Why Use a Purpose-Built Time Series Database?
By
Susannah Brodnitz
updated October 18, 2023
Developer
Navigate to:
This article was originally published in The New Stack and is reposted here with permission.
For many workloads, using a time series database is a smart choice that saves time and storage space.
Developers and companies have more database choices than ever. Choosing the right database for a project saves time when writing and querying data. As companies work with larger datasets to make increasingly intelligent and automated systems, efficiency is key. For many workloads, using a time series database is a smart choice that saves time and storage space.
How time series data is different
Time series data is any metric with a timestamp. It includes many kinds of variables, from weather patterns to CPU usage. It often comes from sensors, systems or applications that need to make real-time decisions. This data is vital to understanding past performance and creating models to predict future outcomes. The amount of data involved in these calculations can quickly add up, and it’s important not to lose resources to an inefficient data architecture.
Time series databases are designed to handle typical time series workloads. They’re optimized to measure change over time, rather than relationships between data points. The two main kinds of time series data are metrics, which are taken at regular intervals, and events, which are taken at irregular intervals due to outside events or user measurements. It’s important that a time series database is able to handle both metrics and events, and is able to average events and convert them to metrics.
Storing data
A good database needs to store data securely and efficiently. Users have to be able to write data to it quickly and feel confident that it can handle the volume of data they plan to store in it. Time series data can have huge volumes, and the databases it’s stored in need to be built to accommodate that. Time is linear, and time series databases can take advantage of this by appending new data to existing data. They’re optimized to quickly write in time-stamped data the way it’s most commonly used to save time from the moment users begin writing in data.
Time series databases also may have lifecycle management built in. It’s common for developers or companies to initially collect and analyze highly detailed data and, as time goes on, to want to store smaller, downsampled datasets that describe trends without taking up as much storage space. Time series databases can take this into account and automatically aggregate and delete data as necessary for each application. If developers use a more basic database, they often need to create new systems to manage data in this way. With a time series database, it’s already taken care of and developers can focus on their applications.
Time series databases also need to be easily scalable. For example in IoT use cases, as more sensors are added and projects expand, data increases exponentially. This is common in time series workloads, and the databases used for these projects need to be able to accommodate it.
Querying data
Using a time series database also speeds up query time for time series workloads. One of the most common things to do with time series data is to summarize it over a large period of time. This kind of query is very slow when storing data in a typical relational database that uses rows and columns to describe the relationships of different data points. A database designed to process time series data can handle queries exponentially faster. Time series databases also may have built-in visualization tools or advanced functions to make it simpler to do common kinds of time series analysis.
Choosing a time series database
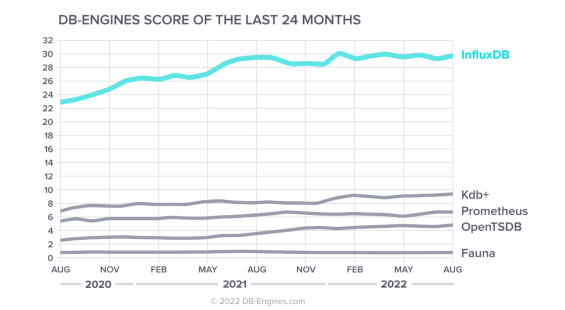
There are a few time series databases out there that you can explore. For this blog post, we will look at the leading time series database according to DB-Engines, InfluxDB. InfluxDB assigns a measurement name and timestamp to data and uses key/value pairs for data values and metadata. It keeps measurement names and sets of tags in an inverted index, which speeds up queries. Users can write queries based on measurement, tag and/or field across a time range and receive results in milliseconds. A single InfluxDB server can handle over 2 million writes per second. Compared to a NoSQL database like Cassandra, InfluxDB writes data 4.5 times faster, uses storage space 2.1 times less and returns queries 45 times faster.
Databases are the backbones of many applications and working with time-stamped data in a time series database saves developers time and storage. Choosing the right database for an application lets developers focus on building cool projects, rather than spending time managing architecture before they can get started.
