7 predictions about the technology industry and developer tools in 2017
By
Paul Dix
updated April 11, 2024
Company
Developer
Navigate to:
Predictions about the tech industry generally aren’t worth the bytes they cost to send over the Internet, but I figured it would be fun to make some of my own anyway. So here are seven predictions about some things we will and won’t see in 2017 with a few thoughts about why I think each could be accurate.
Go will continue its rise as a dominant server side programing language
In 2013 I predicted that Go would take over as a dominant server side language eclipsing Scala, Node.js, and potentially, eventually Java. That rise over the last 3.5 years has continued and doesn’t seem to be losing any steam. I wondered briefly if the introduction of Rust 1.0 would make a dent in Go’s adoption, but it hasn’t seemed to matter. Go remains an attractive language because of its readability, performance, robustness, tooling, and gentle learning curve.
We’ll see the release of Go 1.8 with dynamically linkable shared libraries and significant improvements to latencies due to garbage collections. The Go team keeps cranking out quality releases that improve the features, performance, and tooling. Their consistency is amazing and it will continue to drive more adoption of the language as a tool of choice for large code bases and production workloads where readability, robustness, and performance matter.
The entire TICK stack is written using Go and we’ll continue to test and build with the new Go versions. For instance, an upcoming version of Telegraf, our data collector, will use the shared libraries functionality in Go 1.8 to enable experimental and external plugins.
Kubernetes will continue its steep popularity climb with no apparent peak in sight
KubeCon, the conference on Kubernetes, had over 1,000 attendees this year, up from 300 last year. It continues to see massive adoption. As an additional datapoint, we’ve seen growth of an older version of InfluxDB that we attribute directly to growth of Kubernetes deployments. We track usage statistics for the various versions of InfluxDB and while all older versions have declined in usage as new versions came out, we’ve seen a rise in one particular version:
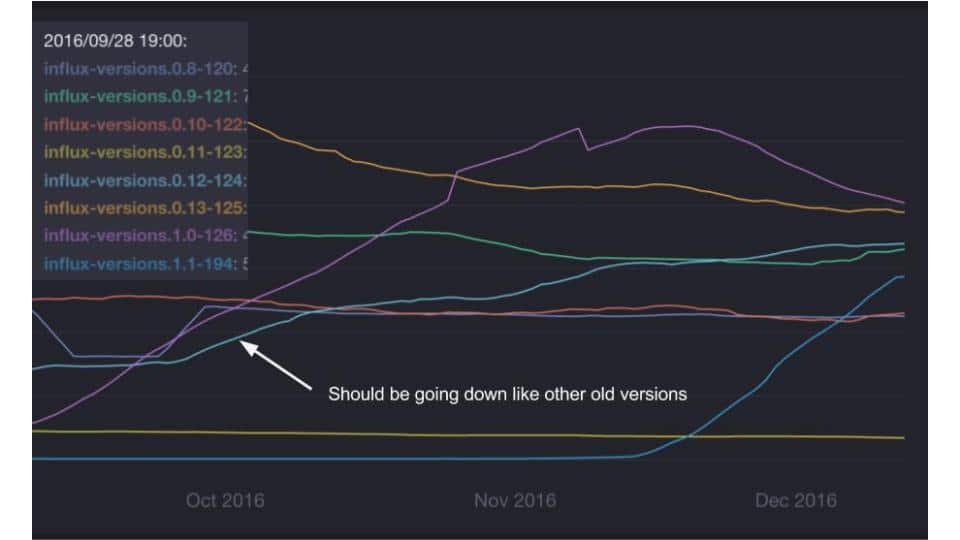
In the image above we’re tracking the growth and decline of various InfluxDB versions over a three month period of time. You can see older versions decline as the newer ones get introduced. For example, the blue line that starts rising in the middle of November is when we released version 1.1.
All the older versions are in decline as expected except for version 0.12, which continues to rise in popularity despite it being eight months old. We found out that Heapster, the project for instrumenting Kubernetes deployments used InfluxDB version 0.12 by default. We saw an increase of around 4,000 InfluxDB servers running in the wild over a three month period, which we think is attributable to usage within Kubernetes.
RedHat is betting on Kubernetes with OpenShift and many major industry players and new startups seem to be lining up behind Kubernetes. My prediction is that Kubernetes will be larger than the OpenStack community in a short amount of time due to its applicability in the cloud, on bare metal, and within OpenStack deployments.
Serverless hype will take off
Serverless computing, like AWS Lambda, has already taken off, but I expect the hype cycle to increase over the next 12 months. With Amazon Lambda, Azure Functions, and Google Cloud Functions, all three major cloud players have serverless frameworks in place and they’ll continue to invest and innovate on them. Developers will be attracted by the possibilities of cost savings, effortless scale out architectures, and zero DevOps ownership.
However, I think the major obstacle for serverless to overcome in the next 12 months will be on developer productivity and usability. For new projects to pick up serverless architectures, it must be easy to iterate on product. This is because the biggest risk with most new projects is that you’ll build something nobody wants, rather than build something that doesn’t scale. In the early days of most projects, scale isn’t a problem.
This is why developer productivity is the most important metric early on. It’s why Ruby on Rails achieved such great adoption. It wasn’t as scalable as Java, but it made developers massively more productive. For serverless to really take off, we’ll have to see the rise of a framework (maybe Serverless?) to lend productivity and usability to the cloud vendors’ platforms.
Optimizing for developer happiness, productivity and lowering their time to value is part of our product DNA and what we strive for with every new product and release. So I’m really just pitching our own book, but I think those are the key goals for serverless architectures to achieve over the next twelve months.
AI and deep learning hype will continue, but fail to deliver
The hype around artificial intelligence, deep learning and machine learning will continue unabated. I think there’s a bubble here, but it doesn’t show any signs of popping in the next 12 months. Mainly because the investments in the area are so early I don’t think enough of them will flame out to deflate the bubble. That paired with continued acqui-hires driving modest gains in AI related investments without those companies ever having to deliver functional or commercially viable product.
Investors will continue to pour money into any team with a strong academic background in deep learning techniques. However, I don’t think any of these will pay off in the big way investors are hoping for. Mainly because machine learning researchers haven’t crossed any new event horizon on the understanding of intelligence and learning. The techniques in use have been around for a while. We’re now just throwing GPUs and more data at the problem. No new fundamental understanding has been achieved to drive this kind of hype.
Ultimately, these techniques can be applied to solve tightly scoped problems like speech recognition, facial recognition, and some degree of self driving cars. However, these brute force techniques won’t yield a generally adaptable intelligence. We’ll continue to get slightly improved software usability and responsiveness, which will help with human-computer interaction, but won’t give us a real Iron Man style AI like Jarvis.
However, developers will be able to use the already existing techniques to start stringing together interesting product enhancements and potentially new products. It will be interesting to watch this develop and see if we end up heading into another AI winter.
MR/VR hype will reach its peak and head for the trough of disillusionment
As MR (mixed reality) and VR (virtual reality) units ship to developers the hype will reach its peak as everyone realizes that there’s still much more to do to reach the nirvana of a new paradigm of human computer interaction. The hype around VR and MR is that they’ll lead to an all new way to interact with computing devices like the introduction of the mouse and the graphical user interface, or touch screens on smart phones (i.e. iPhone).
The Magic Leap hype bubble already appears to be deflating and VR headsets are still giving some users motion sickness. There’s more work to do before we get to a completely new computing paradigm that is applicable for more than just select entertainment. For now the uses cases will be relegated to games and gee-whiz applications.
I’m excited about what happens after the trough when second and third generation systems become available. We could have all new applications for collaboration, communication and delivering a computing experience that is higher bandwidth both in terms of how we interact with our computers, but also in how we interact with other humans.
Developers will spend next year learning about the new interfaces and programming for them. We’ll probably see an explosion of applications that outpaces their actual demand on the platforms, resulting in the trough.
IoT will continue to be fragmented, but an exponential expansion of sensor data will continue
IoT, or Internet of Things, is a very fragmented market right now. The catch all phrase can be used to refer to industrial historians in use in factories and oil and gas wells, but it’s also used to refer to home automation, wearable devices like Fitbit, inventory tracking in retail, and fleet and automotive tracking among many others. It doesn’t seem that these many different use cases of sensor data are going to coalesce around a standard within the next 12 months, which means market will remain fragmented from a solutions point of view.
However, that won’t stop many retailers, manufacturers, building companies, software startups, hardware makers, and many others from forging ahead and instrumenting all of their equipment with sensors to track every conceivable measurable trait. The exponential expansion of data, specifically sensor data, will continue unabated during the next twelve months. The challenge will first be how to ship, store, and manage all this data. Then we’ll have to figure out how to mine insight from it.
Tracking sensor data over time is a key use case for InfluxData so we’ll be working with customers and users to try to help solve scaling and insight problems. There’s definitely more work to do to enable the sensor driven future, but it’s coming like a freight train. One festooned with tens of thousands of sensors.
We'll see some good tech IPOs
2016 was a bleak year for the tech IPO market. It looks like 2017 may be a little better as long as the market doesn’t completely tank with the new president coming in. Forbes has a list of 7 likely candidates that would drive huge IPOs.
Conclusion
2017 will be an exciting year for the tech industry and I’m sure there are many other twists and turns that I haven’t covered or don’t see coming. There’s never been a better time to be a software developer and it looks like 2017 will continue the trend.
