows.map do |row|
values = parse_row(row)
train_data = column_names.zip(values).to_h
Train.new(train_data)
end
end
def parse_row(raw_row)
raw_row.split(",").drop(3)
end
def query_influxdb(time, filter_param = nil)
uri = URI.parse("http://localhost:8086/api/v2/query")
request = Net::HTTP::Post.new(uri)
request.content_type = "application/vnd.flux"
request["Accept"] = "application/csv"
request.body = flux_query(time, filter_param)
req_options = {
use_ssl: uri.scheme == "https",
}
response = Net::HTTP.start(uri.hostname, uri.port, req_options) do |http|
http.request(request)
end
end
def flux_query(time, filter_param = nil)
%Q[
#{flux_from}
|> #{flux_range(time)}
|> #{flux_filter(filter_param)}
|> #{flux_pivot}
|> #{flux_yield}
]
end
def flux_from
"from(bucket:\"trains/autogen\")"
end
def flux_range(time)
if time == TIME
"range(start: #{time})"
else
start_time = Time.parse(time)
stop_time = start_time + 1.second
"range(start: #{start_time.rfc3339}, stop: #{stop_time.rfc3339})"
end
end
def flux_filter(filter_param = nil)
if filter_param
"filter(fn: (r) => r.driver == \"#{filter_param}\" and
r._measurement == \"train_speed\")"
else
"filter(fn: (r) => r._measurement == \"train_speed\")"
end
end
def flux_pivot
"pivot(
rowKey:[\"_time\"],
columnKey: [\"_field\"],
valueColumn: \"_value\"
)"
end
def flux_yield
"yield()"
endThe allTrains query returns, as expected, all trains. My resolver is just returning that entire data set, and behind the scenes, the grapqhl gem is simply using dot syntax to call the methods to access each of the instance variables I defined in my Train PORO.
If we completed the initial setup properly, we can use the GraphiQL tool to simulate client queries. Let’s head over to http://localhost:3000/graphiql to test out our queries. I can return all of the fields with the allTrains query, as you see below:
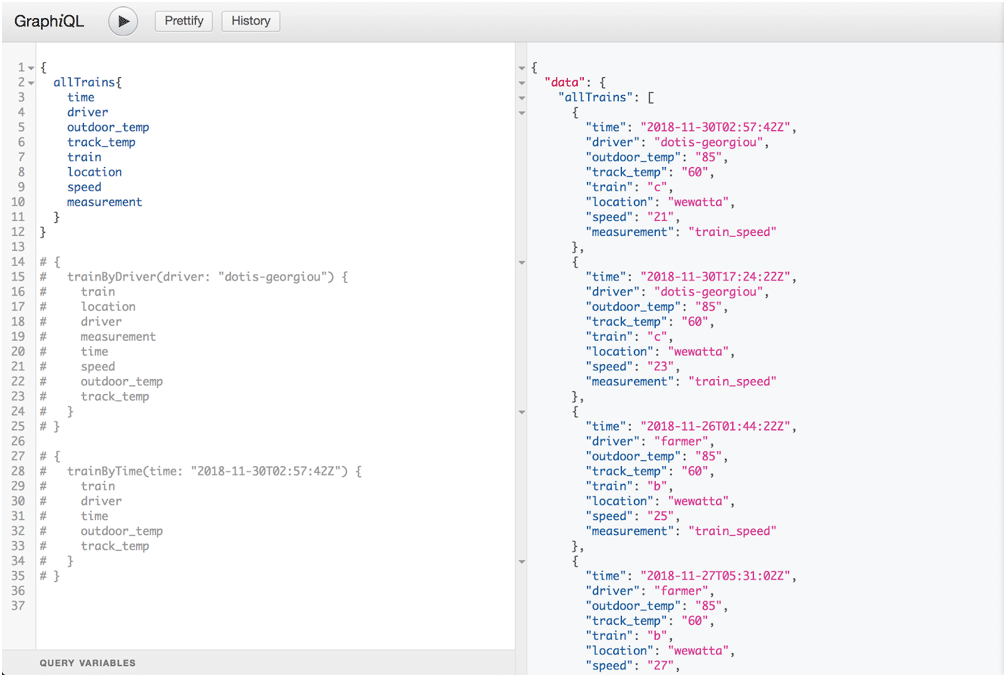
I can also return a selection of only the fields I want:
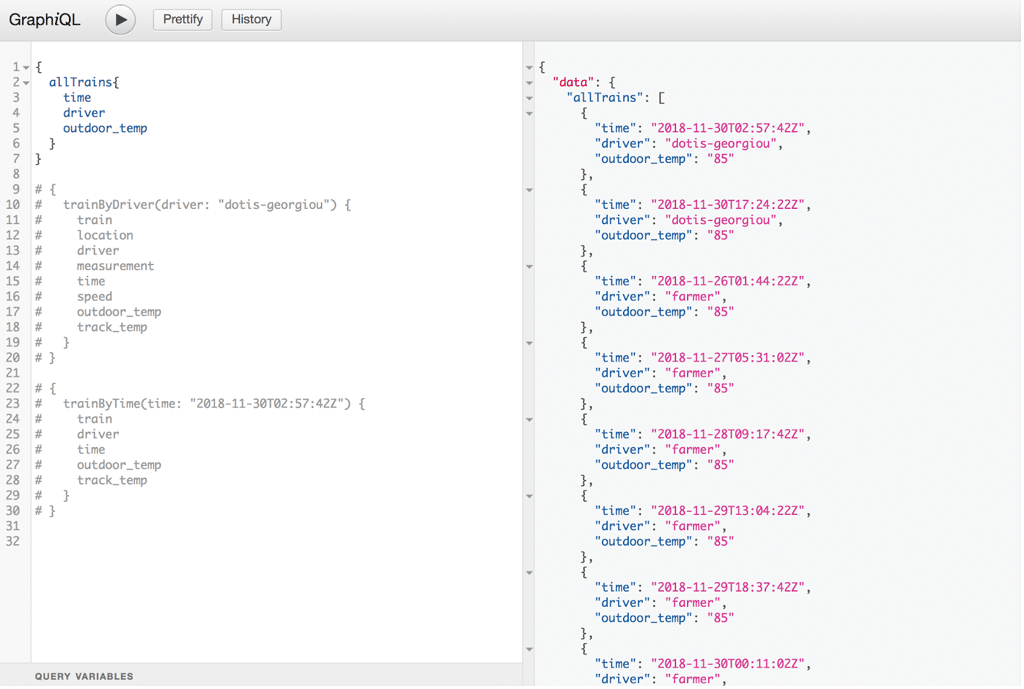
This is why GraphQL is so useful. The client gets to decide what fields it wants returned rather than having a pre-determined data set returned by a conventional REST API endpoint. On the backend, I can provide my client with a number of options to fetch the desired data, and these options are highly customizable.
For example, I can allow my client to pass in an argument to return all trains for a single driver using the trainByDriver query. In this query, the transformation is passed down to Flux to do the work of returning the train data associated with only the requested driver while GraphQL handles the field selection. The same functionality of only returning the requested fields exists in this query as well.
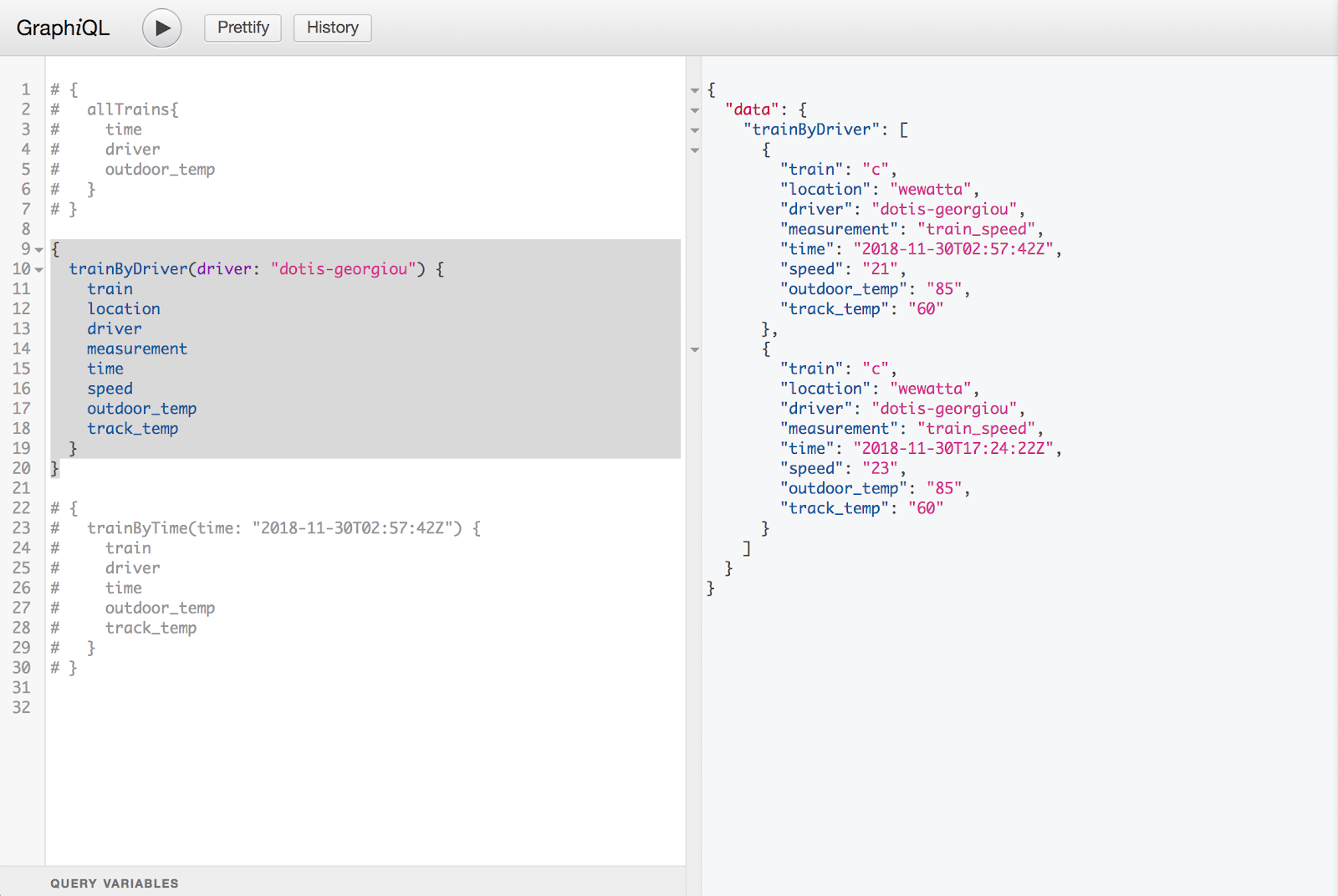
Since this is time series data we’re working with, it makes sense to allow our client to search by a single timestamp using the trainByTime query. As you can see in the Flux query generator code we discussed earlier, we again push the work of transforming the data into a Flux query to retrieve the data associated with that timestamp, and then have GraphQL return only the fields requested by the client.
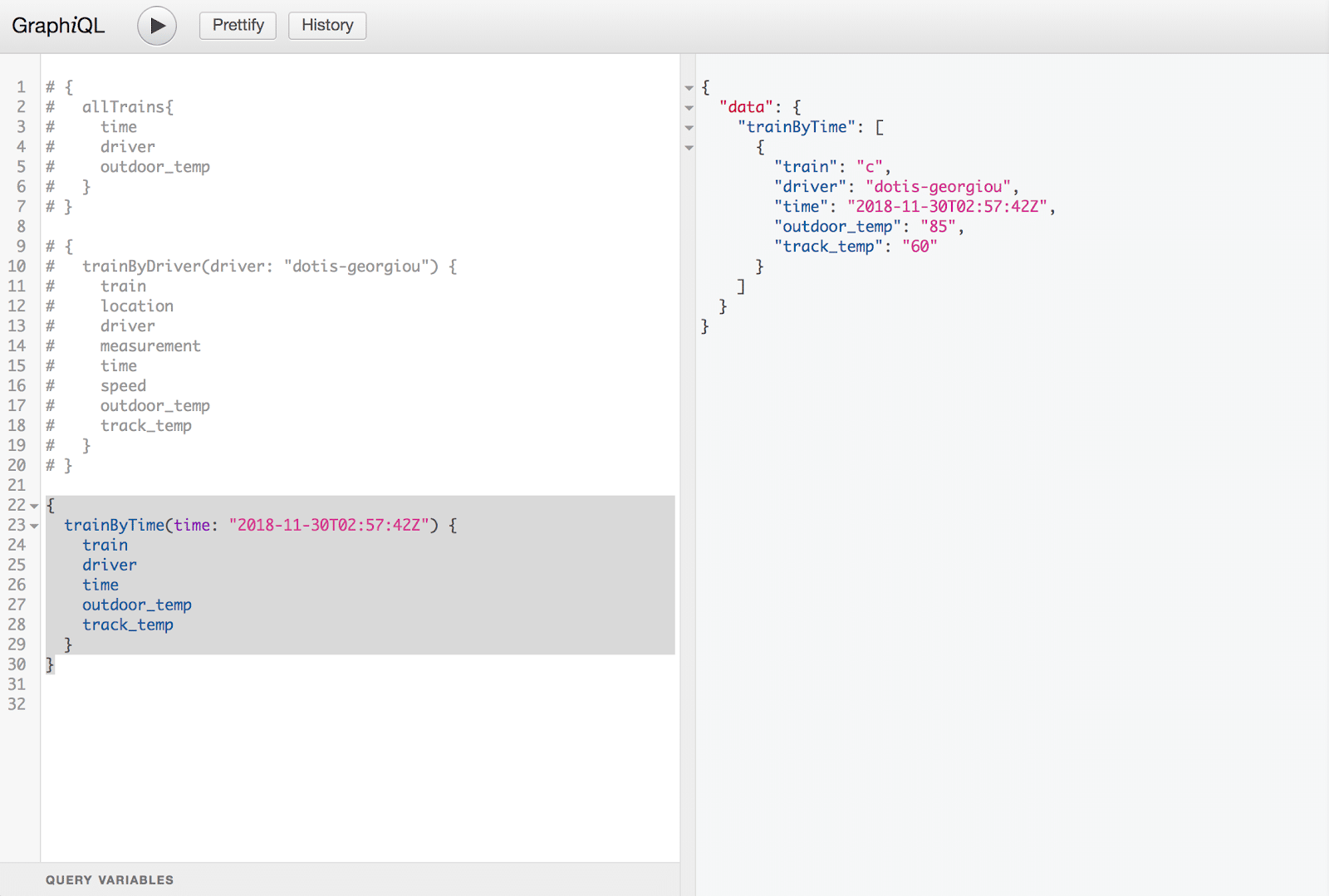
You can probably come up with a number of other queries that would be useful to a client, all of which will have the benefit of providing only the information the client specifically requests.
Summary
GraphQL makes a powerful companion to your InfluxDB database. It allows the client to specify exactly what information it needs without over-fetching or under-fetching data. Combined with the results of a Flux query, you now have two loci of control: the range and filter functions of your Flux query, and the types of GraphQL queries you open up to the client. The client can simplify its code and avoid superfluous code, particularly when you push the work of transformation down to the database query rather than requiring the client to make that transformation. Furthermore, you no longer require your client to change the endpoint it hits as requirements change because it is using GraphQL to query the API instead of directly hitting your endpoints. This creates a lot of flexibility in the backend while empowering the client to make data decisions on its own.
One thing that’s worth noting is that you could expose a Flux endpoint to the front end developer and they could write Flux rather than GraphQL to get the same result. However, the advantages of GraphQL are that you have client libraries and the other tooling (like the explorer) that are built on top of it. Also, if you end up hooking into other databases, those results can be joined together in a single API call (i.e. InfluxDB + Postgres).

