Using the New Flux "types" Package
By
Sean Brickley
updated December 14, 2025
Use Cases
Developer
Product
Navigate to:
As a strictly typed language, Flux protects you from a lot of potential runtime failures. However, if you don’t know the column types on the data you’re querying, you might encounter some annoying errors.
Suppose you have a bucket that receives regular writes from multiple different streams, and you want to write a task to downsample a measurement from that bucket into another bucket. If you know ahead of time that, for example, the _value column will always be a numeric type, you could run the following task without any problems:
option task = {name: "write-agg", every: 30m, offset: 1s}
from(bucket: "test-bucket")
|> range(start: -30m)
|> filter(fn: (r) => r._measurement == "logs")
|> aggregateWindow(fn: mean, every: 5m)
|> to(bucket: "test-downsample")But if you don’t know the schema of the data before you query it, you could run into trouble. It’s possible for this query to fail if, for instance, _value turns out to be a string instead of a number.

Until now, there has not been a one-size-fits-all solution to this problem. A filter on _field could do the trick if you know the labels you’re looking for, but maybe you don’t know those details, or maybe the list of labels you need to include or exclude is too long to comfortably fit in a filter predicate.
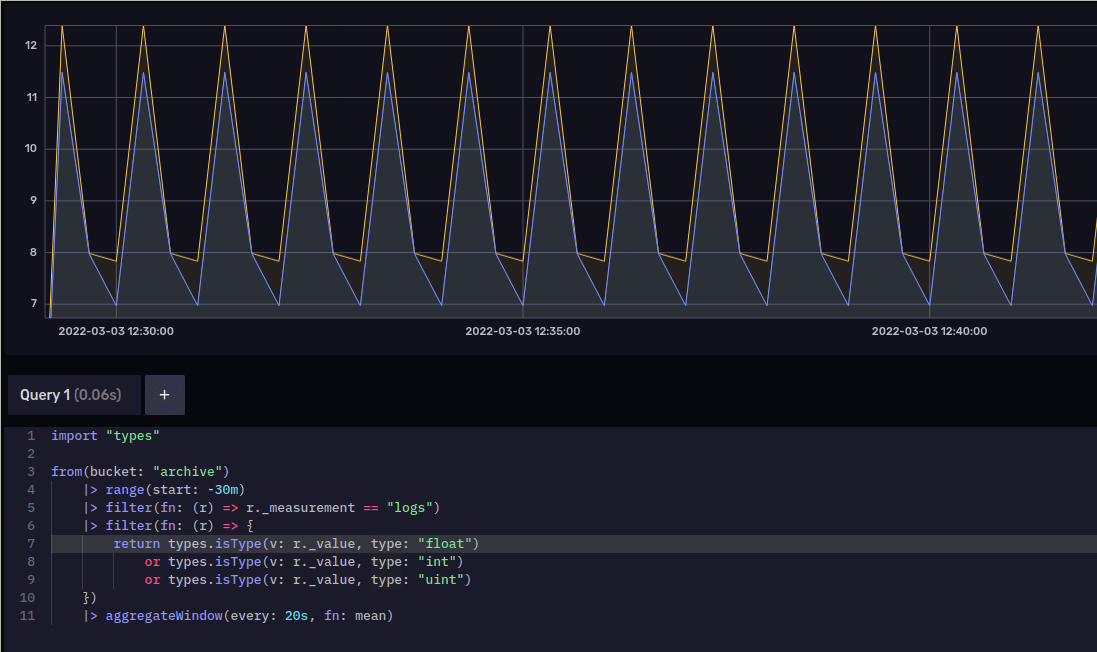
Enter the types package. This package introduces the isType function, which makes filtering on column types much easier. We can use it to fix our original query by importing the types package and adding a new filter that checks the type of r._value.
import "types"
option task = {name: "write-agg", every: 30m, offset: 1s}
from(bucket: "test-bucket")
|> range(start: -30m)
|> filter(fn: (r) => r._measurement == "logs")
|> filter(fn: (r) => types.isType(v: r._value, type: "float"))
|> aggregateWindow(fn: mean, every: 5m)
|> to(bucket: "test-downsample")Now we can be sure that any data piped into aggregateWindow has a _value column of type float, and thus avoid any potential type errors. Sure enough, our task succeeds and successfully writes the downsampled data to our new bucket:
We can also do more complex filtering using isType. Let’s imagine that the logs measurement we’re reading from the task above has fields with many different types. We want to aggregate all of them, but we know that some aggregates won’t work for every type. We can use isType to decide which aggregate function to use based on the type of data we find.
import "types"
option task = {name: "write-agg", every: 30m, offset: 1s}
from(bucket: "test-bucket")
|> range(start: -30m)
|> filter(fn: (r) => r._measurement == "logs")
|> filter(fn: (r) => {
return types.isType(v: r._value, type: "float")
or types.isType(v: r._value, type: "int")
or types.isType(v: r._value, type: "uint")
})
|> aggregateWindow(fn: mean, every: 5m)
|> to(bucket: "test-downsample")
from(bucket: "test-bucket")
|> range(start: -30m)
|> filter(fn: (r) => r._measurement == "logs")
|> filter(fn: (r) => {
return types.isType(v: r._value, type: "string")
or types.isType(v: r._value, type: "bool")
})
|> aggregateWindow(fn: last, every: 5m)
|> to(bucket: "test-downsample")This new package is included in the latest version of Flux, and is available to all cloud users. We encourage you to test it out and let us know what you think!
