Table of Contents
If you’ve watched Coda Hale’s popular Metrics, Metrics Everywhere video, you know that one of the main takeaways of his talk is that data helps you to make better decisions, and data must be measured, to be effectively managed.
Data, or more specifically metrics about your systems can give you incredible insight into your entire stack, touching on many areas. If you’re going to add a metric for everything that moves, you better have the infrastructure to back you up.
In this post we’ll look at a few approaches for scaling a graphite installation using Go specific technologies including graphite-ng and InfluxDB.
Meet Graphite
Graphite is a popular, real-time metrics storage and graphing tool written in Python that allows you to store numeric time-series data and graph it on demand. What you do need to bring to the metrics party is some way of sending graphite the data. You can accomplish this with collecting agents like collectd. At a high-level, the architecture of a typical graphite setup consists of three main components:
- carbon - a daemon that listens to metrics data
- whisper - a storage library for storing this data
- graphite web - a web application that renders the graphs on demand
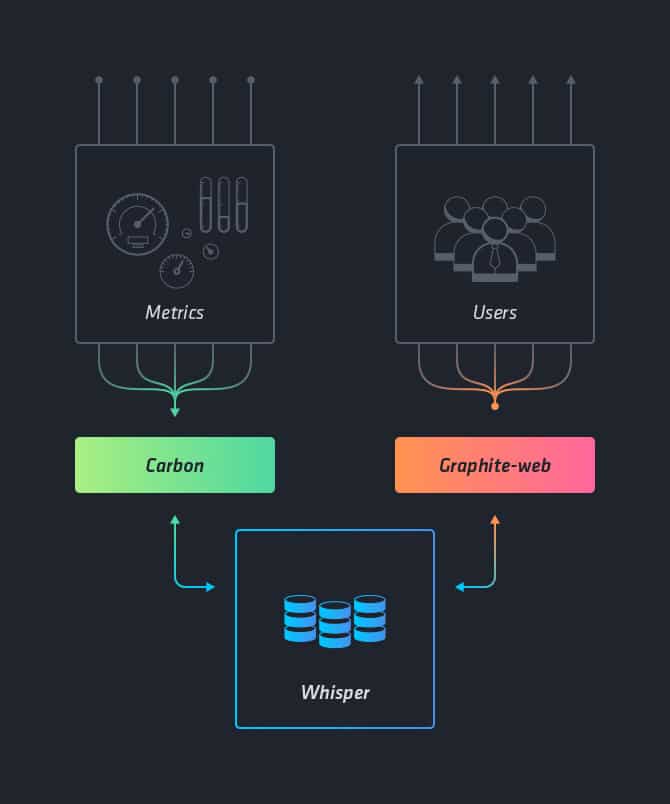
A standard graphite setup, where carbon writes metrics into whisper, which stores them for visualizing in graphite-web
This configuration generally works pretty well on a small-scale, where the carbon daemon listens for metrics and reports it to the whisper storage database. But as you reach higher scale say around thousands to millions of metrics per second, add more timelines, and want to aggregate your metrics, you will start hitting the limits of the architecture. You might run into scenarios where carbon just drops metrics because it can’t manage the load thrown at it or cannot manage multiple file handles for the different timelines it has to persist in whisper. So, if you’ve managed to outgrow the limits of this basic setup, what’s next?
Introducing graphite-ng - Graphite on steroids
To address some of the scalability problems with the basic graphite infrastructure, Dieter Plaetinck rewrote the graphite server in Go, a language that makes writing concurrent programs easier and more efficient.
Graphite-ng outperforms a vanilla graphite installation and can easily handle millions of metrics per second. As metrics flow into a graphite-ng powered system, it can perform validation of all the incoming data metrics up-front, so you don't have to worry about cleaning up metrics later on the backend. It can also combine multiple metric series, on-the-fly, into a new series, and his functionality allows for faster metrics aggregation as needed.

High-level architecture diagram of go written Graphite-ng, and Carbon-relay-ng, with Whisper backend.
It also is worth noting that graphite-ng can be configured to replicate data to multiple backends such as ceres, and elasticsearch, provide redundancy, or partition the data, to balance load.
InfluxDB is working on a more scalable solution
To optimize your entire graphite stack, it helps to choose the right backend database to store the metrics. When considering what backend infrastructure to use, here are couple of high-level characteristics your database needs to have:
- Scalable - Look for the backend to support millions of concurrent write operations
- Highly available - A backend that is down, doesn't allow you to store or visualize data
- Time Series Support - Make sure that the backend can handle time series data natively and be able to to store and serve it efficiently
Whisper, the default graphite storage engine, unfortunately does not meet all these requirements. It is written in python and cannot scale in heavy-write scenarios. It is also memory heavy and keeps multiple file descriptors open at a time, one for each metric.
InfluxDB is aiming to solve these problems in the upcoming releases. The 0.8.8 release of InfluxDB used LevelDB as the underlying storage engine, which had better performance than Whisper. Upcoming releases of the 0.9 line are taking lessons from LevelDB and will aim to exceed 0.8's performance on the storage engine side, while bringing in clustering for HA and horizontal scalability.

High-level architecture of go based carbon-relay-ng feeding information to InfluxDB
InfluxDB is designed to be simple to install and configure. When clustering support becomes generally available you’ll be able to run a multi-node cluster and replicate your data fully across the nodes for high-availability. Of course, you can get started with testing clustering now, but it’s not yet ready for production use. InfluxDB also provides many ways to write data into it including the line protocol, several client libraries and plugins for common formats like graphite.
Besides the graphite-ng project, Dieter has a cool repo that uses Docker to simplify the process of installing and configuring a graphite system with an InfluxDB backend. Check it out here.
The docker set up pretty much boils down to:
1) Install Docker on your system
2) Make a new directory and put your own Dockerfile in it, so it looks like this:
FROM vimeo/graphite-api-influxdb
3) Put a customized graphite-api.yaml in this directory, you can base yourself off the graphite-api.yaml in this repository
4) Build!
docker build .
5) Run!
docker run -p 8000:8000 <image-id>
What's next?
Looking for all the goodness and scalability of InfluXDB in a managed environment plus Grafana, a feature rich metrics dashboard and graph editor for graphite? Then sign up for a free 14-day trial of Hosted InfluxDB + Grafana which gets you up and running in seconds!
Get your InfluxDB hoodie while they last!
Does your company have a cool app or product that uses InfluxDB in production? We’d love to feature it on influxdb.com and give you a shout out on social media. As a “thank you” gift, we’ll send you an InfluxDB hoodie and a pack of stickers. Just fill out this simple form and we’ll let you know when your entry is live and the hoodie is in the mail. Drop us a line at [email protected] if you have any questions. Thanks for the support!
