Table of Contents
I’m excited to announce that today we’re launching the open beta of our InfluxDB 2.0 Cloud offering. This cloud release contains everything released in the open source alpha 9 of InfluxDB 2.0, but in a fully managed and hosted product. While our InfluxDB 1.x Cloud offering was a managed database service like RDS, the InfluxDB Cloud 2.0 service is more like a time series database, dashboarding, analytics, monitoring, and serverless Flux system all rolled into one. It’s designed to be multi-tenanted, which gives us the ability to offer a free tier to all users. Even better, it will offer usage-based pricing, eliminating the need for customers to size ahead of time what instances, storage, or memory they’ll need. InfluxDB 2.0 Cloud will scale up with your needs and you’ll only pay for what you use. In this post I’ll cover what to expect in the beta period, what features we will have in the coming weeks and months, and how the pricing model works.
Beta period and examples
During the beta period, we’re limiting everyone to the free tier usage limits. It’s not meant for production usage, and at this early stage things could break. But we thought it was important to get this out sooner rather than later to iterate with the community. Feedback on InfluxDB Cloud feeds directly into what we develop for InfluxDB 2.0 Open Source as well.
Despite the limits, you should be able to collect server, service or any kind of data through Telegraf, our data collection agent and send that to our cloud. We anticipate that you’ll be able to send data from around 10 separate Telegraf agents collecting on a 10-second interval, data retention is limited to 72 hours, and query throughput is limited to around what one user with a real-time dashboard would produce. We also have officially supported client libraries for Javascript and Go with other languages coming soon. If you hit your limits, you’ll be prompted in the user interface and sent an email. You can request an increase, but we’ll want to hear from you to find out more about your use case and what you think of the service.
You should be able to get up and running in a few minutes. You’ll have to verify your email address, pick your cloud provider and region (only AWS US West for now), and agree to our beta terms, but after that you should be free to go without a credit card or anything else. Here’s an animated gif of creating a Telegraf config, which you can then pull from any Telegraf agent you have on your own servers:
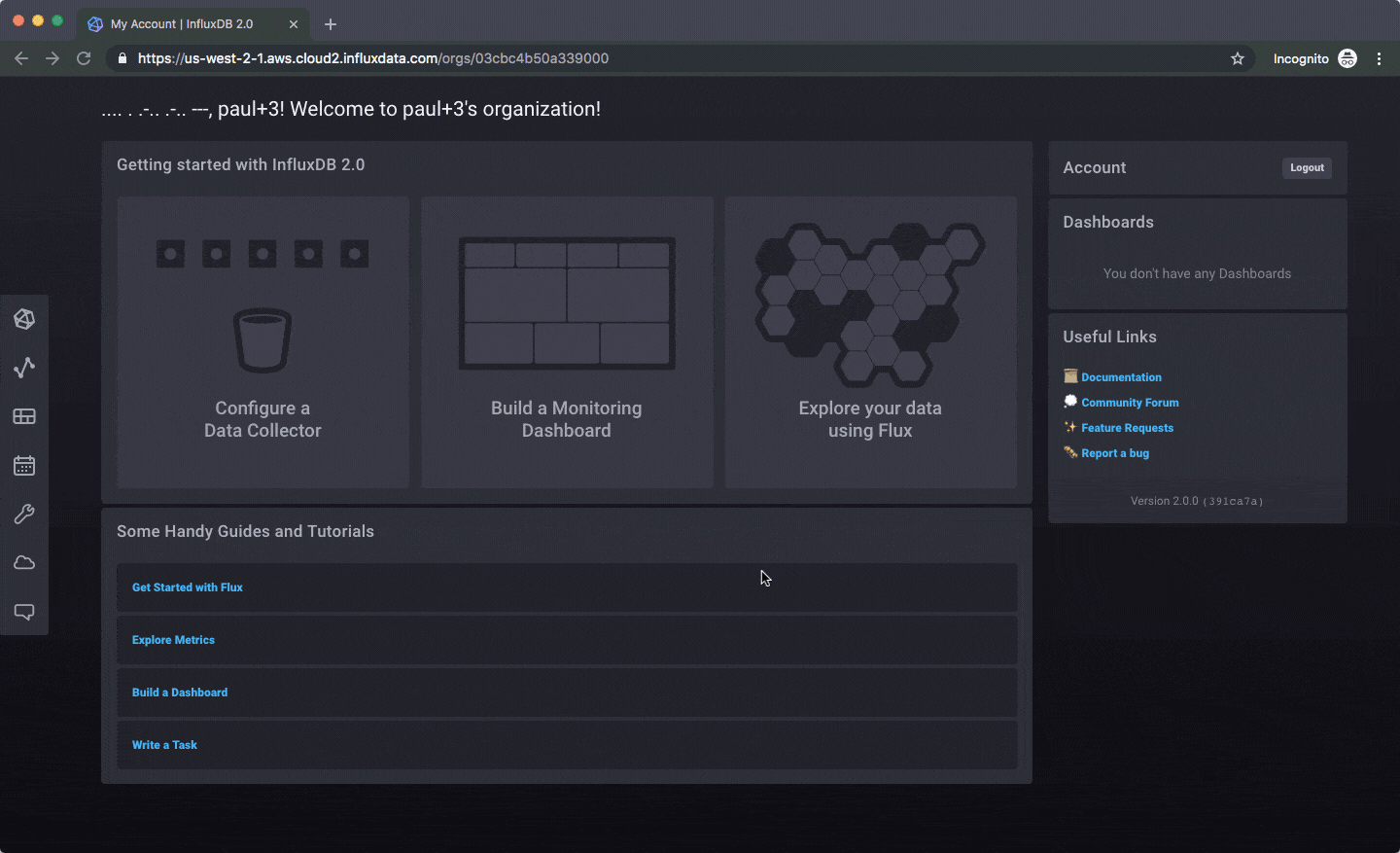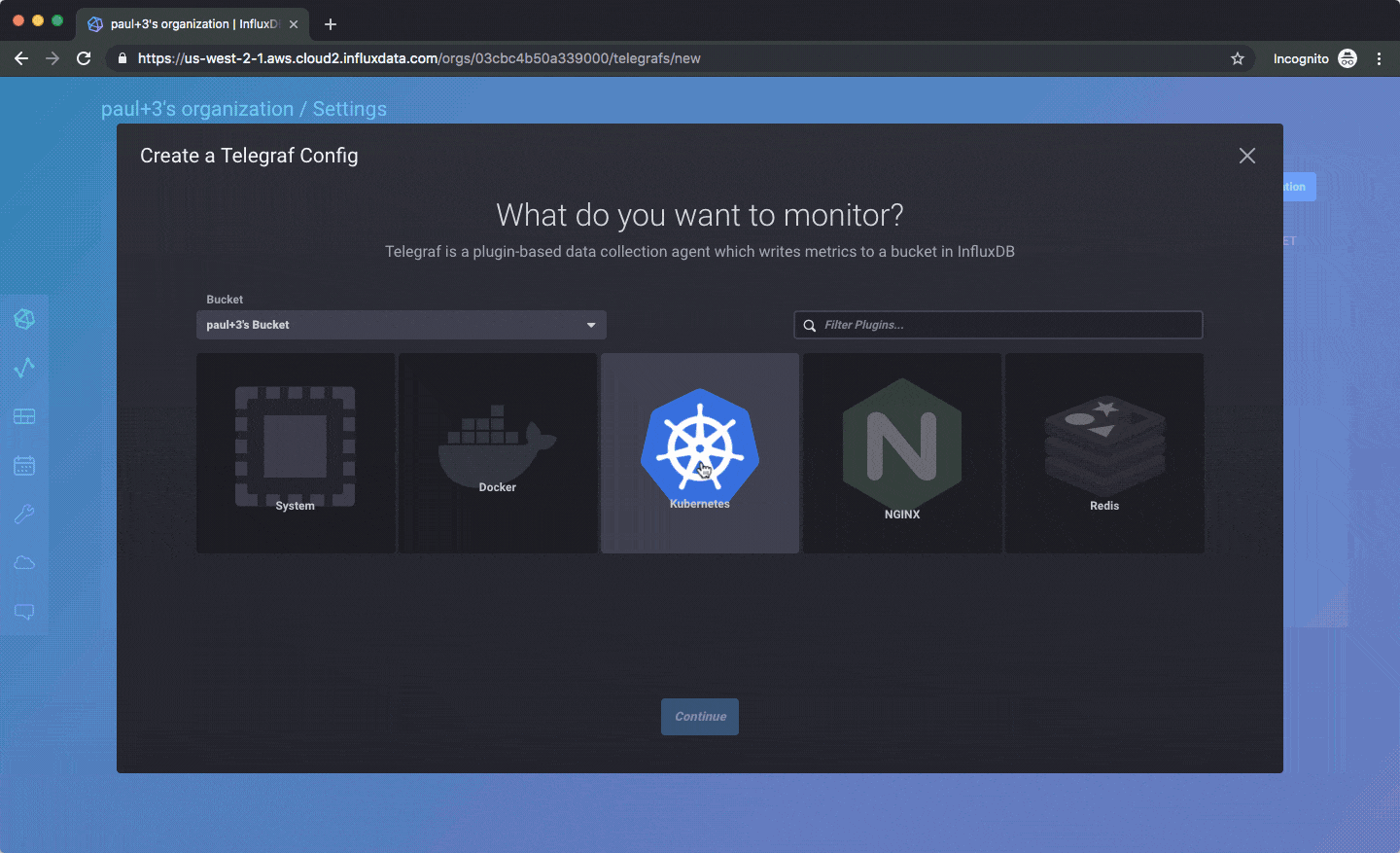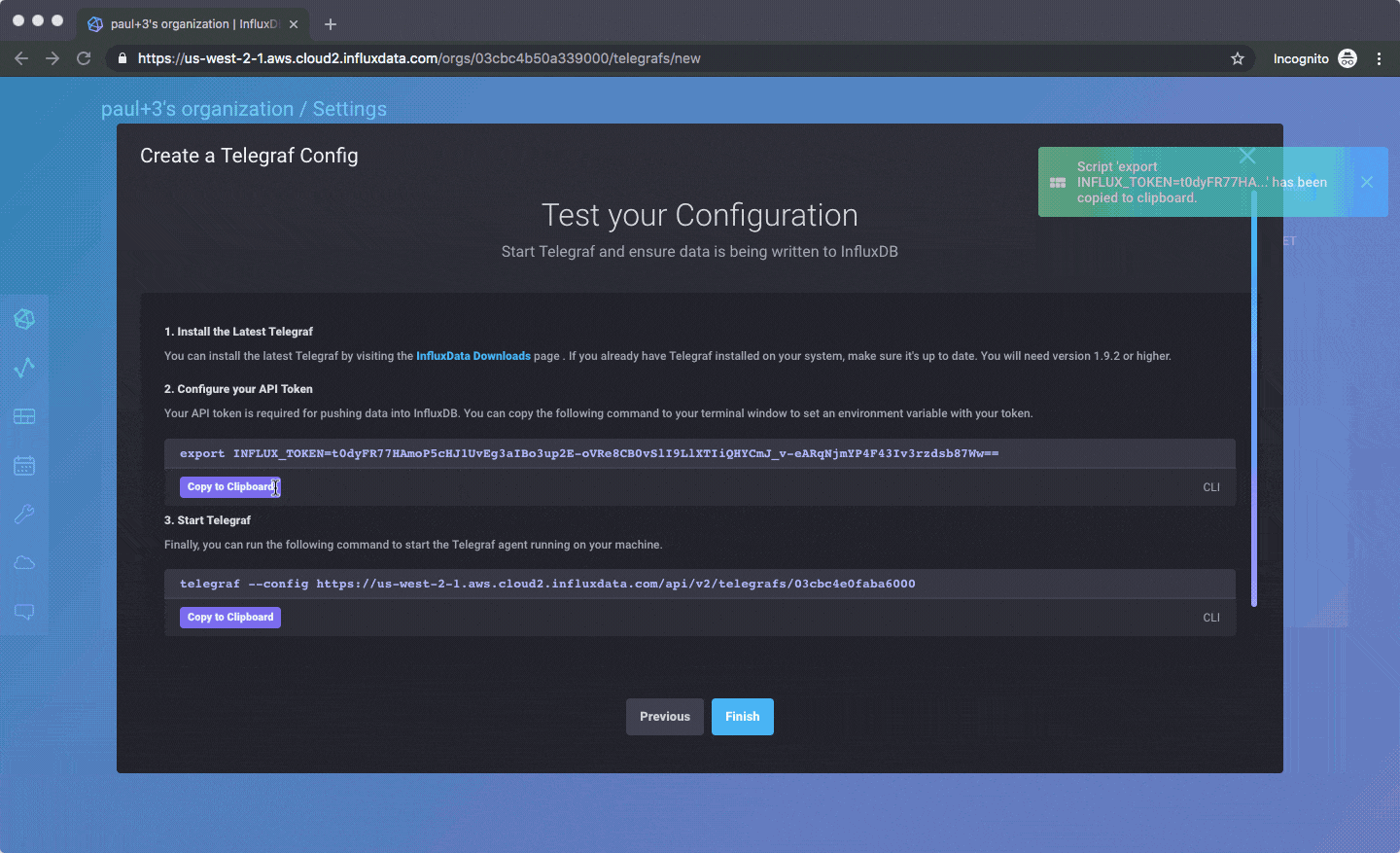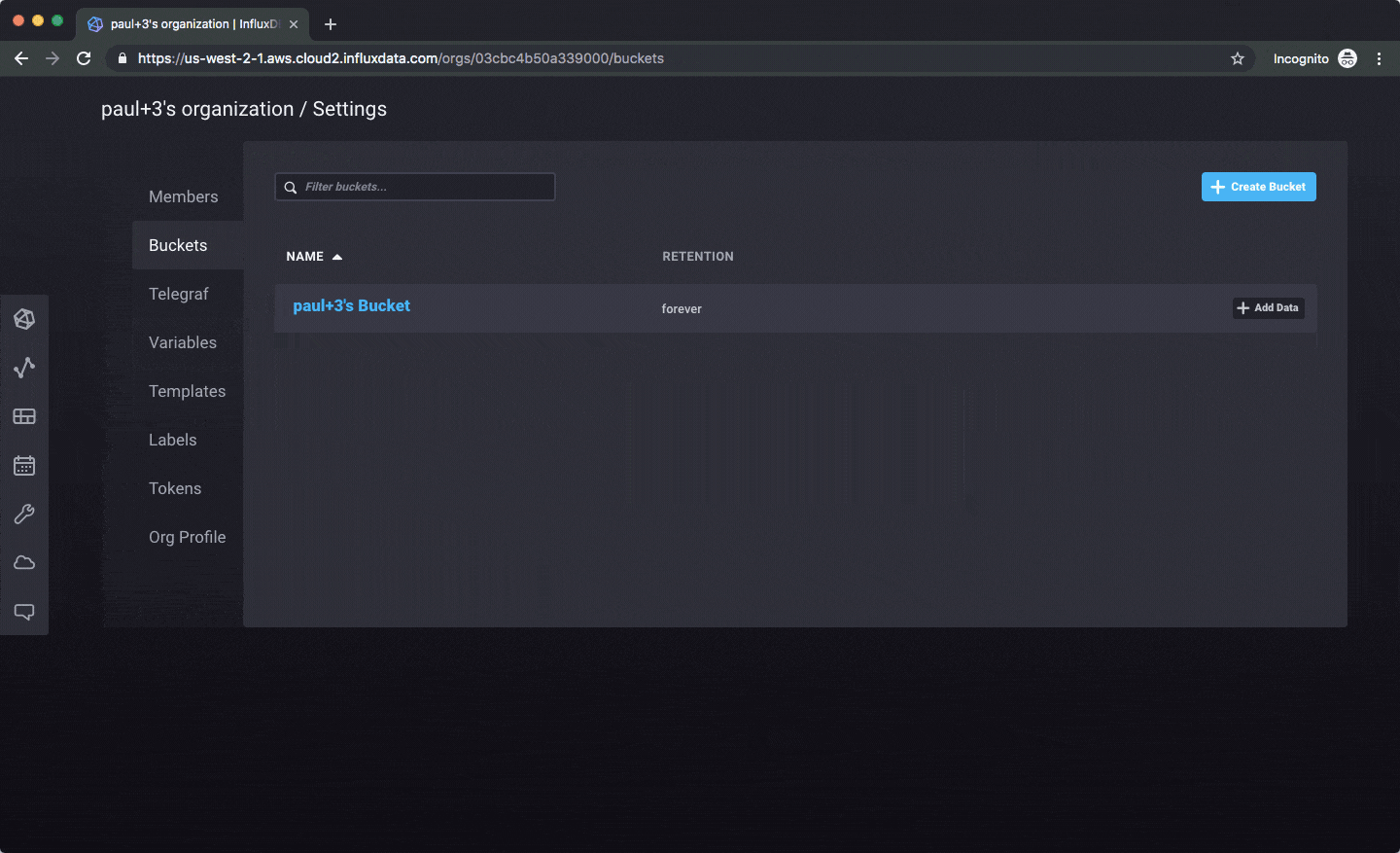
Here’s how you’d create an API token for use with a client library:
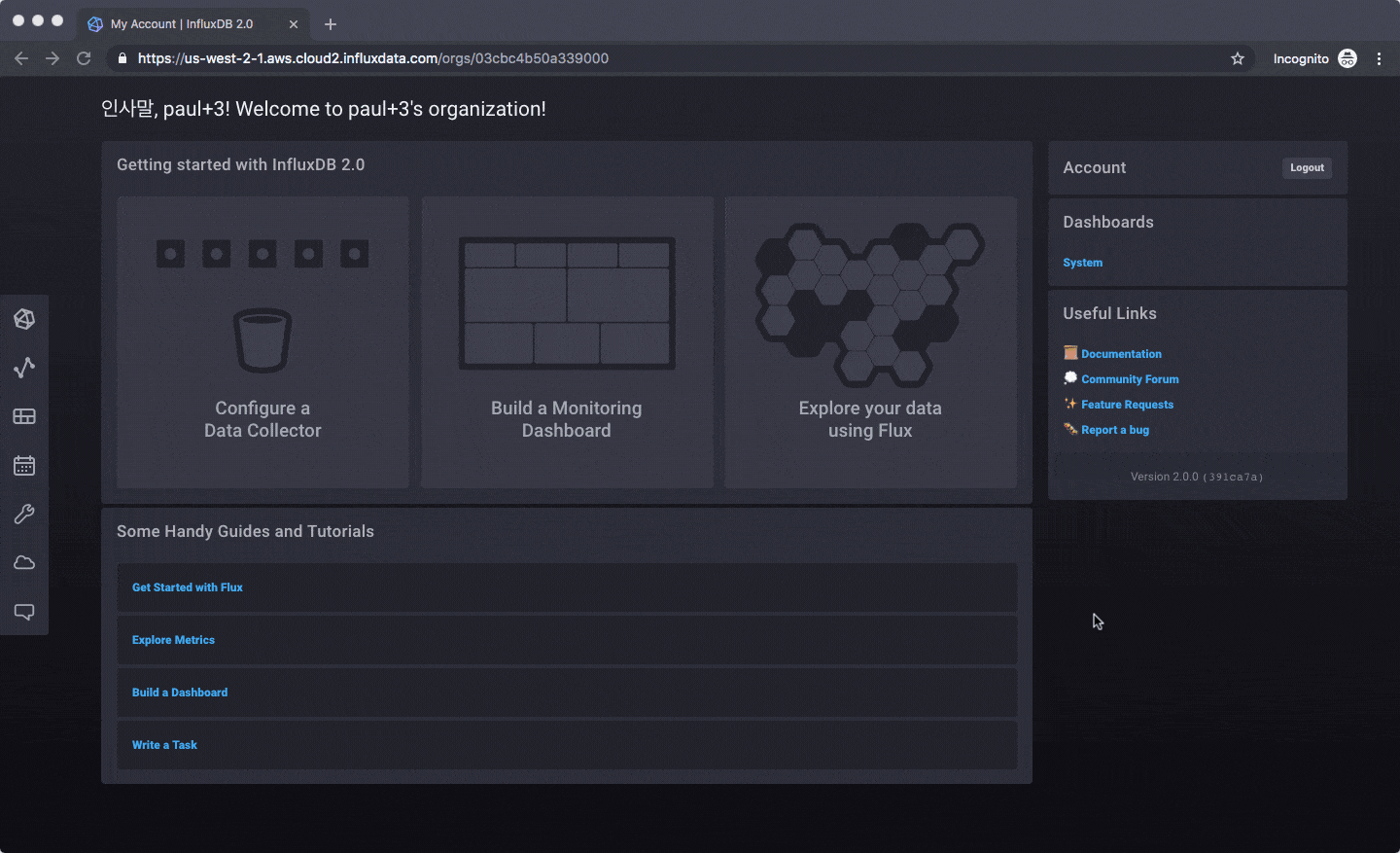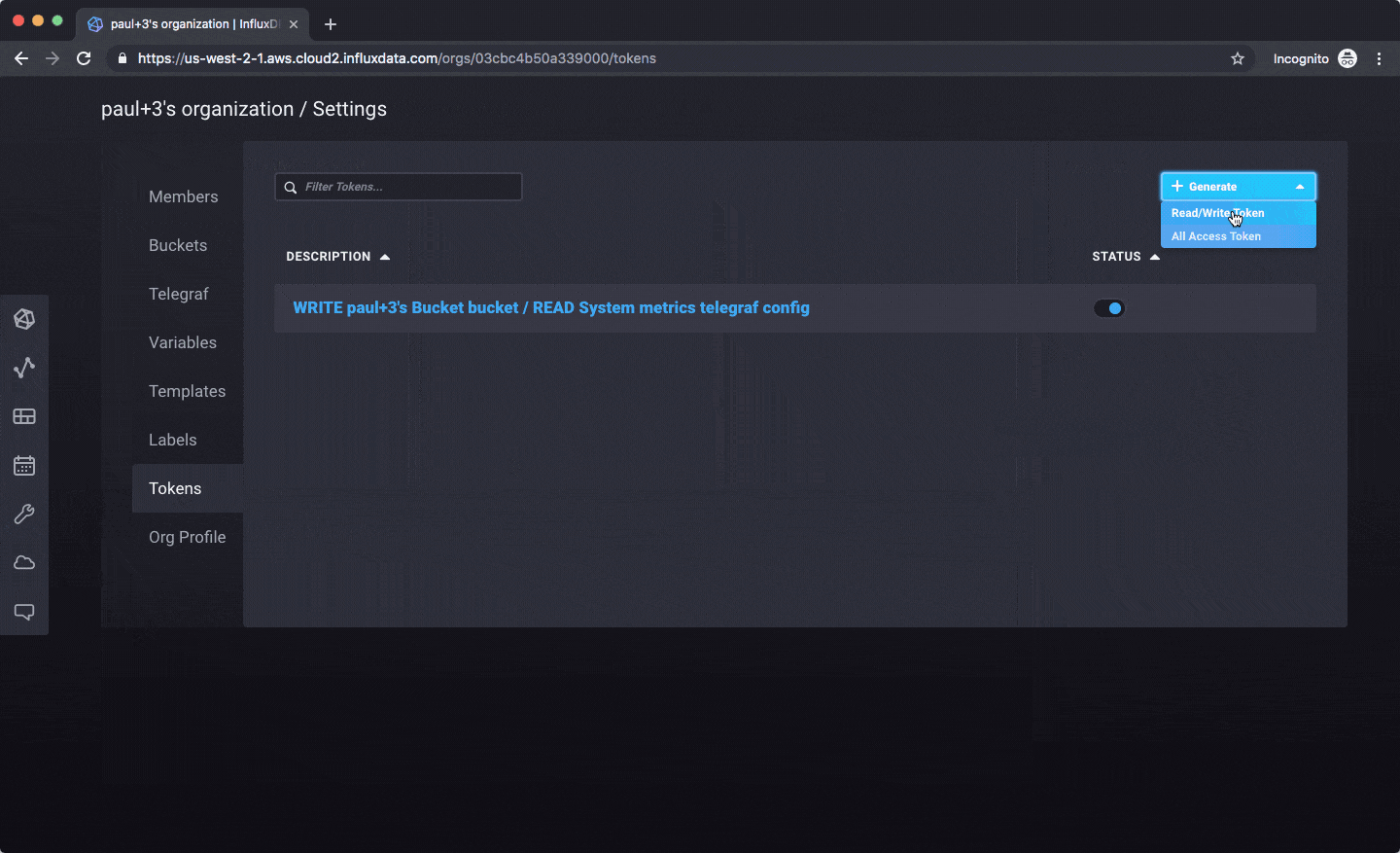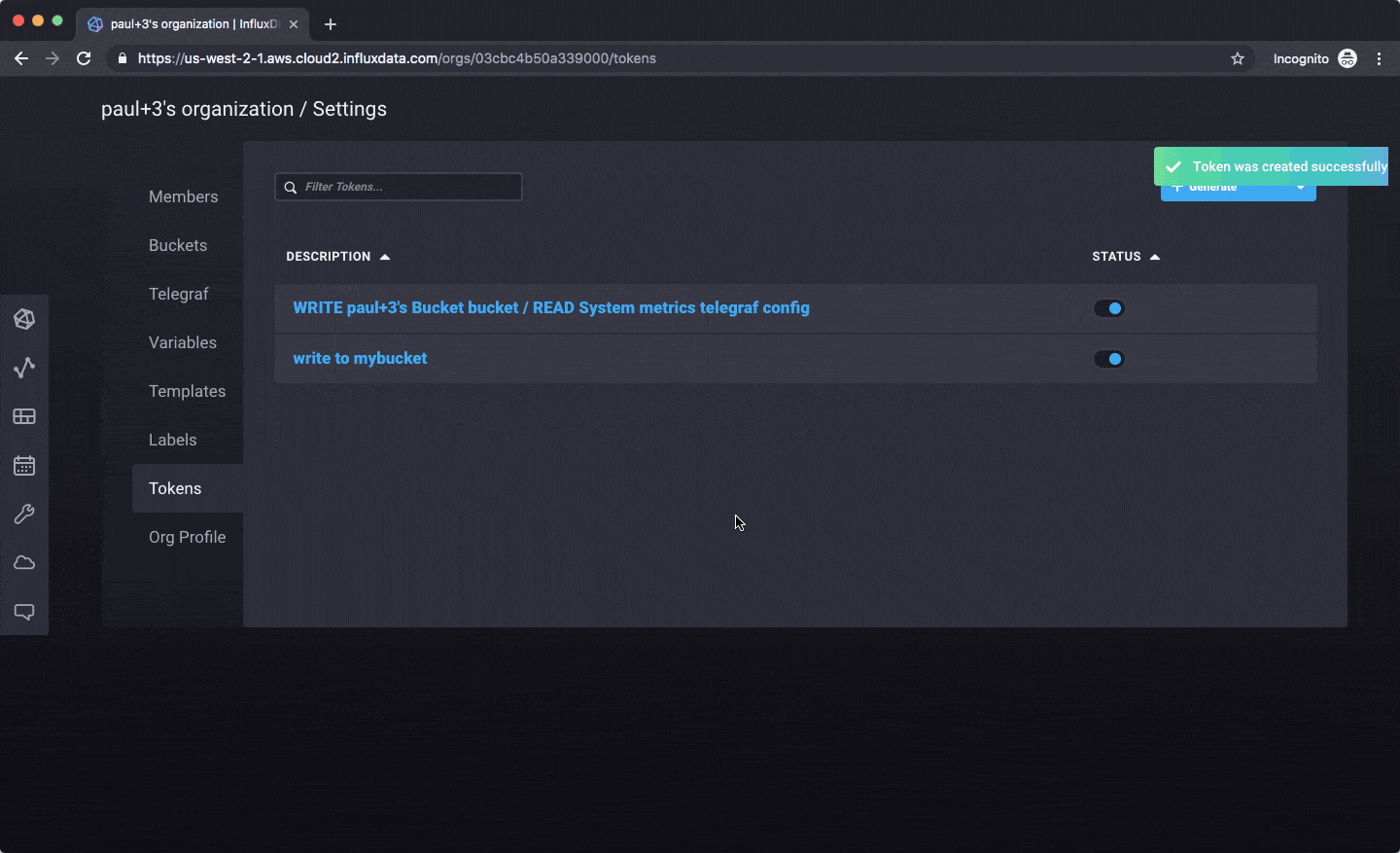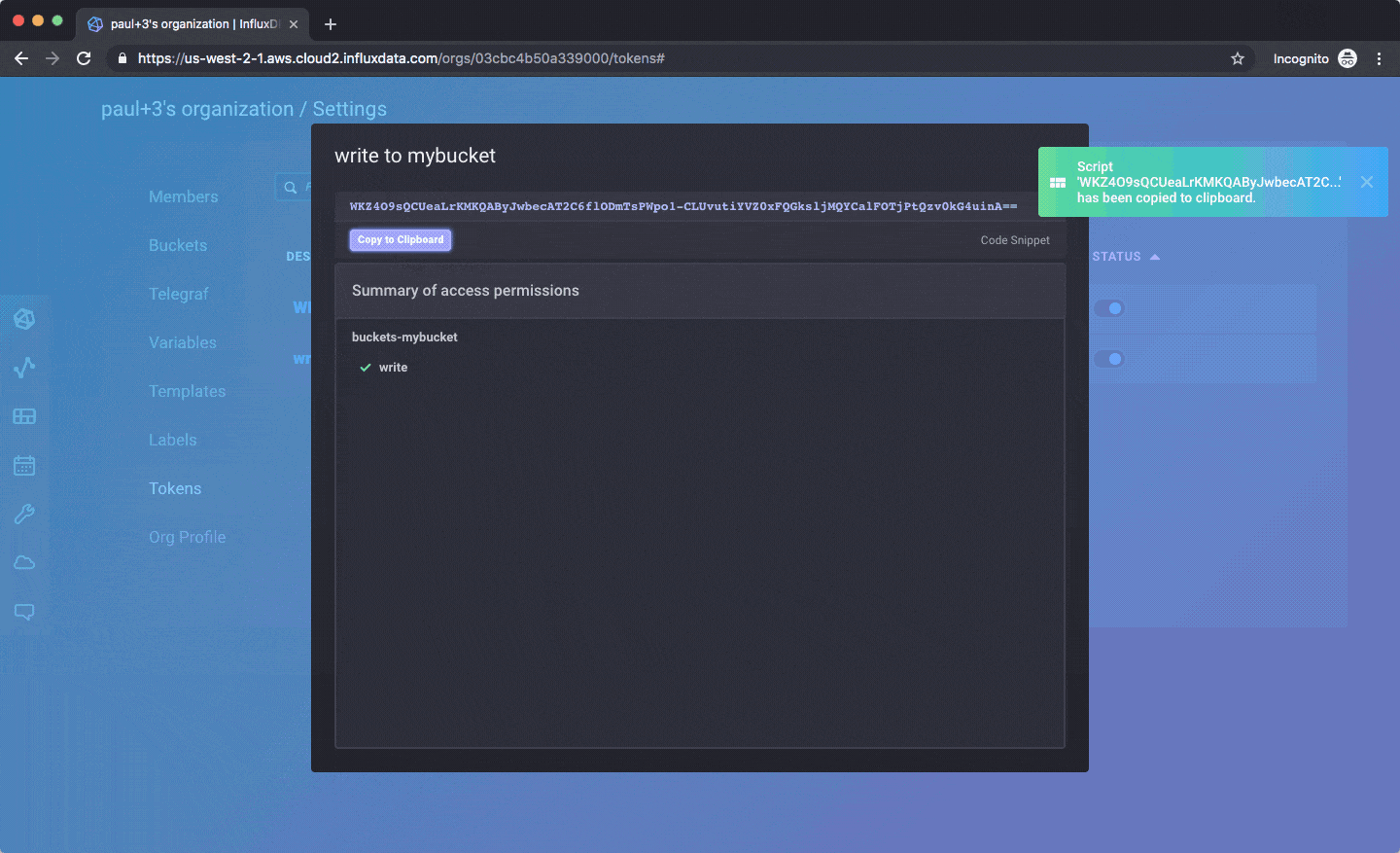
Once you have a token, you can write data or access the API using our officially supported client libraries. You can find the InfluxDB 2.0 Javascript library here or using the HTTP API with other libraries coming soon.
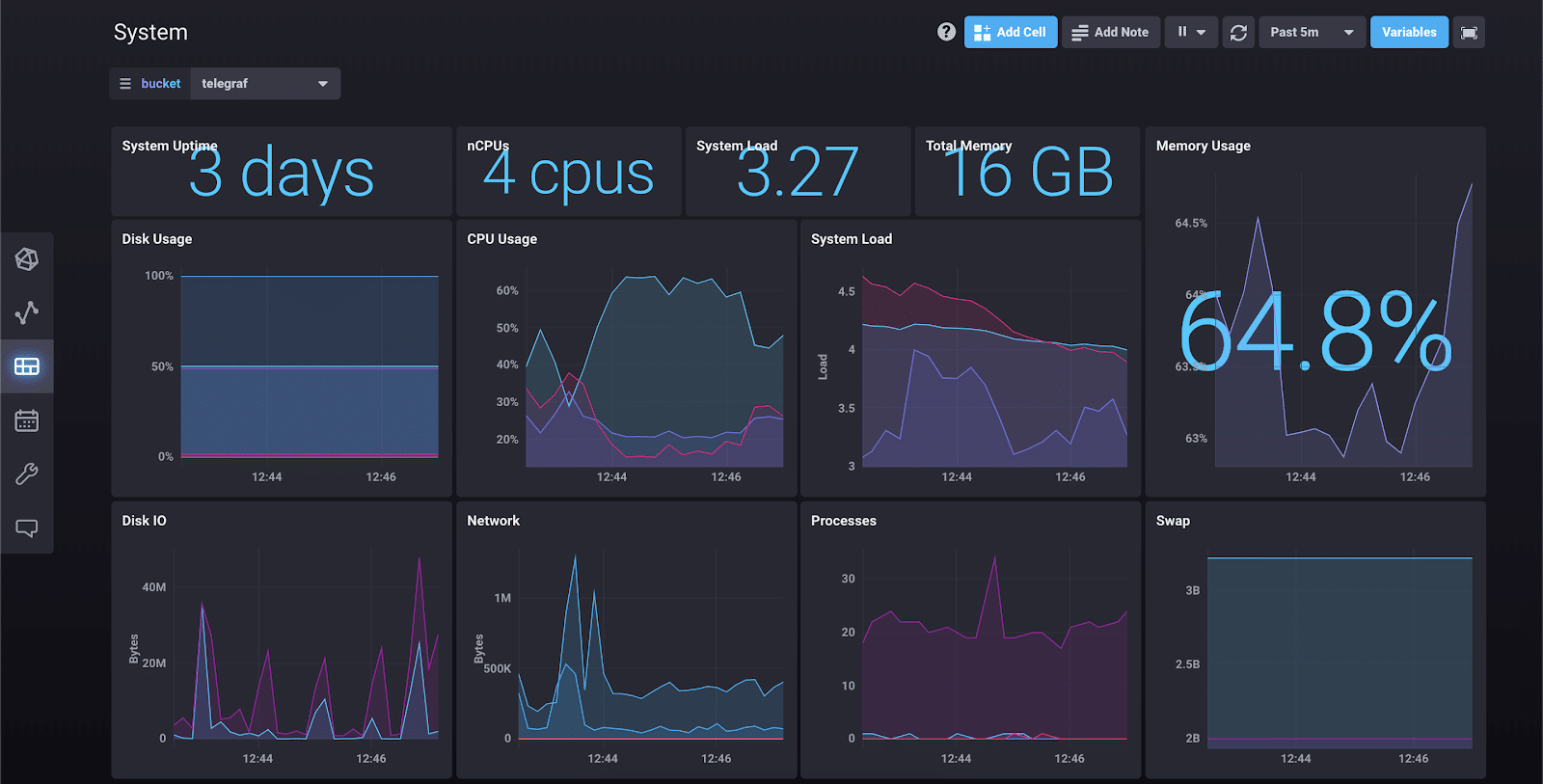
Once you’re writing data in, you can explore that data as a graph, a table, or write raw Flux queries to work with it.
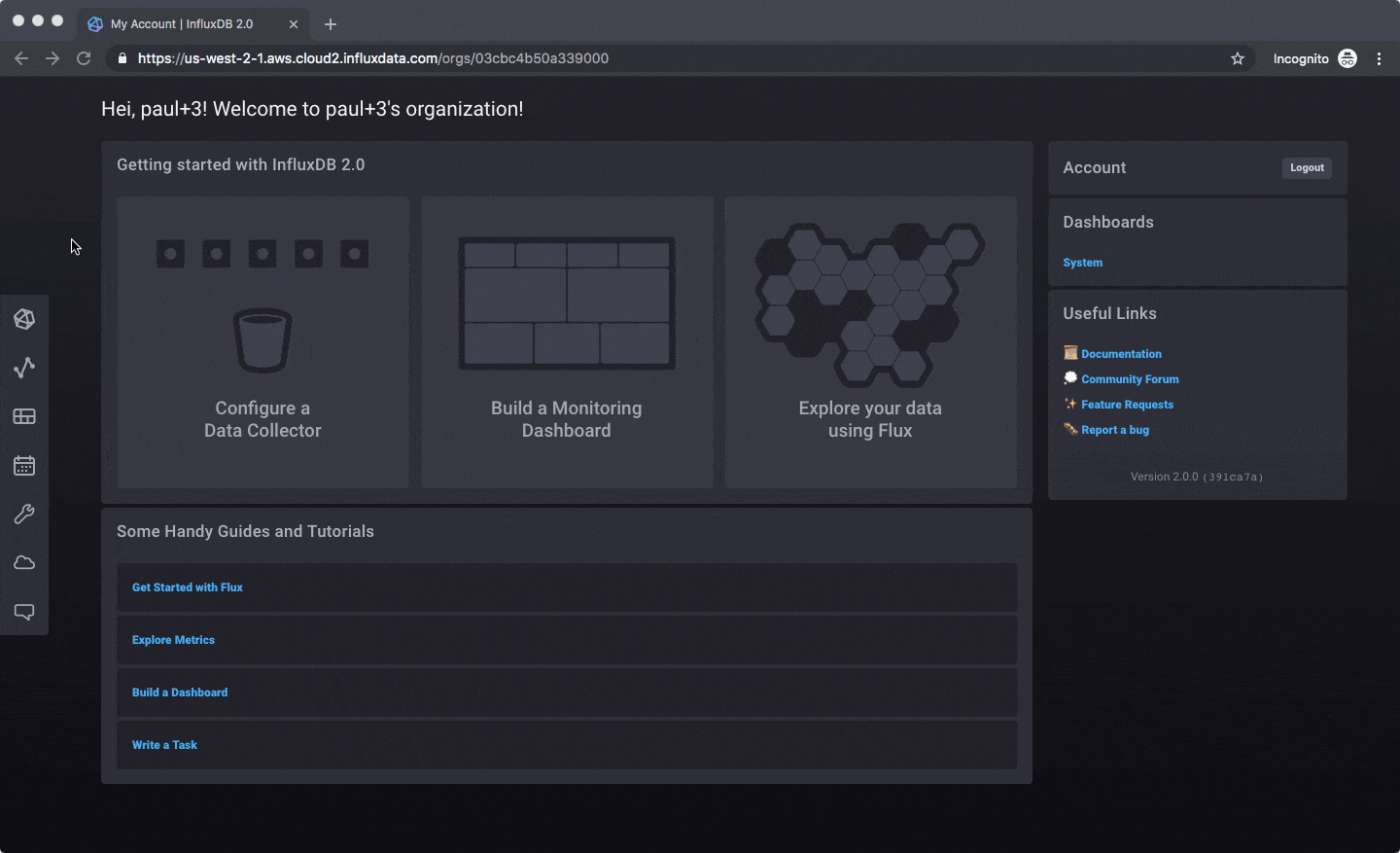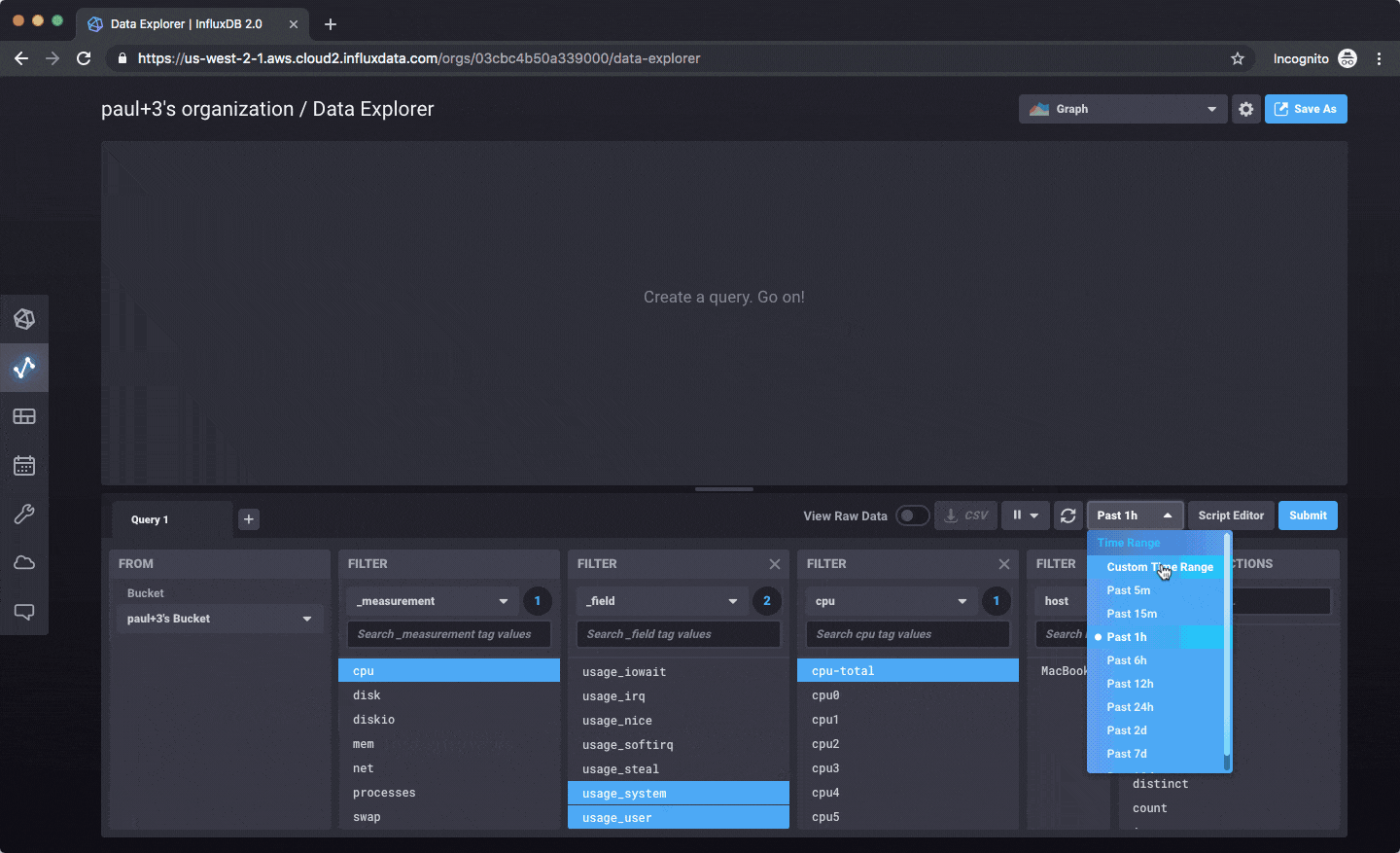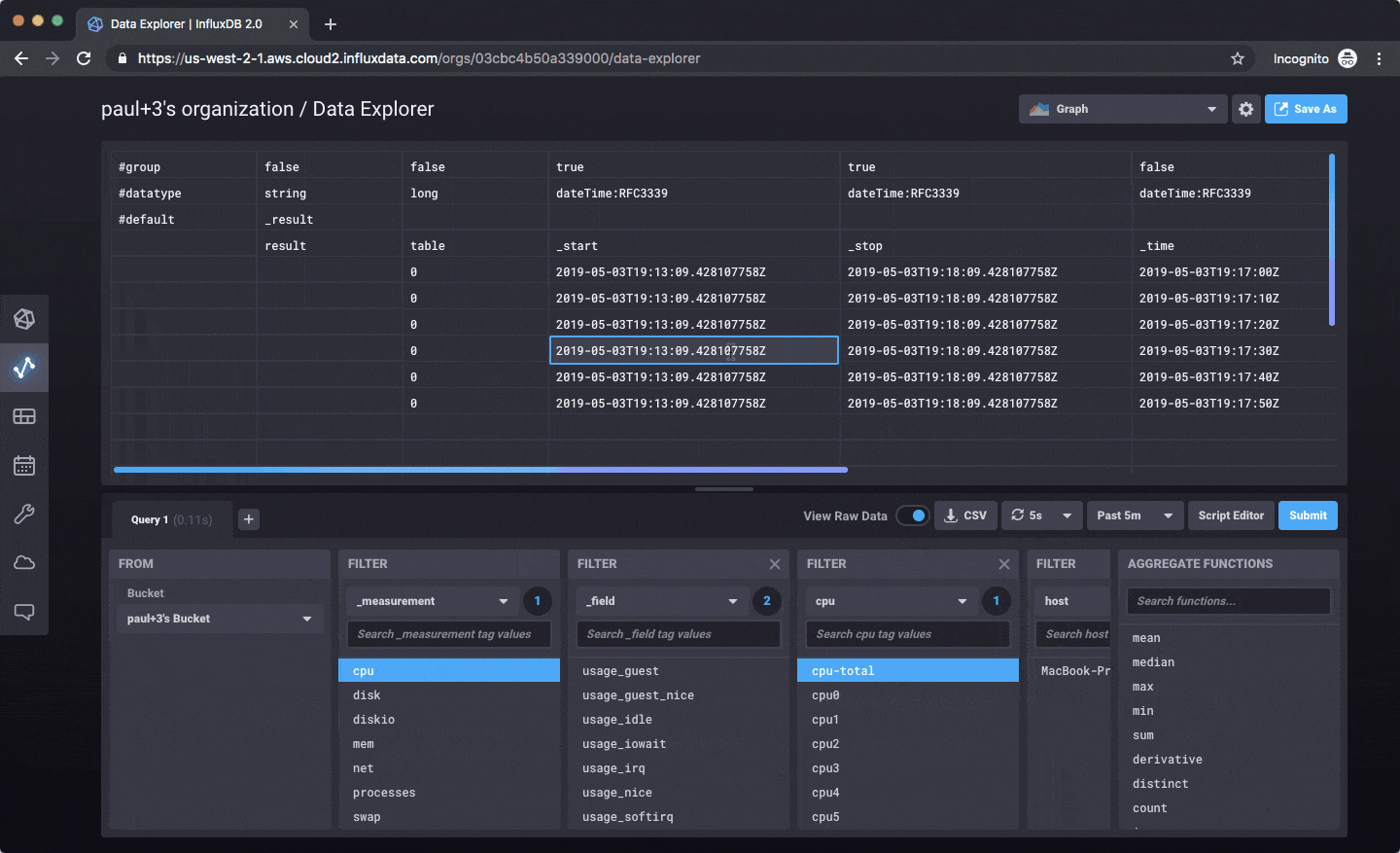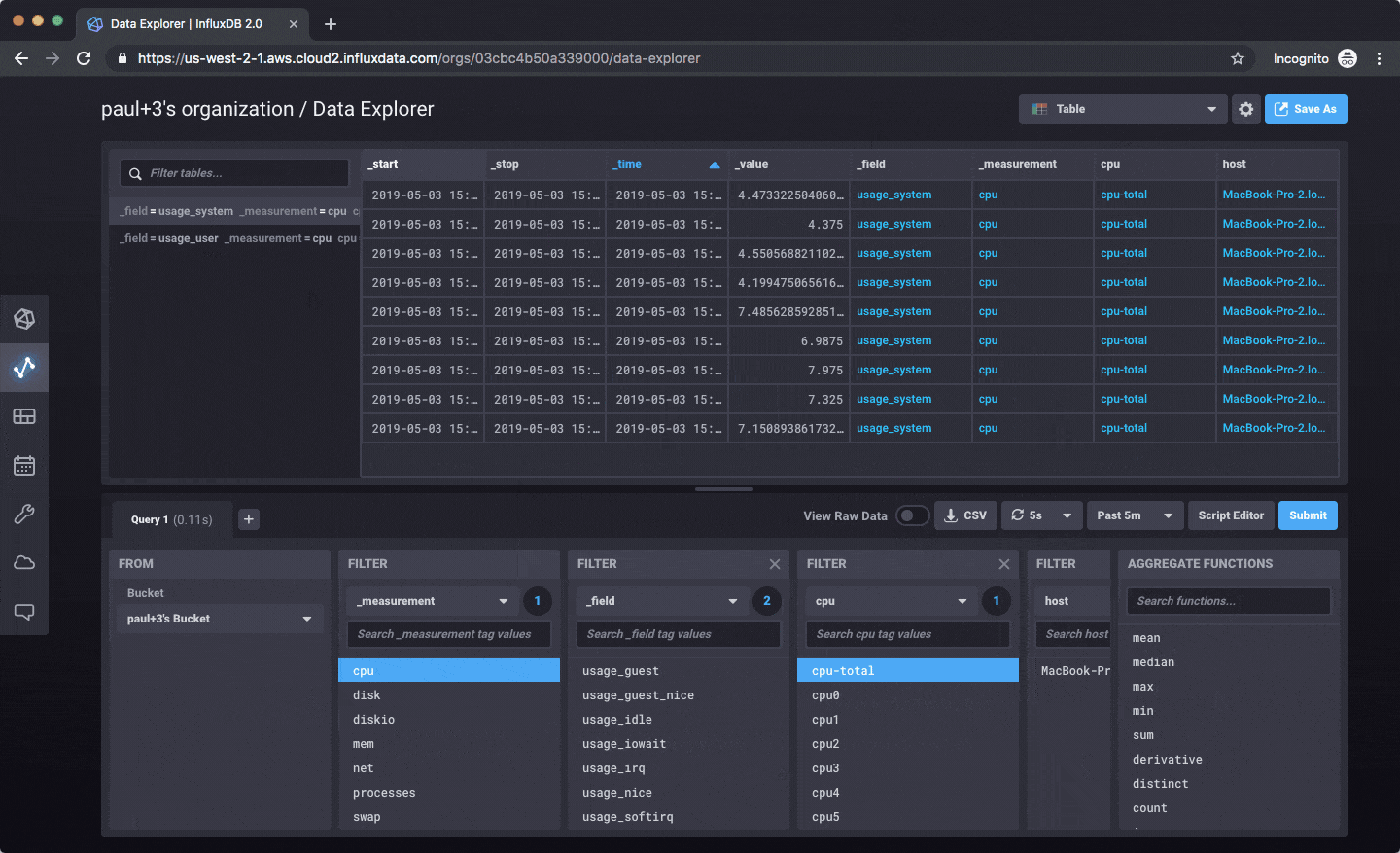
Right now everything is focused on writing data, querying, exploring, and dashboarding. Here’s an example:
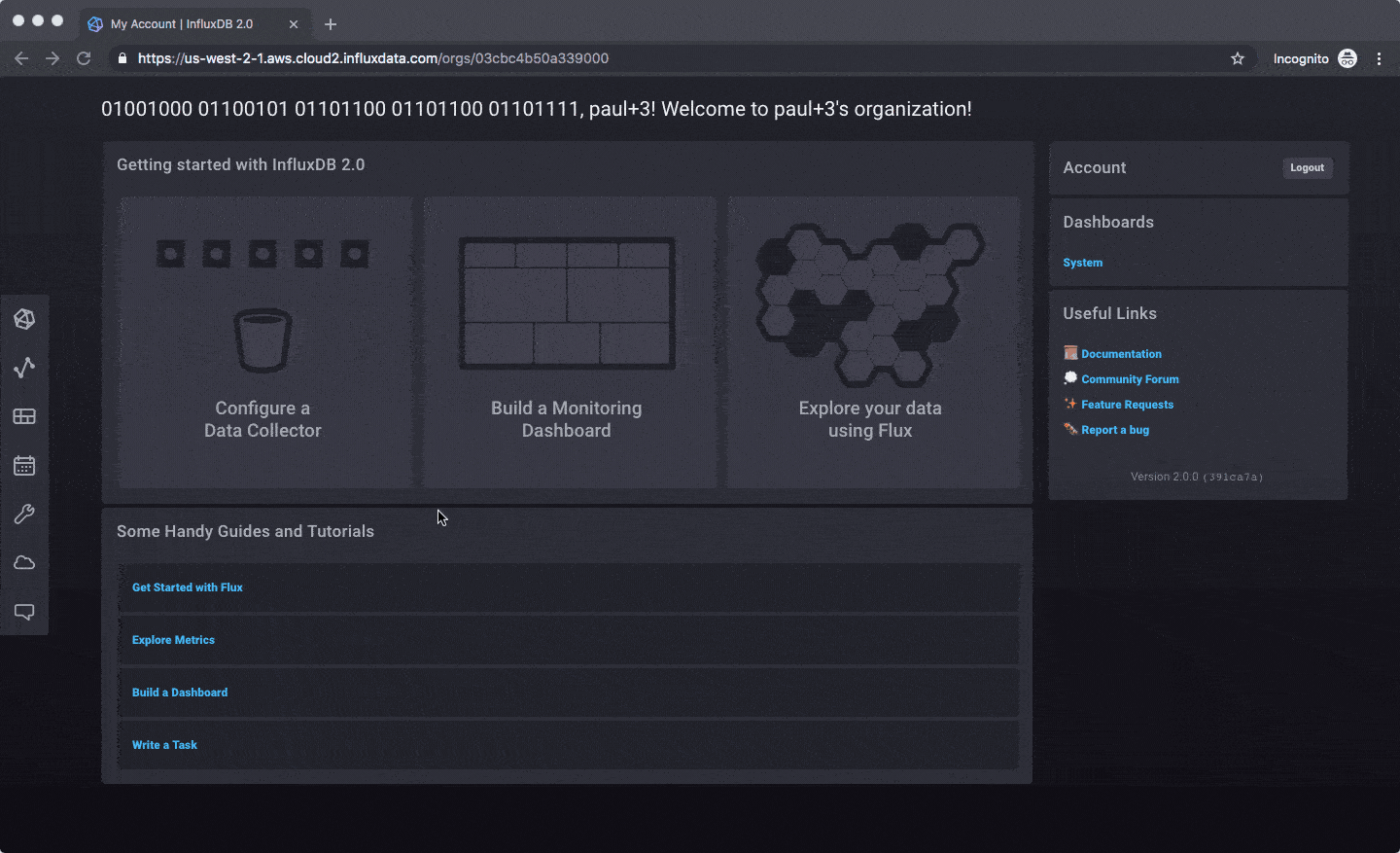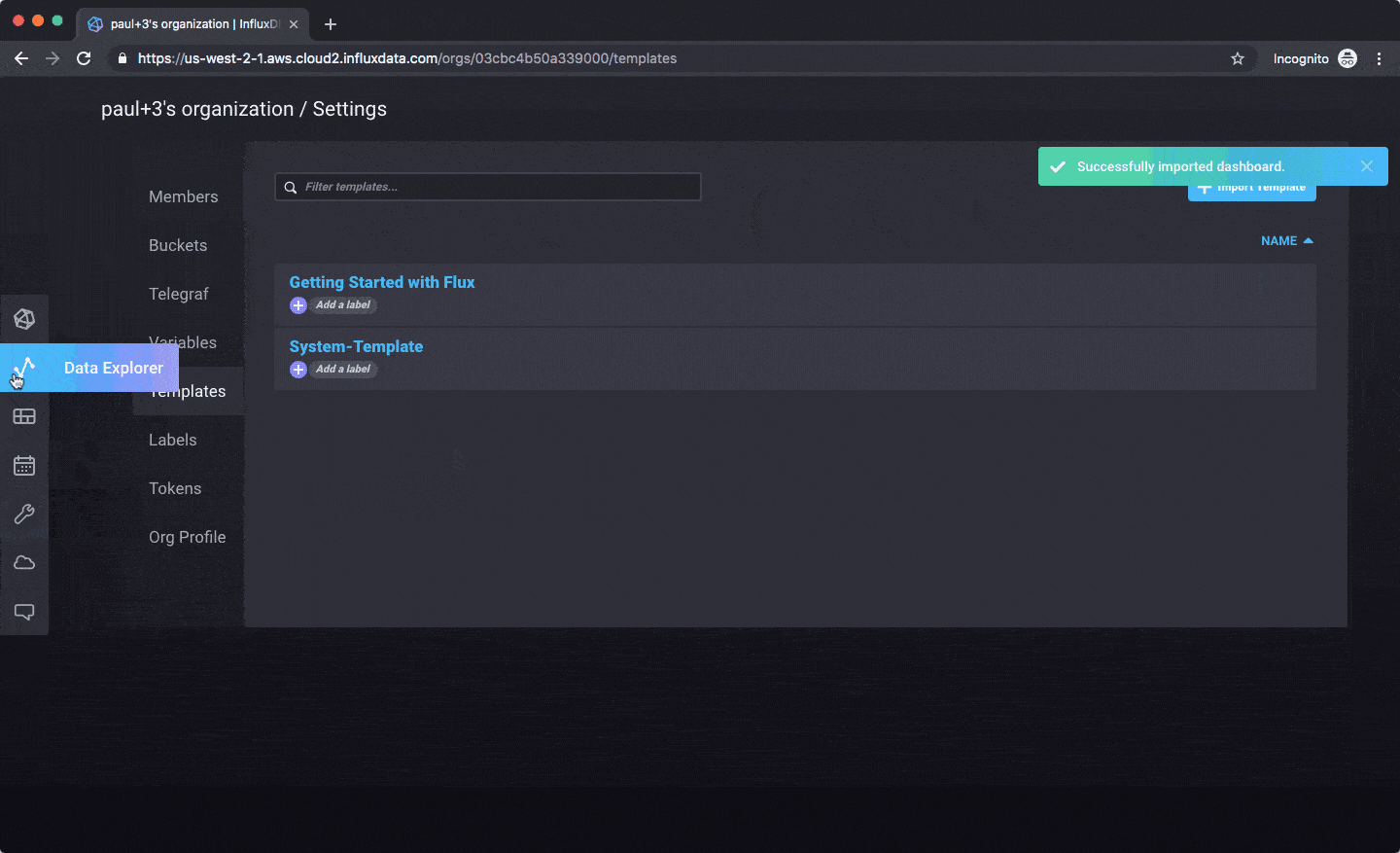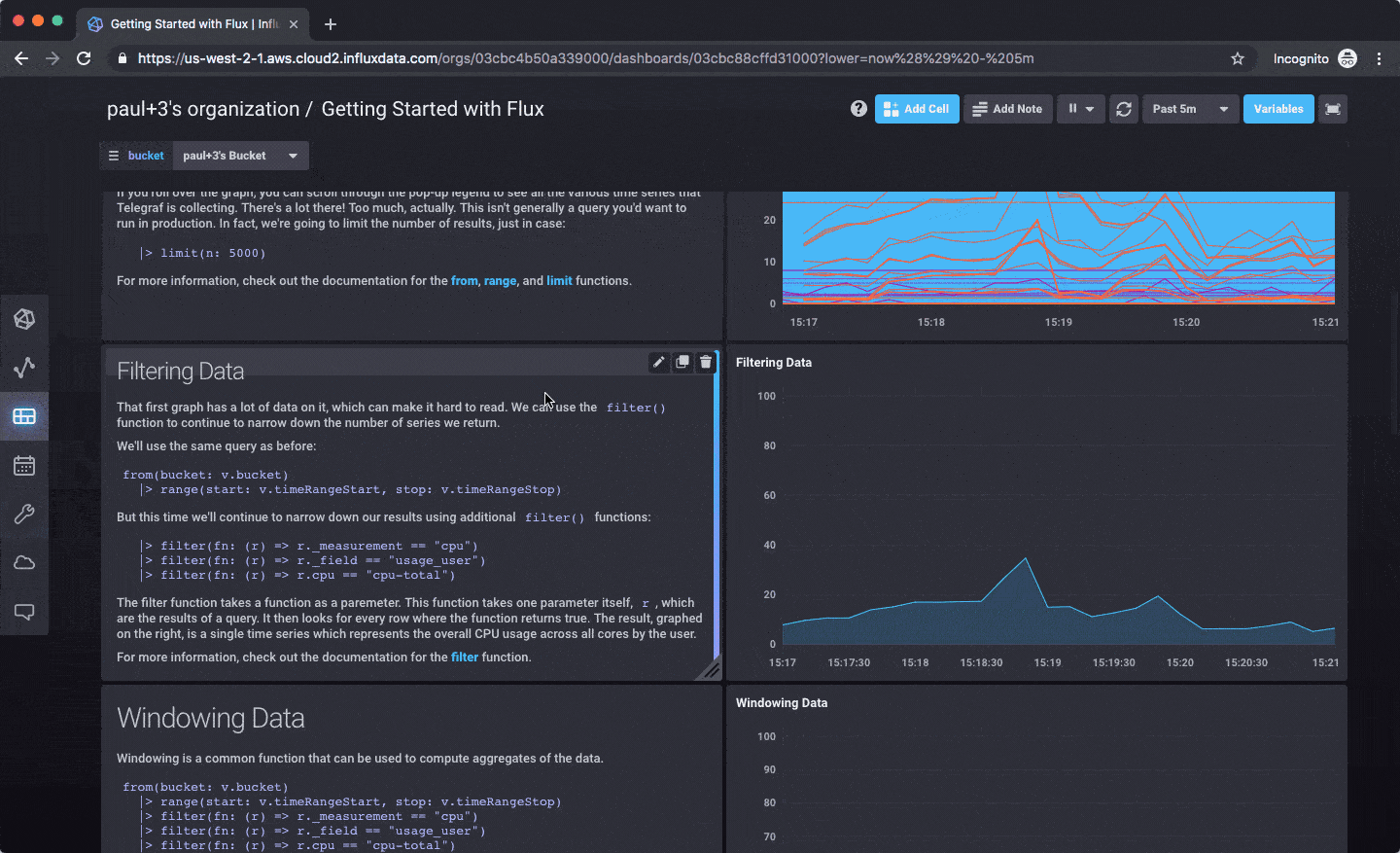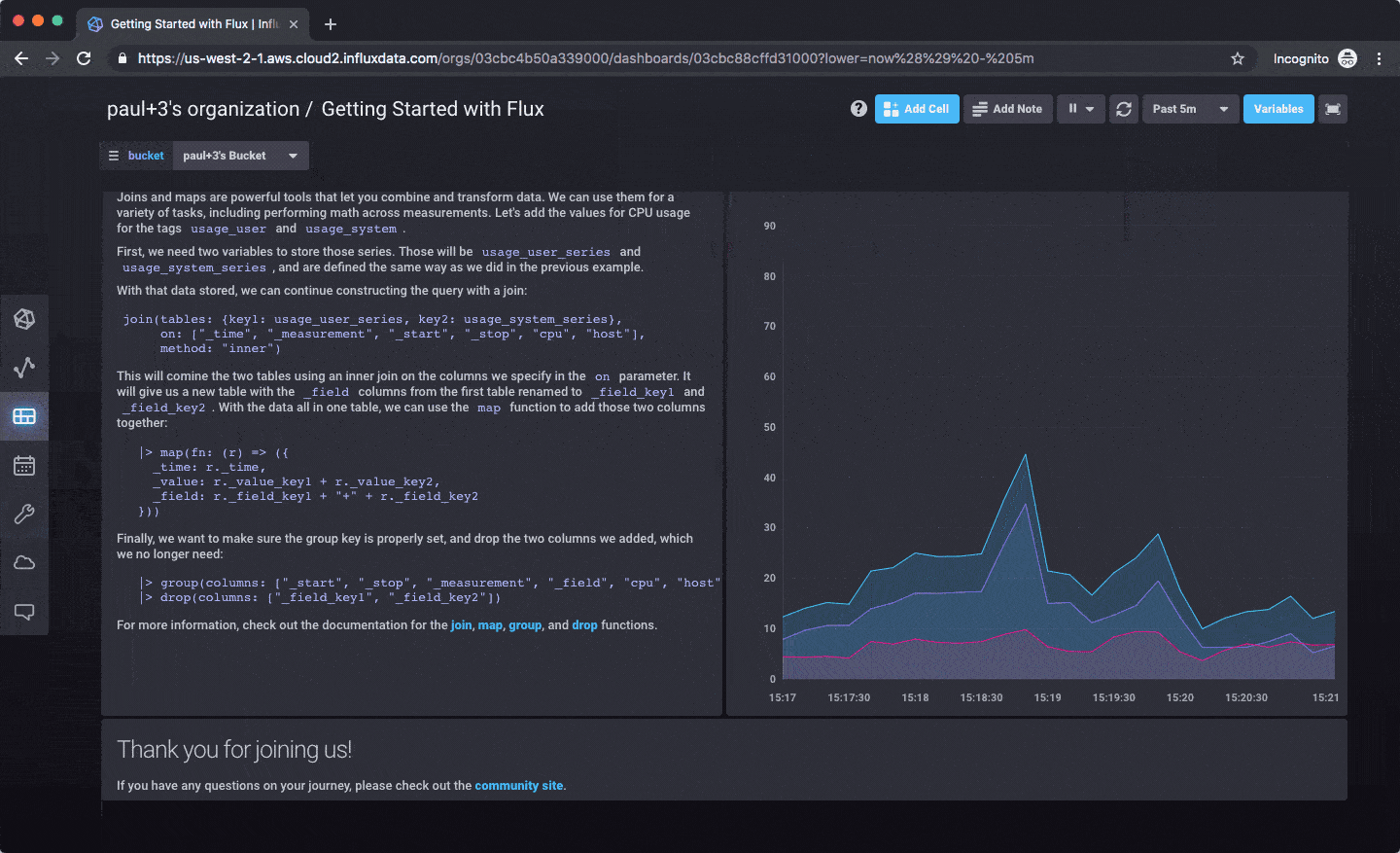
There’s also a great introduction to working with Flux that is included as a template:
Coming soon
We still have a ton of work to do and we’ll be shipping in the cloud regularly. We’ll continue our weekly cadence of shipping OSS alpha releases while shipping in the cloud more frequently. Here are some of the big things we’ll be launching in the coming weeks and months.
We’ll be finishing some big Flux language features. We’ll be adding flow control, recursive functions, loading configuration secrets, and connectors to third-party APIs like PagerDuty, Slack, and SMTP. We’ll also be adding user-defined packages and imports and a public package repository (like NPM, Rubygems, or Cargo). These features paired with the Tasks feature will turn InfluxDB Cloud 2.0 into a full monitoring, ETL, and serverless platform for Flux. Tasks can be run periodically on a schedule, which could be as little as once a second, or for longer reporting things like once a day or once a week.
In the UI we’ll be adding features that will make configuring basic monitoring and alerting rules possible. Under the covers this will use Flux Tasks, but users won’t need to be aware of that. They can simply point and click their way through data explorer and then create rules for what alert conditions to look out for and who and when to notify on those conditions. We’ll also be bringing back the log viewer from Chronograf, revising it, and make it a more general-purpose event viewer.
Usage-based pricing
InfluxDB Cloud 2.0 will offer usage-based pricing. We’re using the beta period to nail down specific details and we’d like to work with our users to see what kind of needs they have. Broadly it will be priced based on:
- Bytes written to the API
- Bytes sent from the API (queries)
- Flux compute time
- Storage hours
The first three items on the list are fairly straightforward counters. You pay for what you write, read, and for how much CPU time your Flux scripts and queries take. Since Flux is a general-purpose programming language, it makes more sense to price usage on time rather than a per query basis. But as we improve the performance of the underlying query planner, optimizer and engine, your costs will go down.
Storage hours are based on how much of your data is stored in our system on an hour-to-hour basis. Once an hour we’ll check how much data is there. Older data will have the advantage of being compacted and have better compression. Because we’re a time series platform, the storage can vary quite a bit from hour to hour, which is why we’re pricing it this way rather than monthly.
We want your feedback!
We’d love to hear from you about the user experience, the client libraries, the pricing model, what features you’d like to see, and what languages you’d like to see supported next. Go here to sign up for free and explore your data within minutes. Or go here to see the getting started guide.
Please reach out to me on Twitter (@pauldix), or if you submit this post to HN I’ll jump in the comments there. Thanks!
