What is observability? An In-Depth Guide
Or subscribe on AWS, Azure or Google Cloud
What is observability and why do you need it?
In distributed systems, observability is the measure of how well the internal states of the system can be inferred from its external outputs. Software observability is the practice of monitoring your software in order to understand its behavior and identify issues.
Modern distributed systems are complex, and failures can happen at any level. To ensure reliability and uptime, you need to be able to identify and fix issues as quickly as possible. Observability allows you to do that by giving you visibility into all aspects of your system.
There are many factors to consider when designing an observable system. You need to think about what data to collect, how to collect it, and how to surface it in a way that will be meaningful to you. You also need to consider how to balance the need for visibility with the need for privacy and security. You also need to take into consideration the tradeoff between how much data you are storing and analyzing with how much value that data is providing to your business to ensure you are getting a proper return on investment for your observability implementation.
Why is observability important?
In short, observability is important because when implemented and used properly it will not only make your users happier due to better performance and reliability, but it will also help you optimize your software so you can save costs on hardware. In a competitive market this will give you an edge over other companies who don’t take advantage of modern observability practices to improve their software development process.
How does observability work?
At the most basic level, observability works by instrumenting your application to generate data, storing that data, and then analyzing your data to generate insights.
The first step in implementing an observability system is to instrument your software with the necessary tools to generate data. This might include tools like logging, metrics, and distributed tracing libraries or frameworks. These tools work together to generate a detailed picture of system behavior, including information about requests, errors, performance metrics, and much more.
Once the system is instrumented, the data generated by those tools needs to be sent somewhere for storage. This will generally be some sort of data warehouse or columnar database optimized for analytics workloads. In some cases, different types of observability data may be stored in different specialized databases for performance reasons.
The choice of storage system will depend on the specific needs of the organization, but the key requirement is that it must be able to handle large volumes of data and make that data easily accessible to engineers for analysis.
After storage the final step is to analyze your data to gain insights into system behavior and identify issues. This might involve using visualization tools to generate graphs and charts that help engineers identify trends and patterns, using machine learning algorithms to automatically detect anomalies, and creating automations to take action based on observability data.
The 3 pillars of observability
The types of data used for observability have been branded the “3 pillars of observability” which are metrics, logs, and traces. In recent years some have started to believe that the 3 pillars aren’t enough. In this section you will learn about the 3 pillars and some ideas around what could go beyond the traditional 3 pillars to improve observability.
Metrics
Metrics are numerical data points that describe the performance and behavior of a system at a point in time. Some examples would be CPU utilization rates, memory usage, network traffic, response times, and latency.
Metrics are stored at regular intervals and are used for monitoring the performance of an app and for establishing baseline performance. Metrics can then be used to identify trends or anomalies in performance.
Logs
Logs are essentially records of events taking place in an application and can include things like warnings, errors, or just general information. Logs provide a historical record of what happens in an application and are an important part of diagnosing issues when they occur.
Traces
Traces are a type of data created and collected to track how requests move through an application. Traces are especially important for distributed systems or microservices where a single external user request may use multiple internal microservices.
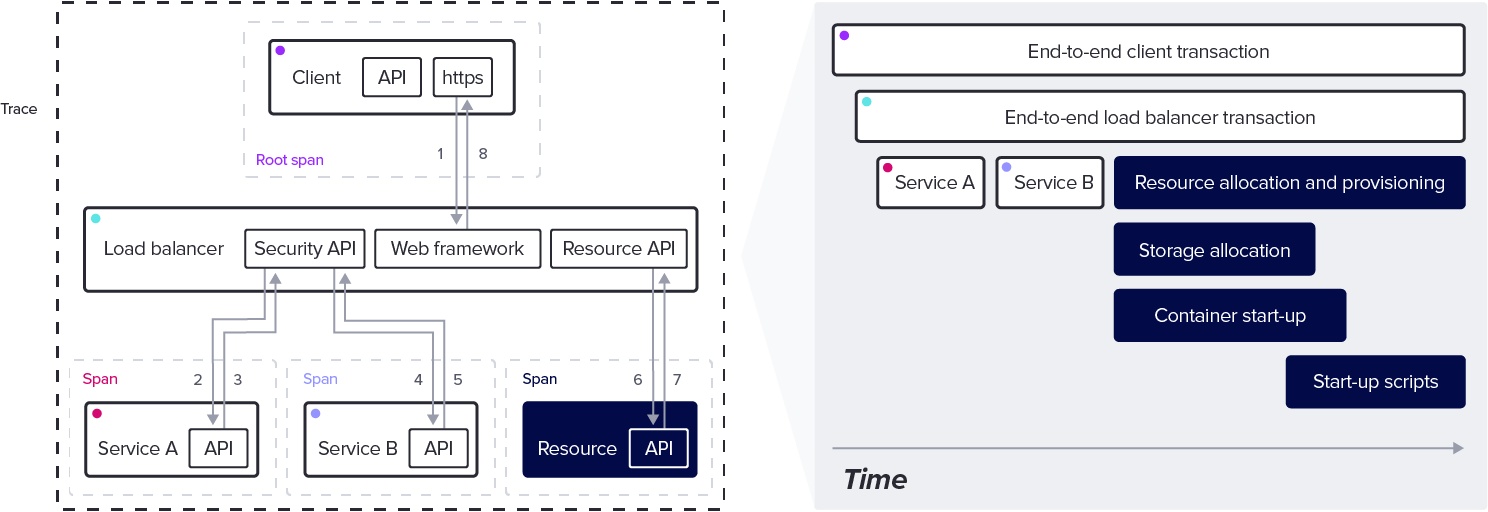
Traces allow developers to identify bottlenecks in performance and track end-to-end behavior of requests in a distributed system.
Beyond the 3 pillars of observability
A rising opinion among observability specialists is that the 3 pillars of observability are effectively overcomplicating things. At the end of the day the way to think about observability is that we simply need to track events as they are happening in an application and provide the proper context to make those events coherent and usable.
This is based on the core purpose of observability, which is to help developers make their software perform better and be more reliable. This means that developers need to be able to look at what is happening in their system and the best way to do this is with raw events that are attached to traces to give additional context.
What are the benefits of observability for software engineering?
Improve development speed
Observability can significantly reduce the time to market for software products by providing visibility into how different components interact within the system. By understanding the entire system and its dependencies, developers can quickly identify errors and bottlenecks that might otherwise take days or weeks to debug. This real-time insight into application behavior allows developers to make more informed decisions and take corrective action faster.
Analyze real-time business impact
Observability can help with real-time analysis for business impact by providing a comprehensive view of the system’s behavior and how users are interacting with newly deployed features. By combining this data with analytics, engineers and project managers can figure out which features users like and change their development roadmap accordingly.
Cost savings
With greater visibility into what is happening within an application, it’s easier for engineers to see where resources are being used and to focus on work that can drive the most impact. Observability data can be used to find where an application is technically working, but can be optimized to be much more efficient and reduce your costs.
Observability use cases
Debugging
One of the most common use cases for observability is debugging. When a bug occurs in a distributed system, it can often be difficult to track down the root cause. Instrumenting the code and collecting data on the system’s behavior by using observability platforms makes it possible to gain insights that can help to identify the cause of the bug rather than searching around hopelessly.
Monitoring
Monitoring software performance is another solid way to take advantage of the data being generated by software that has been properly instrumented. Monitoring is typically higher level and tracks a few critical aspects of software performance. Once a problem has been detected via monitoring, a more in-depth analysis can be done.
Capacity Planning
Observability data is useful for capacity planning. In order to ensure that a system has enough resources to meet future demand, you need to collect and store data on the system’s current utilization. This data can then be used to generate forecasts that can help to identify trends so proper resource planning can be done. This type of planning can help prevent potential unpleasant surprises when it comes to costs.
Cybersecurity
Observability makes it easier to keep your software secure. Observability data can be used to monitor for suspicious activity that might indicate an attempted attack on the system. Anomaly detection can be set up to detect potential issues in real-time, vulnerabilities can be detected before they are exploited, incident investigations are easier, and general incident response times will be reduced thanks to having instrumentation in place.
Performance optimization
By monitoring key metrics such as response times, error rates, and user engagement, observability can help identify areas where the software may be underperforming or where there are opportunities for optimization. Observability is particularly useful for distributed systems where identifying bottlenecks is even more difficult due to all the interacting components of the system.
Observability tools
InfluxDB
InfluxDB is an open source, column-oriented time series database that can be used to store all types of observability data with a single tool. InfluxDB supports SQL queries and integrates with a number of different visualization tools. It also has a variety of client libraries so you can query and work with your observability data using your favorite language and its ecosystem of libraries.
Prometheus
Prometheus is an open-source monitoring tool that allows developers to easily monitor their applications and infrastructure. Prometheus is highly scalable, providing detailed insights into application and system performance. It also offers alerting capabilities, allowing developers to quickly identify and address performance issues.
Grafana
Grafana is an open source visualization tool for creating beautiful visualizations of time series and other observability data. It allows developers to quickly and easily create interactive dashboards and graphs from their data. Grafana also offers alerting capabilities, allowing developers to stay informed of any performance issues.
Kibana
Kibana is an open source data exploration and visualization platform. It allows users to easily explore and visualize their data and create powerful visualizations. Kibana also integrates with other open source tools, such as Elasticsearch and Logstash, to provide additional insights into their data.
Jaeger
Jaeger is an open source distributed tracing platform. Jaeger provides detailed insights into application and system performance and has visualization features to look at and analyze spans and traces.
OpenTelemetry
OpenTelemetry is an open-source project that provides a set of APIs, libraries, agents, and collectors for generating, collecting, and exporting telemetry data from applications and services.
OpenTelemetry provides a standard set of APIs for instrumenting applications, which makes it easier to adopt and integrate with other observability tools by eliminating potential vendor lock-in. The project is backed by a large, active community of developers and companies which ensures the project will be supported long term.
FAQs
What is the difference between traditional monitoring and observability?
Observability is a newer concept in software monitoring, and it offers a more comprehensive approach than traditional monitoring tools. Observability Tools focus on providing visibility into all aspects of the system in order to identify issues and enable rapid resolution. This is particularly important in microservices architectures, where there are many moving parts and it can be difficult to identify the source of issues. Observability tools work by collecting data from all parts of the system and providing a unified view that makes it easier to spot problems.
By contrast, traditional monitoring tools tend to focus on a specific area of the system, such as the network or the database. This can make it harder to identify issues, as they may not be apparent in one area but might be visible in another. observability provides a more holistic view of the system that can help to identify problems more quickly and resolve them more effectively.
How is observability related to DevOps
Observability and DevOps are closely related concepts that help achieve the same goals. DevOps is focused on making sure software is developed and deployed efficiently and observability helps to achieve that goal.
Here are a few specific examples of how observability can help with DevOps
-
Observability data helps to achieve continuous feedback by providing insights on how a new deployment impacts key metrics
-
DevOps deployment pipelines can use observability in staging or production environments to determine potential issues early and automatically rollback a deployment if necessary based on the data being received. The additional context provided by observability data can allow for more reliable automation to be built as well.
-
Because observability data is focused on how the entire application works, it makes collaboration between teams easier because they can see how their deployments impact other teams and services in the application.
How is observability related to cloud native?
Observability is especially important for cloud native applications due to the nature of their architecture. Because cloud native software often uses microservices, the ability to see how they interact using observability data is critical.
Cloud native applications usually take advantage of things like containers for deploying software and tools like Kubernetes are used to manage those containers. Observability data can be used to monitor the health of those containers and track overall resource usage across the system. This data can be used to ensure the application is working properly in the short term and in the long term help with optimizing the app to reduce costs and improve overall performance for end users.
What are the origins of observability?
Observability in software engineering is a concept that originated in control theory, a field of engineering that deals with the behavior of dynamic systems. In control theory, observability refers to the ability to infer the internal state of a system based on its external outputs, even if the internal state cannot be directly measured. This concept was later adapted for use in software engineering, where it refers to the ability to understand the behavior and state of a complex system by analyzing its external outputs, such as logs, metrics, telemetry data, and traces.
By collecting and analyzing data from these external outputs, software engineers can gain insight into the behavior and health of a system, and diagnose and resolve issues quickly and efficiently. The application of observability principles to software engineering has become increasingly important as systems have grown in complexity, making it more difficult to diagnose issues and maintain reliability without the aid of advanced tools and techniques.

