Table of Contents
We believe that querying data in Apache Parquet files directly can achieve similar or better storage efficiency and query performance than most specialized file formats. While it requires significant engineering effort, the benefits of Parquet’s open format and broad ecosystem support make it the obvious choice for a wide class of data systems.
In this article we explain several advanced techniques needed to query data stored in the Parquet format quickly that we implemented in the Apache Arrow Rust Parquet reader. Together these techniques make the Rust implementation one of, if not the, fastest implementation for querying Parquet files — be it on local disk or remote object storage. It is able to query GBs of Parquet in a matter of milliseconds.
Background
Apache Parquet is an increasingly popular open format for storing analytic datasets, and has become the de-facto standard for cost-effective, DBMS-agnostic data storage. Initially created for the Hadoop ecosystem, Parquet’s reach now expands broadly across the data analytics ecosystem due to its compelling combination of:
- High compression ratios
- Amenability to commodity blob-storage such as S3
- Broad ecosystem and tooling support
- Portability across many different platforms and tools
- Support for arbitrarily structured data
Increasingly other systems, such as DuckDB and Redshift allow querying data stored in Parquet directly, but support is still often a secondary consideration compared to their native (custom) file formats. Such formats include the DuckDB .duckdb file format, the Apache IOT TsFile, the Gorilla format, and others.
For the first time, access to the same sophisticated query techniques, previously only available in closed source commercial implementations, are now available as open source. The required engineering capacity comes from large, well-run open source projects with global contributor communities, such as Apache Arrow and Apache Impala.
Parquet file format
Before diving into the details of efficiently reading from Parquet, it is important to understand the file layout. The file format is carefully designed to quickly locate the desired information, skip irrelevant portions, and decode what remains efficiently.
- The data in a Parquet file is broken into horizontal slices called RowGroups
- Each RowGroup contains a single ColumnChunk for each column in the schema
For example, the following diagram illustrates a Parquet file with three columns “A”, “B” and “C” stored in two RowGroups for a total of 6 ColumnChunks.

The logical values for a ColumnChunk are written using one of the many available encodings into one or more Data Pages appended sequentially in the file. At the end of a Parquet file is a footer, which contains important metadata, such as:
- The file’s schema information such as column names and types
- The locations of the RowGroup and ColumnChunks in the file The footer may also contain other specialized data structures:
- Optional statistics for each ColumnChunk including min/max values and null counts
- Optional pointers to OffsetIndexes containing the location of each individual Page
- Optional pointers to ColumnIndex containing row counts and summary statistics for each Page
- Optional pointers to BloomFilterData, which can quickly check if a value is present in a ColumnChunk
For example, the logical structure of 2 Row Groups and 6 ColumnChunks in the previous diagram might be stored in a Parquet file as shown in the following diagram (not to scale). The pages for the ColumnChunks come first, followed by the footer. The data, the effectiveness of the encoding scheme, and the settings of the Parquet encoder determine the number of and size of the pages needed for each ColumnChunk. In this case, ColumnChunk 1 required 2 pages while ColumnChunk 6 required only 1 page. In addition to other information, the footer contains the locations of each Data Page and the types of the columns.

There are many important criteria to consider when creating Parquet files such as how to optimally order/cluster data and structure it into RowGroups and Data Pages. Such “physical design” considerations are complex, worthy of their own series of articles, and not addressed in this blog post. Instead, we focus on how to use the available structure to make queries very fast.
Optimizing queries
In any query processing system, the following techniques generally improve performance:
- Reduce the data that must be transferred from secondary storage for processing (reduce I/O)
- Reduce the computational load for decoding the data (reduce CPU)
- Interleave/pipeline the reading and decoding of the data (improve parallelism)
The same principles apply to querying Parquet files, as we describe below:
Decode optimization
Parquet achieves impressive compression ratios by using sophisticated encoding techniques such as run length compression, dictionary encoding, delta encoding, and others. Consequently, the CPU-bound task of decoding can dominate query latency. Parquet readers can use a number of techniques to improve the latency and throughput of this task, as we have done in the Rust implementation.
Vectorized decode
Most analytic systems decode multiple values at a time to a columnar memory format, such as Apache Arrow, rather than processing data row-by-row. This is often called vectorized or columnar processing, and is beneficial because it:
- Amortizes dispatch overheads to switch on the type of column being decoded
- Improves cache locality by reading consecutive values from a ColumnChunk
- Often allows multiple values to be decoded in a single instruction.
- Avoid many small heap allocations with a single large allocation, yielding significant savings for variable length types such as strings and byte arrays
Thus, Rust Parquet Reader implements specialized decoders for reading Parquet directly into a columnar memory format (Arrow Arrays).
Streaming decode
There is no relationship between which rows are stored in which Pages across ColumnChunks. For example, the logical values for the 10,000th row may be in the first page of column A and in the third page of column B.
The simplest approach to vectorized decoding, and the one often initially implemented in Parquet decoders, is to decode an entire RowGroup (or ColumnChunk) at a time.
However, given Parquet’s high compression ratios, a single RowGroup may well contain millions of rows. Decoding so many rows at once is non-optimal because it:
- Requires large amounts of intermediate RAM: typical in-memory formats optimized for processing, such as Apache Arrow, require much more than their Parquet-encoded form.
- Increases query latency: Subsequent processing steps (like filtering or aggregation) can only begin once the entire RowGroup (or ColumnChunk) is decoded.
As such, the best Parquet readers support “streaming” data out in by producing configurable sized batches of rows on demand. The batch size must be large enough to amortize decode overhead, but small enough for efficient memory usage and to allow downstream processing to begin concurrently while the subsequent batch is decoded.
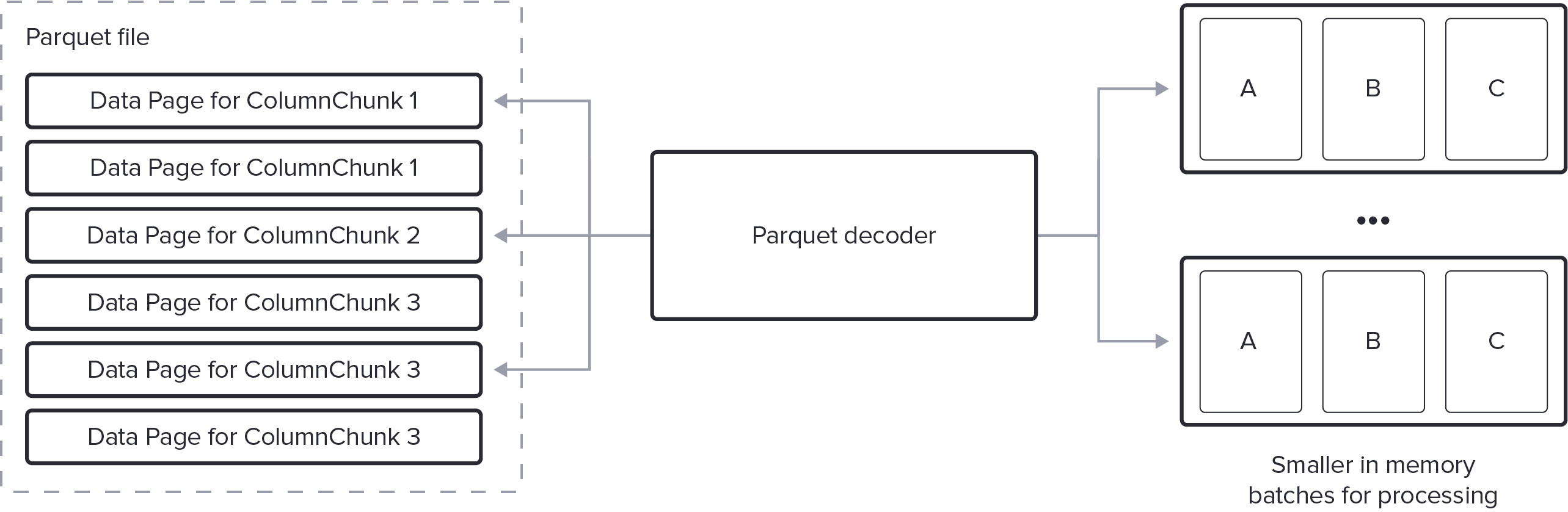
While streaming is not a complicated feature to explain, the stateful nature of decoding, especially across multiple columns and arbitrarily nested data, where the relationship between rows and values is not fixed, requires complex intermediate buffering and significant engineering effort to handle correctly.
Dictionary preservation
Dictionary Encoding, also called categorical encoding, is a technique where each value in a column is not stored directly, but instead, an index in a separate list called a “Dictionary” is stored. This technique achieves many of the benefits of third normal form for columns that have repeated values (low cardinality) and is especially effective for columns of strings such as “City”.
The first page in a ColumnChunk can optionally be a dictionary page, containing a list of values of the column’s type. Subsequent pages within this ColumnChunk can then encode an index into this dictionary, instead of encoding the values directly.
Given the effectiveness of this encoding, if a Parquet decoder simply decodes dictionary data into the native type, it will inefficiently replicate the same value over and over again, which is especially disastrous for string data. To handle dictionary-encoded data efficiently, the encoding must be preserved during decode. Conveniently, many columnar formats, such as the Arrow DictionaryArray, support such compatible encodings.
Preserving dictionary encoding drastically improves performance when reading to an Arrow array, in some cases in excess of 60x, as well as using significantly less memory.
The major complicating factor for preserving dictionaries is that the dictionaries are stored per ColumnChunk, and therefore the dictionary changes between RowGroups. The reader must automatically recompute a dictionary for batches that span multiple RowGroups, while also optimizing for the case that batch sizes divide evenly into the number of rows per RowGroup. Additionally a column may be only partly dictionary encoded, further complicating implementation. More information on this technique and its complications can be found in the blog post on applying this technique to the C++ Parquet reader.
Projection pushdown
The most basic Parquet optimization, and the one most commonly described for Parquet files, is projection pushdown, which reduces both I/Oand CPU requirements. Projection in this context means “selecting some but not all of the columns.” Given how Parquet organizes data, it is straightforward to read and decode only the ColumnChunks required for the referenced columns.
For example, consider a SQL query of the form
SELECT B from table where A > 35
This query only needs data for columns A and B (and not C) and the projection can be “pushed down” to the Parquet reader.
Specifically, using the information in the footer, the Parquet reader can entirely skip fetching (I/O) and decoding (CPU) the Data Pages that store data for column C (ColumnChunk 3 and ColumnChunk 6 in our example).

Predicate pushdown
Similar to projection pushdown, predicate pushdown also avoids fetching and decoding data from Parquet files, but does so using filter expressions. This technique typically requires closer integration with a query engine such as DataFusion, to determine valid predicates and evaluate them during the scan. Unfortunately without careful API design, the Parquet decoder and query engine can end up tightly coupled, preventing reuse (e.g. there are different Impala and Spark implementations in Cloudera Parquet Predicate Pushdown docs). The Rust Parquet reader uses the RowSelection API to avoid this coupling.
RowGroup pruning
The simplest form of predicate pushdown, supported by many Parquet based query engines, uses the statistics stored in the footer to skip entire RowGroups. We call this operation RowGroup pruning, and it is analogous to partition pruning in many classical data warehouse systems.
For the example query above, if the maximum value for A in a particular RowGroup is less than 35, the decoder can skip fetching and decoding any ColumnChunks from that entire RowGroup.
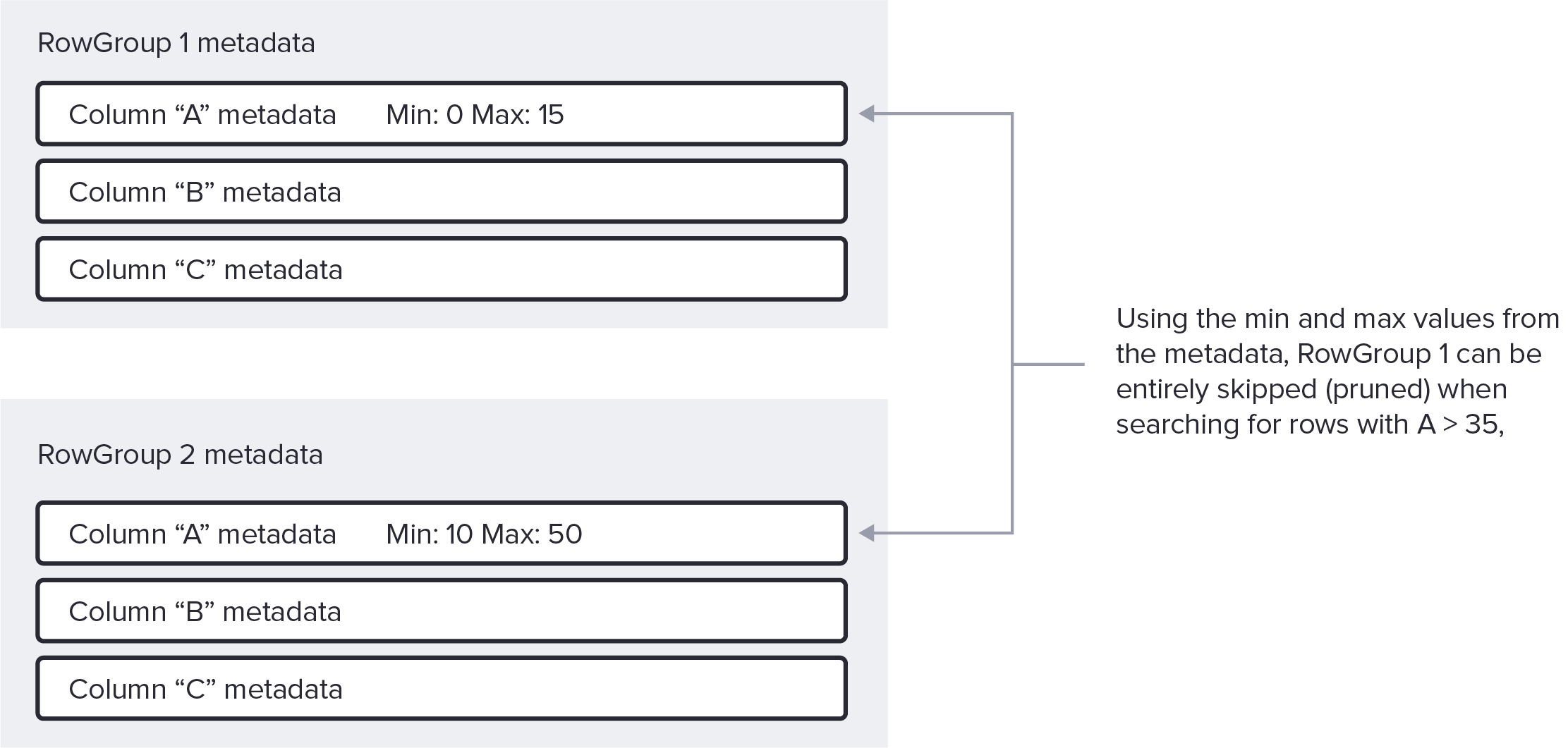
Note that pruning on minimum and maximum values is effective for many data layouts and column types, but not all. Specifically, it is not as effective for columns with many distinct pseudo-random values (e.g. identifiers or uuids). Thankfully for this use case, Parquet also supports per ColumnChunk Bloom Filters. We are actively working on adding bloom filter support in Apache Rust’s implementation.
Page pruning
A more sophisticated form of predicate pushdown uses the optional page index in the footer metadata to rule out entire Data Pages. The decoder decodes only the corresponding rows from other columns, often skipping entire pages.
The fact that pages in different ColumnChunks often contain different numbers of rows, due to various reasons, complicates this optimization. While the page index may identify the needed pages from one column, pruning a page from one column doesn’t immediately rule out entire pages in other columns.
Page pruning proceeds as follows:
- Uses the predicates in combination with the page index to identify pages to skip
- Uses the offset index to determine what row ranges correspond to non-skipped pages
- Computes the intersection of ranges across non-skipped pages, and decodes only those rows
This last point is highly non-trivial to implement, especially for nested lists where a single row may correspond to multiple values. Fortunately, the Rust Parquet reader hides this complexity internally, and can decode arbitrary RowSelections.
For example, to scan Columns A and B, stored in 5 Data Pages as shown in the figure below:
If the predicate is A > 35,
- Page 1 is pruned using the page index (max value is 20), leaving a RowSelection of [200->onwards],
- Parquet reader skips Page 3 entirely (as its last row index is 99)
- (Only) the relevant rows are read by reading pages 2, 4, and 5.
If the predicate is instead A > 35 AND B = “F” the page index is even more effective
- Using A > 35, yields a RowSelection of [200->onwards] as before
- Using B = “F”, on the remaining Page 4 and Page 5 of B, yields a RowSelection of [100-244]
- Intersecting the two RowSelections leaves a combined RowSelection [200-244]
- Parquet reader only decodes those 50 rows from Page 2 and Page 4.

Support for reading and writing these indexes from Arrow C++, and by extension pyarrow/pandas, is tracked in PARQUET-1404.
Late materialization
The two previous forms of predicate pushdown only operated on metadata stored for RowGroups, ColumnChunks, and Data Pages prior to decoding values. However, the same techniques also extend to values of one or more columns after decoding them but prior to decoding other columns, which is often called “late materialization”.
This technique is especially effective when:
- The predicate is very selective, i.e. filters out large numbers of rows
- Each row is large, either due to wide rows (e.g. JSON blobs) or many columns
- The selected data is clustered together
- The columns required by the predicate are relatively inexpensive to decode, e.g. PrimitiveArray / DictionaryArray
There is additional discussion about the benefits of this technique in SPARK-36527 and Impala.
For example, given the predicate A > 35 AND B = “F” from above where the engine uses the page index to determine only 50 rows within RowSelection of [100-244] could match, using late materialization, the Parquet decoder:
- Decodes the 50 values of Column A
- Evaluates A > 35 on those 50 values
- In this case, only 5 rows pass, resulting in the RowSelection:
- RowSelection[205-206]
- RowSelection[238-240]
- Only decodes the 5 rows for column B for those selections

In certain cases, such as our example where B stores single character values, the cost of late materialization machinery can outweigh the savings in decoding. However, the savings can be substantial when some of the conditions listed above are fulfilled. The query engine must decide which predicates to push down and in which order to apply them for optimal results.
While it is outside the scope of this document, the same technique can be applied for multiple predicates as well as predicates on multiple columns. See the RowFilter interface in the Parquet crate for more information, and the row_filter implementation in DataFusion.
I/O pushdown
While Parquet was designed for efficient access on the HDFS distributed file system, it works very well with commodity blob storage systems such as AWS S3 as they have very similar characteristics:
- Relatively slow “random access” reads: it is much more efficient to read large (MBs) sections of data in each request than issue many requests for smaller portions
- Significant latency before retrieving the first byte
- High per-request cost: Often billed per request, regardless of number of bytes read, which incentivizes fewer requests that each read a large contiguous section of data.
To read optimally from such systems, a Parquet reader must:
- Minimize the number of I/O requests, while also applying the various pushdown techniques to avoid fetching large amounts of unused data.
- Integrate with the appropriate task scheduling mechanism to interleave I/O and processing on the data that is fetched to avoid pipeline bottlenecks.
As these are substantial engineering and integration challenges, many Parquet readers still require the files to be fetched in their entirety to local storage.
Fetching the entire files in order to process them is not ideal for several reasons:
- High Latency: Decoding cannot begin until the entire file is fetched (Parquet metadata is at the end of the file, so the decoder must see the end prior to decoding the rest)
- Wasted work: Fetching the entire file fetches all necessary data, but also potentially lots of unnecessary data that will be skipped after reading the footer. This increases the cost unnecessarily.
- Requires costly “locally attached” storage (or memory): Many cloud environments do not offer computing resources with locally attached storage – they either rely on expensive network block storage such as AWS EBS or else restrict local storage to certain classes of VMs.
Avoiding the need to buffer the entire file requires a sophisticated Parquet decoder, integrated with the I/O subsystem, that can initially fetch and decode the metadata followed by ranged fetches for the relevant data blocks, interleaved with the decoding of Parquet data. This optimization requires careful engineering to fetch large enough blocks of data from the object store that the per request overhead doesn’t dominate gains from reducing the bytes transferred. SPARK-36529 describes the challenges of sequential processing in more detail.
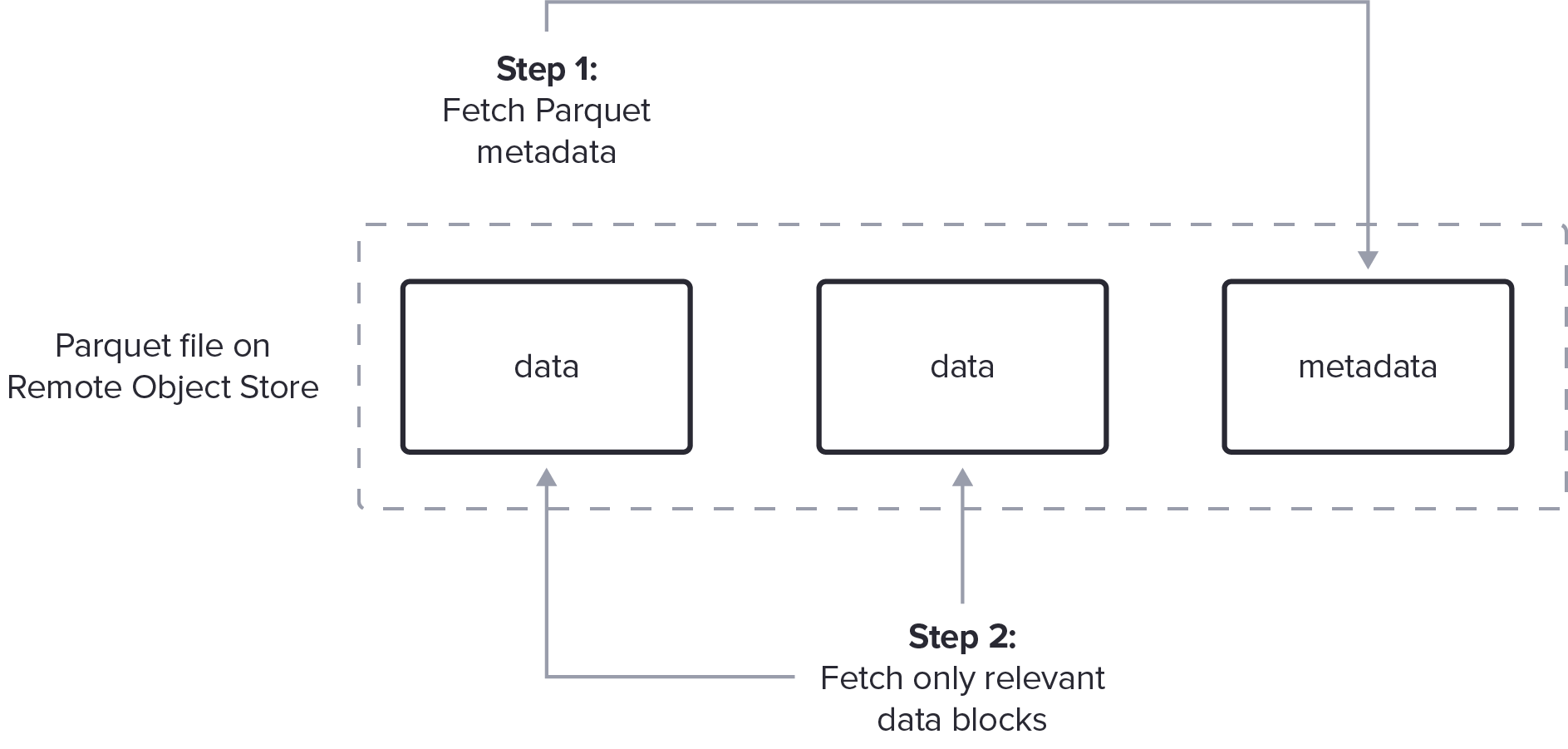
Not included in this diagram picture are details like coalescing requests and ensuring minimum request sizes needed for an actual implementation.
The Rust Parquet crate provides an async Parquet reader, to efficiently read from any AsyncFileReader that:
- Efficiently reads from any storage medium that supports range requests
- Integrates with Rust’s futures ecosystem to avoid blocking threads waiting on network I/O and easily can interleave CPU and network
- Requests multiple ranges simultaneously, to allow the implementation to coalesce adjacent ranges, fetch ranges in parallel, etc.
- Uses the pushdown techniques described previously to eliminate fetching data where possible
- Integrates easily with the Apache Arrow object_store crate which you can read more about here
To give a sense of what is possible, the following picture shows a timeline of fetching the footer metadata from remote files, using that metadata to determine what Data Pages to read, and then fetching data and decoding simultaneously. This process often must be done for more than one file at a time in order to match network latency, bandwidth, and available CPU.
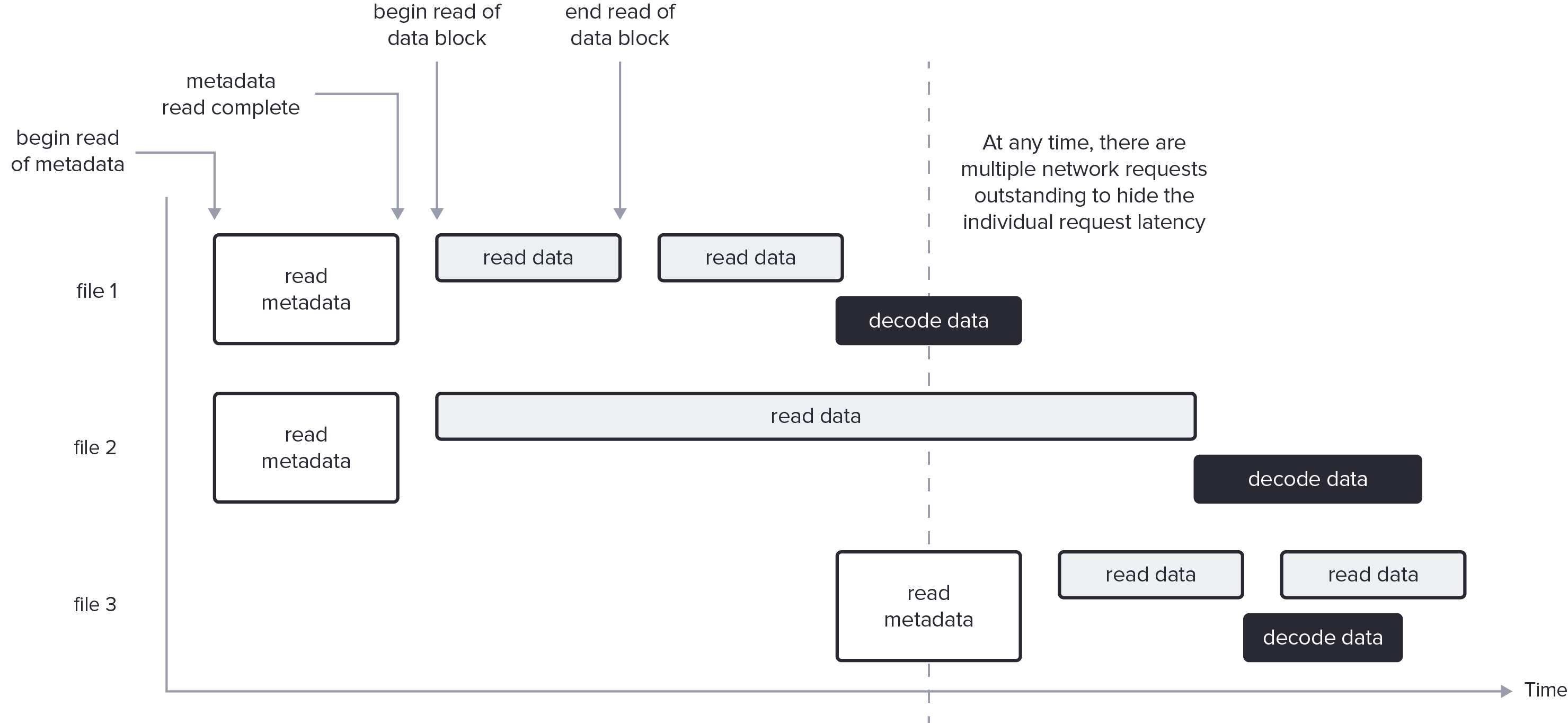
Conclusion
We hope you enjoyed reading about the Parquet file format, and the various techniques used to quickly query parquet files.
We believe that the reason most open source implementations of Parquet do not have the breadth of features described in this post is that it takes a monumental effort, that was previously only possible at well-financed commercial enterprises which kept their implementations closed source.
However, with the growth and quality of the Apache Arrow community, both Rust practitioners and the wider Arrow community, our ability to collaborate and build a cutting-edge open source implementation is exhilarating and immensely satisfying. The technology described in this blog is the result of the contributions of many engineers spread across companies, hobbyists, and the world in several repositories, notably Apache Arrow DataFusion, Apache Arrow and Apache Arrow Ballista.
If you are interested in joining the DataFusion Community, please get in touch.
