Getting Started with JavaScript and InfluxDB 2.0
By
Anais Dotis-Georgiou
updated December 14, 2025
Product
Use Cases
Developer
Navigate to:
With 200+ plugins, Telegraf has a wide variety of methods for scraping, writing, and querying data to and from InfluxDB. However, sometimes users need to perform data collection outside of the capabilities of Telegraf. Perhaps they need to collect custom data and monitor application performance. Maybe they want to take advantage of external tools and libraries to create beautiful web-based visualizations for their users. In these cases, it makes sense to take advantage of InfluxDB’s Client Libraries. Today, we will focus on how to use the latest InfluxDB JavaScript Client Library with InfluxDB 2.0.
Important note: InfluxDB v1.8 includes both the Flux engine for queries and InfluxDB v2 HTTP write APIs as well. This means that if you aren’t quite ready to use InfluxDB v2 today and you are planning to leverage the new client libraries, you can! These read and write compatibility options allow you to future-proof your code!
Tutorial requirements and setup
This tutorial was executed on a MacOS system with Node installed via Homebrew, per the Node.js documentation.
#update brew before installing
brew update
brew install node
#check to make sure you have successfully installed Node and NPM
node -v
npm -vThe easiest way to get started using the InfluxDB v2 JavaScript Client is to clone the examples directory in the influxdb-client-js repo.
Once you have successfully cloned the directory, navigate to it and run:
npm installSpecify your authorization parameters in index.html and env.js. You will need to specify the org, a bucket, and a token. Now we’re ready to start using the client in the browser with:
npm run browserNpm should open http://localhost:3001/examples/index.html where you will be prompted to write a datapoint in line protocol and query it through the UI. You’ll also be able to onboard a user and perform an API health check.
Authorization parameters
InfluxDB v2
In order to use the client, you’ll need to gather the following parameters:
- Bucket Name or ID: Follow this documentation to create a bucket. To view your buckets either use the UI or execute
influx -t <your-token> -o <your-org> bucket find
- Token: Follow this documentation to create a token. To view your tokens either use the UI or execute
influx auth find
- Org: To view your orgs either use the UI or execute
influx org find

InfluxDB v1.8 and above
If you plan to use this new client library with InfluxDB 1.8 or greater, here are some important tips about gathering the required authorization parameters:
- Bucket Name: There is no concept of Bucket in InfluxDB v1.x. However, a bucket is simply the combination of the database name and it's retention policy. So, you can specify this by providing the InfluxDB 1.x database name and retention policy separated by a forward slash (/). If you do not supply a retention policy, the default retention policy is used.
For example: a bucket name of telegraf/1week allows you to write the InfluxDB 1.x database named “telegraf” with a retention policy named “1week”. Similarly, telegraf/ or telegraf allows you to write to the InfluxDB 1.x database named “telegraf” and the default retention policy (typically autogen).
- Token: In InfluxDB v2, API Tokens are used to access the platform and all its capabilities. InfluxDB v1.x uses a username and password combination when accessing the HTTP APIs. Provide your InfluxDB 1.x username and password separated by a colon (:) to represent the token. For example:
username:password
- Org: The org parameter is ignored in compatibility mode with InfluxDB v1.x and can be left empty.
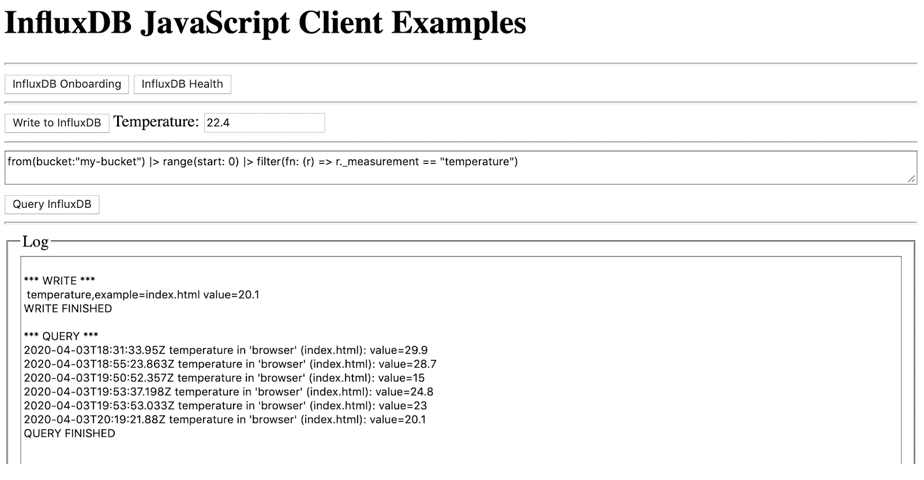
Writing to InfluxDB v2 with the JavaScript Client Library
The point you write in the example demo is hard-coded to include a measurement, tag key, and tag value. The code generates the following line protocol temperature,example=index.html value=28.7 with the following function:
function writeExample(value) {
const writeApi = influxDB.getWriteApi(org, bucket)
// setup default tags for all writes through this API
writeApi.useDefaultTags({location: 'browser'})
log('\n*** WRITE ***')
const point1 = new Point('temperature')
.tag('example', 'index.html')
.floatField('value', value)
writeApi.writePoint(point1)
log(` ${point1}`)
// flush pending writes and close writeApi
writeApi
.close()
.then(() => {
log('WRITE FINISHED')
})
.catch(e => {
log('WRITE FAILED', e)
})
}You provide your org and bucket to the getWriteApi method, which creates a WriteApi. This method also allows you to include a precision parameter to support several timestamp precision, the default is ns precision.
There are several data formatting methods to write line protocol to InfluxDB.
- useDefaultTags method instructs the API to use default tags, defined by the user when writing points.
- writeRecord method takes a single line protocol string.
- writeRecords method takes an array of line protocol strings.
There are two methods to write line protocol data to InfluxDB.
- writePoint supports a single record.
- writePoints supports multiple records.
Querying InfluxDB v2 with the JavaScript Client Library
InfluxDB v2
Now that we’ve written some random temperature data to our InfluxDB instance, we’re ready to query it.
function queryExample(fluxQuery) {
log('\n*** QUERY ***')
const queryApi = influxDB.getQueryApi(org)
queryApi.queryRows(fluxQuery, {
next(row, tableMeta) {
const o = tableMeta.toObject(row)
if (o.example){
// custom output for example query
log(
`${o._time} ${o._measurement} in '${o.location}' (${o.example}): ${o._field}=${o._value}`
)
} else {
// default output
log(JSON.stringify(o, null, 2))
}
},
error(error) {
log('QUERY FAILED', error)
},
complete() {
log('QUERY FINISHED')
},
})
}The getQueryApi method creates a QueryApi for supplied org. The queryRows method performs the query and returns the lines in annotated csv, where console.log(o) yields:
{result: "_result", table: "0", _start: "1970-01-01T00:00:00Z", _stop: "2020-04-03T20:39:23.761184Z", _time: "2020-04-03T18:31:33.95Z",
}
result: "_result"
table: "0"
_start: "1970-01-01T00:00:00Z"
_stop: "2020-04-03T20:39:23.761184Z"
_time: "2020-04-03T18:31:33.95Z"
_value: 29.9
_field: "value"
_measurement: "temperature"
example: "index.html"
location: "browser"
__proto__: ObjectInfluxDB v1.8 or greater
The same example above applies, but the connection URL is different. For the Flux query endpoint, use: http://<hostname>:8086/api/v2/query
Health checks
Monitoring the health of your database instance through your API’s is a critical step in building a pipeline you can trust. This browser example also incorporates a health check:
const {InfluxDB} = require('@influxdata/influxdb-client')
const {HealthAPI} = require('@influxdata/influxdb-client-apis')
const {url, token} = require('./env')
console.log('*** HEALTH CHECK ***')
const influxDB = new InfluxDB({url, token})
const healthAPI = new HealthAPI(influxDB)
healthAPI
.getHealth()
.then((result /* : HealthCheck */) => {
console.log(JSON.stringify(result, null, 2))
console.log('\nFinished SUCCESS')
})
.catch(error => {
console.error(error)
console.log('\nFinished ERROR')
})To get the health of an instance, you need to:
- Create a new InfluxDB object
- Create a HealthAPI from the InfluxDB object
- Use the getHealth method to return the status of the API (see the API documentation for more details)
Onboarding
Finally, this demo includes a user onboarding example. Easy and quick user onboarding enables application developers to provide a low barrier to adoption for users looking to get access to their time series data. In order to implement the onboarding tool, you must provide the user’s username and password to ./env.
const setupApi = new SetupAPI(new InfluxDB({url}))
setupApi
.getSetup()
.then(async ({allowed}) => {
if (allowed) {
await setupApi.postSetup({
body: {
org,
bucket,
username,
password,
token,
},
})
console.log(`InfluxDB '${url}' is now onboarded.`)
} else {
console.log(`InfluxDB '${url}' has been already onboarded.`)
}
console.log('\nFinished SUCCESS')
})
.catch(error => {
console.error(error)
console.log('\nFinished ERROR')
})Similarly to the health check, in order to onboard a new user, you need to:
- Create a new InfluxDB object
- Create a SetupAPI from the InfluxDB object
- Use the getSetup method to set up an initial user, org, and bucket
Final thoughts on the InfluxDB v2 JavaScript Client
It is important to note that Node environments are also supported in addition to browser environments. Also, I want to share some additional resources that might be of value to JavaScript Developers. If you enjoy the InfluxDB UI and want to take advantage of sophisticated time series data visualization algorithms, I recommend checking out Giraffe and Clockface. Giraffe is an open source React-based visualization library used to implement the InfluxDB Cloud 2.0 user interface (UI). Clockface is an open source React and Typescript UI kit for building InfluxDB v2 UI and other time series visualization applications.
I hope this tutorial gets you started on your JavaScript and InfluxDB journey. As always, I’d love to hear your thoughts and answer any of your questions. Please post them on our community site or Slack channel.
