Compactor: A Hidden Engine of Database Performance
By
Paul Dix /
Nga Tran
updated September 08, 2023
Developer
Navigate to:
This article was originally published in InfoWorld and is reposted here with permission.
The compactor handles critical post-ingestion and pre-query workloads in the background on a separate server, enabling low latency for data ingestion and high performance for queries.
The demand for high volumes of data has increased the need for databases that can handle both data ingestion and querying with the lowest possible latency (aka high performance). To meet this demand, database designs have shifted to prioritize minimal work during ingestion and querying, with other tasks being performed in the background as post-ingestion and pre-query.
This article will describe those tasks and how to run them in a completely different server to avoid sharing resources (CPU and memory) with servers that handle data loading and reading.
Tasks of post-ingestion and pre-query
The tasks that can proceed after the completion of data ingestion and before the start of data reading will differ depending on the design and features of a database. In this post, we describe the three most common of these tasks: data file merging, delete application, and data deduplication.
Data file merging
Query performance is an important goal of most databases, and good query performance requires data to be well organized, such as sorted and encoded (aka compressed) or indexed. Because query processing can handle encoded data without decoding it, and the less I/O a query needs to read the faster it runs, encoding a large amount of data into a few large files is clearly beneficial. In a traditional database, the process that organizes data into large files is performed during load time by merging ingesting data with existing data. Sorting and encoding or indexing are also needed during this data organization. Hence, for the rest of this article, we’ll discuss the sort, encode, and index operations hand in hand with the file merge operation.
Fast ingestion has become more and more critical to handling large and continuous flows of incoming data and near real-time queries. To support fast performance for both data ingesting and querying, newly ingested data is not merged with the existing data at load time but stored in a small file (or small chunk in memory in the case of a database that only supports in-memory data). The file merge is performed in the background as a post-ingestion and pre-query task.
A variation of LSM tree (log-structured merge-tree) technique is usually used to merge them. With this technique, the small file that stores the newly ingested data should be organized (e.g. sorted and encoded) the same as other existing data files, but because it is a small set of data, the process to sort and encode that file is trivial. The reason to have all files organized the same will be explained in the section on data compaction below.
Refer to this article on data partitioning for examples of data-merging benefits.
Delete application
Similarly, the process of data deletion and update needs the data to be reorganized and takes time, especially for large historical datasets. To avoid this cost, data is not actually deleted when a delete is issued but a tombstone is added into the system to ‘mark’ the data as ‘soft deleted’. The actual delete is called ‘hard delete’ and will be done in the background.
Updating data is often implemented as a delete followed by an insert, and hence, its process and background tasks will be the ones of the data ingestion and deletion.
Data deduplication
Time series databases such as InfluxDB accept ingesting the same data more than once but then apply deduplication to return non-duplicate results. Specific examples of deduplication applications can be found in this article on deduplication. Like the process of data file merging and deletion, the deduplication will need to reorganize data and thus is an ideal task for performing in the background.
Data compaction
The background tasks of post-ingestion and pre-query are commonly known as data compaction because the output of these tasks typically contains less data and is more compressed. Strictly speaking, the “compaction” is a background loop that finds the data suitable for compaction and then compacts it. However, because there are many related tasks as described above, and because these tasks usually touch the same data set, the compaction process performs all of these tasks in the same query plan. This query plan scans data, finds rows to delete and deduplicate, and then encodes and indexes them as needed.
Figure 1 shows a query plan that compacts two files. A query plan in the database is usually executed in a streaming/pipelining fashion from the bottom up, and each box in the figure represents an execution operator. First, data of each file is scanned concurrently. Then tombstones are applied to filter deleted data. Next, the data is sorted on the primary key (aka deduplication key), producing a set of columns before going through the deduplication step that applies a merge algorithm to eliminate duplicates on the primary key. The output is then encoded and indexed if needed and stored back in one compacted file. When the compacted data is stored, the metadata of File 1 and File 2 stored in the database catalog can be updated to point to the newly compacted data file and then File 1 and File 2 can be safely removed. The task to remove files after they are compacted is usually performed by the database’s garbage collector, which is beyond the scope of this article.
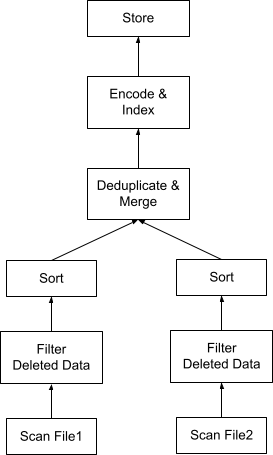
Even though the compaction plan in Figure 1 combines all three tasks in one scan of the data and avoids reading the same set of data three times, the plan operators such as filter and sort are still not cheap. Let us see whether we can avoid or optimize these operators further.
Optimized compaction plan
Figure 2 shows the optimized version of the plan in Figure 1. There are two major changes:
- The operator Filter Deleted Data is pushed into the Scan operator. This is an effective predicate-push-down way to filter data while scanning.
- We no longer need the Sort operator because the input data files are already sorted on the primary key during data ingestion. The Deduplicate & Merge operator is implemented to keep its output data sorted on the same key as its inputs. Thus, the compacting data is also sorted on the primary key for future compaction if needed.
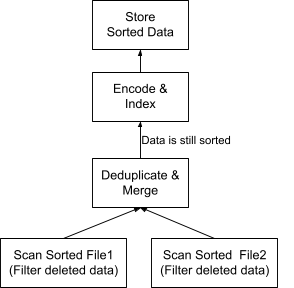
Note that, if the two input files contain data of different columns, which is common in some databases such as InfluxDB, we will need to keep their sort order compatible to avoid doing a re-sort. For example, let’s say the primary key contains columns a, b, c, d, but File 1 includes only columns a, c, d (as well as other columns that are not a part of the primary key) and is sorted on a, c, d. If the data of File 2 is ingested after File 1 and includes columns a, b, c, d, then its sort order must be compatible with File 1’s sort order a, c, d. This means column b could be placed anywhere in the sort order, but c must be placed after a and d must be placed after c. For implementation consistency, the new column, b, could always be added as the last column in the sort order. Thus the sort order of File 2 would be a, c, d, b.
Another reason to keep the data sorted is that, in a column-stored format such as Parquet and ORC, encoding works well with sorted data. For the common RLE encoding, the lower the cardinality (i.e., the lower the number of distinct values), the better the encoding. Hence, putting the lower-cardinality columns first in the sort order of the primary key will not only help compress data more on disk but more importantly help the query plan to execute faster. This is because the data is kept encoded during execution, as described in this paper on materialization strategies.
Compaction levels
To avoid the expensive deduplication operation, we want to manage the data files in a way that we know whether they potentially share duplicate data with other files or not. This can be done by using the technique of data overlapping. To simplify the examples of the rest of this article, we will assume that the data sets are time series in which data overlapping means that their data overlap on time. However, the overlap technique could be defined on non-time series data, too.
One of the strategies to avoid recompacting well-compacted files is to define levels for the files. Level 0 represents newly ingested small files and Level 1 represents compacted, non-overlapping files. Figure 3 shows an example of files and their levels before and after the first and second rounds of compaction. Before any compaction, all of the files are Level 0 and they potentially overlap in time in arbitrary ways. After the first compaction, many small Level 0 files have been compacted into two large, non-overlapped Level 1 files. In the meantime (remember this is a background process), more small Level 0 files have been loaded in, and these kick-start a second round of compaction that compacts the newly ingested Level 0 files into the second Level 1 file. Given our strategy to keep Level 1 files always non-overlapped, we do not need to recompact Level 1 files if they do not overlap with any newly ingested Level 0 files.
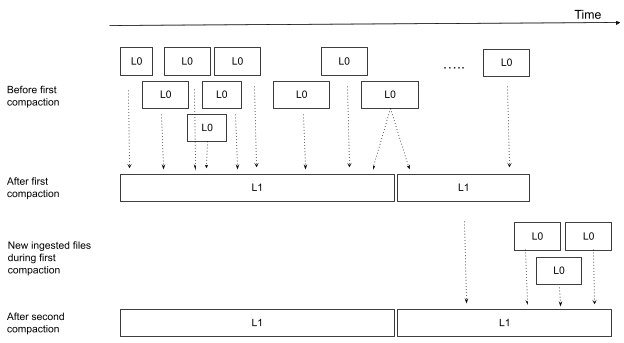
If we want to add different levels of file size, more compaction levels (2, 3, 4, etc.) could be added. Note that, while files of different levels may overlap, no files should overlap with other files in the same level.
We should try to avoid deduplication as much as possible, because the deduplication operator is expensive. Deduplication is especially expensive when the primary key includes many columns that need to be kept sorted. Building fast and memory efficient multi-column sorts is critically important. Some common techniques to do so are described here and here.
Data querying
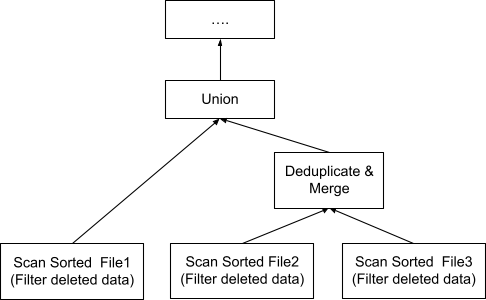
The system that supports data compaction needs to know how to handle a mixture of compacted and not-yet-compacted data. Figure 4 illustrates three files that a query needs to read. File 1 and File 2 are Level 1 files. File 3 is a Level 0 file that overlaps with File 2.

Figure 5 illustrates a query plan that scans those three files. Because File 2 and File 3 overlap, they need to go through the Deduplicate & Merge operator. File 1 does not overlap with any file and only needs to be unioned with the output of the deduplication. Then all unioned data will go through the usual operators that the query plan has to process. As we can see, the more compacted and non-overlapped files can be produced during compaction as pre-query processing, the less deduplication work the query has to perform.
Isolated and hidden compactors
Since data compaction includes only post-ingestion and pre-query background tasks, we can perform them using a completely hidden and isolated server called a compactor. More specifically, data ingestion, queries, and compaction can be processed using three respective sets of servers: integers, queriers, and compactors that do not share resources at all. They only need to connect to the same catalog and storage (often cloud-based object storage), and follow the same protocol to read, write, and organize data.
Because a compactor does not share resources with other database servers, it can be implemented to handle compacting many tables (or even many partitions of a table) concurrently. In addition, if there are many tables and data files to compact, several compactors can be provisioned to independently compact these different tables or partitions in parallel.
Furthermore, if compaction requires significantly less resources than ingestion or querying, then the separation of servers will improve the efficiency of the system. That is, the system could draw on many ingestors and queriers to handle large ingesting workloads and queries in parallel respectively, while only needing one compactor to handle all of the background post-ingestion and pre-querying work. Similarly, if the compaction needs a lot more resources, a system of many compactors, one ingestor, and one querier could be provisioned to meet the demand.
A well-known challenge in databases is how to manage the resources of their servers — the ingestors, queriers, and compactors — to maximize their utilization of resources (CPU and memory) while never hitting out-of-memory incidents. It is a large topic and deserves its own blog post.
Compaction is a critical background task that enables low latency for data ingestion and high performance for queries. The use of shared, cloud-based object storage has allowed database systems to leverage multiple servers to handle data ingestion, querying, and compacting workloads independently. For more information about the implementation of such a system, check out InfluxDB IOx. Other related techniques needed to design the system can be found in our companion articles on sharding and partitioning.
